

When we run databases in Kubernetes, we quickly learn one important truth: things will fail, and we need to be prepared for this. Pods are ephemeral; nodes can come and go, storage is abstracted behind PersistentVolumes and can be either local to a node or backed by network storage, and Kubernetes moves workloads as needed through deployments, upgrades, and rollouts.
Because of this, replication is no longer limited to a database setting. It influences how MySQL survives failures, scales, and performs within a dynamic Kubernetes environment where changes happen naturally as the platform manages workloads.
High availability for MySQL running in Kubernetes depends heavily on how the database replicates data across nodes. Replication determines how well MySQL handles failures and how reliably an operator can perform automated failovers. That’s why understanding the difference between virtually synchronous (SYNC) and asynchronous (ASYNC) replication is essential for running MySQL reliably in cloud-native environments.
In simple terms, virtually synchronous replication means that all nodes confirm a write before it is considered successful, ensuring data consistency. On the other hand, asynchronous replication commits the write on the primary first, and replicas catch up afterwards, which improves performance but may introduce minimal lag. These two models define how MySQL clusters behave during failures, updates and scaling events.
If you need a quick refresher on MySQL replication, we recommend Dimitri Vanoverbeke’s article, “An Introduction to MySQL Replication.” It’s a great background before we dive into the cloud-native approach.
Let’s talk about what this means for MySQL in Kubernetes.
One of the most important decisions you make when deploying MySQL in these environments is choosing between virtually synchronous (SYNC) and asynchronous (ASYNC) replication. Both are valuable, both are widely used, and both make perfect sense depending on the business problem you are trying to solve. In this post, we explain these concepts in a simple and friendly way, making them easy to follow for anyone working with MySQL in Kubernetes.

Replication in a Cloud-Native World
The importance of replication within the cloud-native ecosystem is paramount. When deploying a database cluster on modern platforms such as Kubernetes, the correct architectural perspective is to view the cluster not as a collection of distinct nodes, but as a cohesive, singular database service.
This approach marks a significant divergence from traditional on-premises or virtual machine (VM) deployments. In those conventional environments, practitioners typically treat and access each constituent cluster node as a separate, individually operable component. Cloud-native platforms, including Kubernetes, are fundamentally engineered to deliver an abstract service layer that inherently manages internal scaling and leverages the underlying pool of cluster nodes for its operational capacity.
Consequently, for database systems, the essential service objective is to guarantee reliable, scalable, and highly available access to persistent data. Replication is the indispensable mechanism through which this objective is achieved.
Its critical role means that replication has a much bigger impact on the overall behavior of the database. It influences how MySQL responds to updates, failovers, or disruptions in the underlying infrastructure. Many Kubernetes operators already include safeguards such as StatefulSets, readiness checks, PodDisruptionBudgets, and controlled failover logic to help coordinate cluster events with the chosen replication method.
This is where Virtually SYNC and ASYNC enter; these are types of replication, and the one you choose will directly affect how MySQL behaves during rolling updates, node disruptions, or failovers.
Virtually Synchronous Replication (SYNC)
Virtually Synchronous replication ensures that a transaction is only confirmed once the entire cluster agrees; it can be safely applied. This model is used in technologies like Galera, where nodes coordinate before committing any change.
When the client sends a write, one of the nodes processes the transaction and then shares the resulting changes with the rest of the cluster. Each node performs a certification check to verify that the write does not conflict with other in-flight transactions. Only after all nodes return a positive certification does the cluster reach agreement, and the client receives the final acknowledgement.
This coordination creates a unified, consistent view of data across the cluster. Even if a pod restarts, a node is rescheduled, or the underlying platform shifts workloads, every node commits the same changes in the same order.
