

For a long time, I’ve been thinking about the possibility of importing a single file with multiple connections. Why? Simply because we have scenarios where we end up importing a big file with a single loader thread. Well, I have good news: since the release of 0.16.3-1, we are able to do it.
There are multiple reasons why we end up with a large file in a MyDumper backup. For instance, if just one thread is used to export a large table, or just because we don’t want to use -F, or the worse case, that the table doesn’t have an integer primary key or no primary key at all.
Nowadays, it is also possible