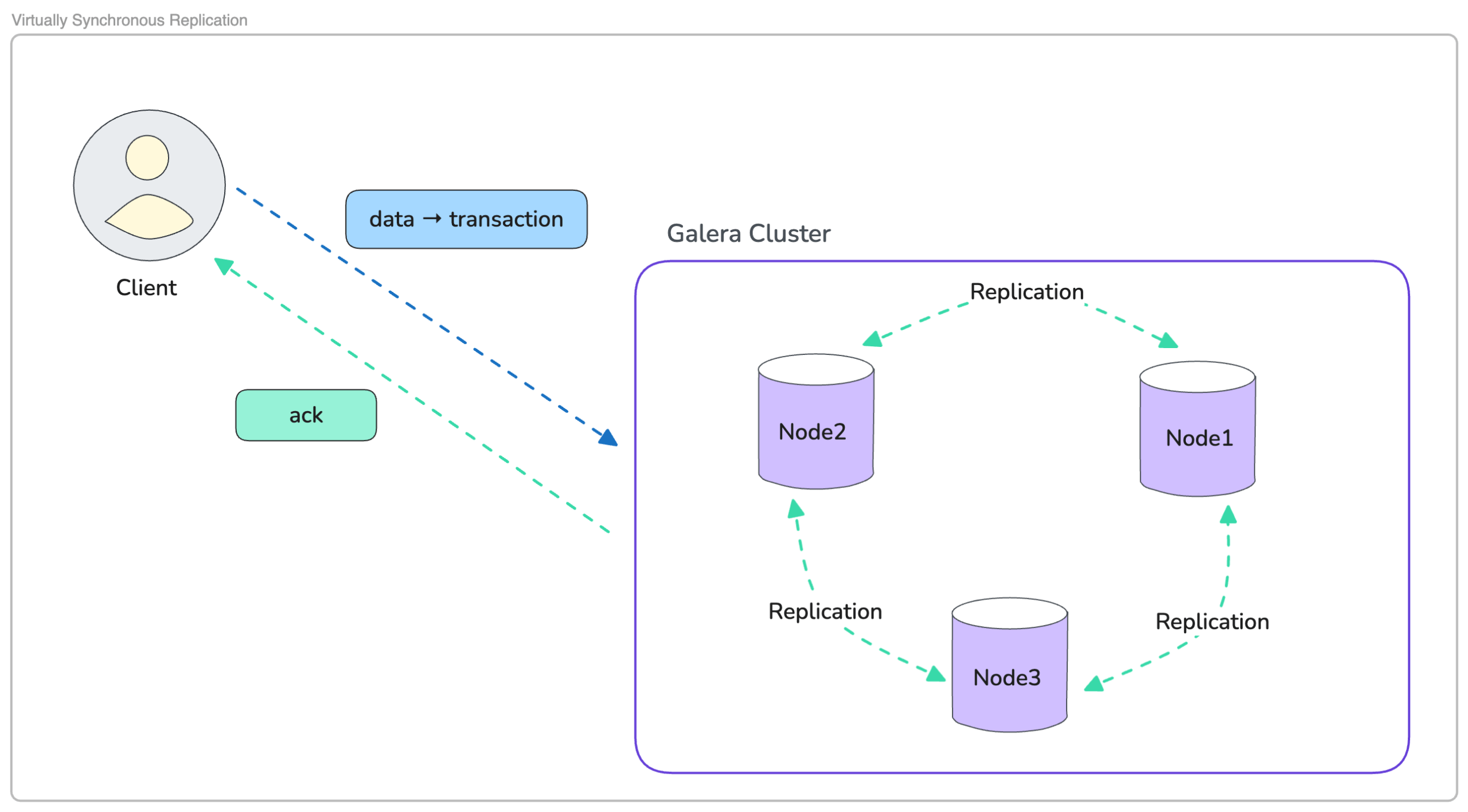
The trade-off is latency; virtually synchronous replication depends on the slowest participating node. Performance can vary with network conditions or node load. Still, the benefit is strong durability; once a transaction is acknowledged, it is safely stored across the cluster. This makes virtually synchronous replication the preferred option for financial systems, telecom platforms, booking engines, and any workload where correctness is more important than raw throughput.
Asynchronous Replication (ASYNC)
Asynchronous replication takes a lighter approach, working on a “commit first, replicate later” model.
When the client sends a write, the source node commits the change immediately and returns an acknowledgement to the application, even if the replicas have not yet seen the update. The replicas receive the transaction afterwards and apply it on their own timeline. Their process does not delay the client or slow down the commit path, which keeps write operations fast and predictable. In Kubernetes, this behavior works naturally with a platform that constantly shifts workloads around. Writes remain fast even if replicas are catching up or temporarily unavailable.
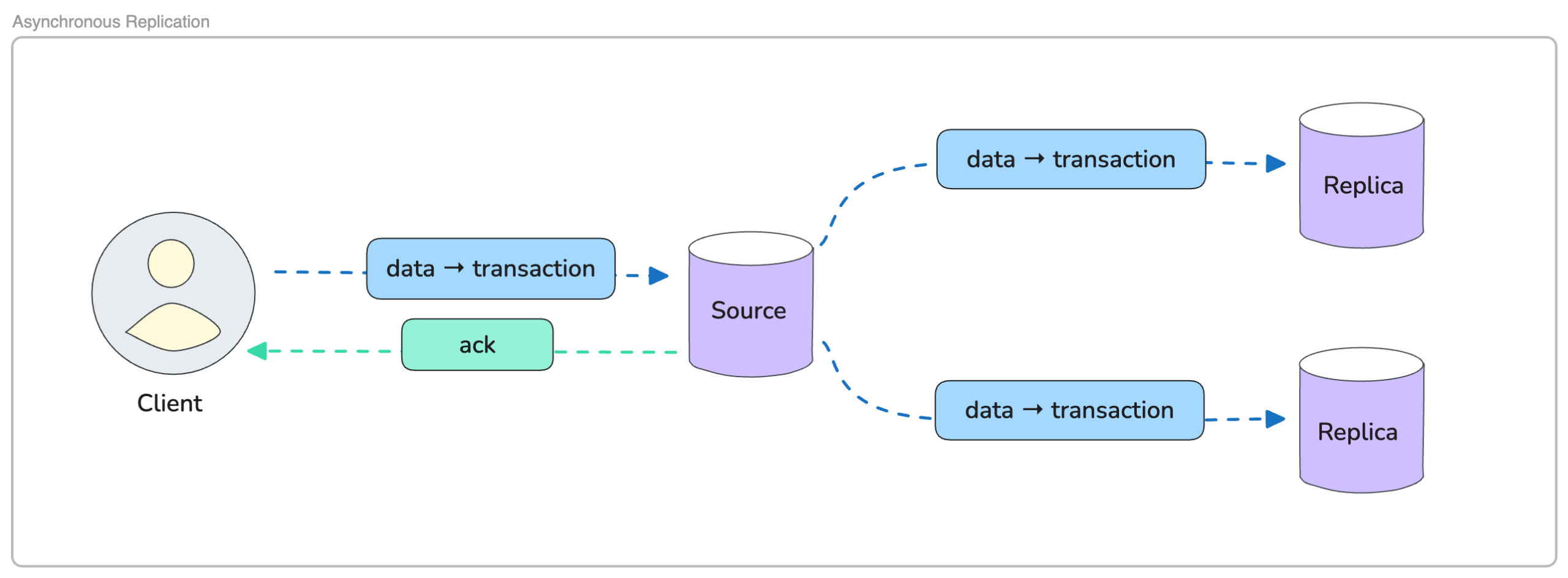
Here, the trade-off is a variable window of potential data loss if the source fails before the replicas receive the latest changes. But for many cloud-native applications, e-commerce sites, reporting dashboards, internal systems, or any workload without constant writes, the risk may be acceptable. Asynchronous replication also facilitates scaling reads by adding more replicas, a typical pattern in Kubernetes environments.
Why Cloud-Native Replication Behaves Differently
The fundamentals of Virtually SYNC and ASYNC don’t change, but their real-world behavior inside Kubernetes does. Rescheduling, storage latency, and network fluctuations can all affect how replication performs in real time. Kubernetes also automates failovers and recovery. This means replication mode affects how quickly operators can react, how safe a promoted node is, and how MySQL behaves during upgrades or disruptions
In cloud-native environments, replication becomes an infrastructure decision as much as a database decision, for example, when clusters span multiple availability zones, regions, or even multiple clouds, and the workload depends on specific storage or network paths. All of these infrastructure choices influence how Virtually SYNC and ASYNC replication behave in practice.
Choosing the Right Approach
If your workload requires strong consistency and cannot lose data, Virtually SYNC is the right choice. If performance is the priority or the workload tolerates a slight replication lag, ASYNC may offer better flexibility. In Kubernetes, both replication types have distinct behaviors, and both are valid, depending on the application’s needs.
As organisations modernise their infrastructure and move to MySQL in Kubernetes, having the freedom to choose between Virtually SYNC and ASYNC becomes essential. Teams need the flexibility to align replication behavior with their business goals and their cloud-native architecture.
What Comes Next
MySQL today provides two broad replication paths: Galera-based virtually synchronous replication and native MySQL replication (which includes asynchronous replication and Group Replication). Both are widely used, and each offers different strengths. Percona now offers operators that support both replication models, allowing users to choose the method that best fits their workload.
For example, the PXC operator provides virtually synchronous Galera-based replication, while the new Percona Operator for MySQL brings native MySQL replication, including async (tech preview) and Group Replication.
This blog post is meant to close that knowledge gap. Recently, we announced an important milestone for MySQL users running on Kubernetes: Native MySQL replication into cloud-native environments through the Percona Operator for MySQL. Read our announcement: Introducing the GA Release of the New Percona Operator for MySQL: More Replication Options on Kubernetes.
Understanding Virtually Synchronous and Asynchronous replication now will make it easier to appreciate what is new, why it is essential for the community, and how it benefits teams building resilient MySQL environments in Kubernetes.
Do you have questions, ideas, or feedback about MySQL replication on Kubernetes?
- Join the discussion in our community forum, we’d love to hear from you!
Want to explore the operator, contribute, or follow development? Visit the open source Percona Operator for MySQL repository on GitHub
- Together, we can continue improving the MySQL experience for everyone in the open source community.
About the Authors
 Edith Puclla
Edith PucllaEdith Puclla is a Technology Evangelist at Percona Corporation, a CNCF Ambassador, an open source contributor with a background in DevOps, and a Docker and Kubernetes enthusiast.
 Marco Tusa
Marco TusaMarco Tusa had his own international practice for the past twenty eight years. His experience and expertise are in a wide variety of information technology and information management fields, cover research, development, analysis, quality control, project management and team management. Marco is currently working at Percona as High Availability Practice Manager, previously working at Percona as manager of the Consulting Rapid Response Team on October 2013. He has being working as employee for the SUN Microsystems as MySQL Professional Service manager for South Europe., and previously in MySQL AB. He has worked with the Food and Agriculture Organization of the United Nation since 1994, leading the development of the Organization’s hyper textual environment.Team leader for the FAO corporate database support. For several years he has led the development group in the WAICENT/Faoinfo team. He has assisted in defining the Organization’s guidelines for the dissemination of information from the technology and the management point of view. He has participated in field missions in order to perform analysis, reviews and evaluation of the status of local projects, providing local support and advice. He had collaborates with MIT Media Lab (Massachusetts Institute of Technology laboratory) and FAO as Sustainable Information Technology for developing countries Specialist in relation with the FAO’s Special Program for Food Security for Senegal.





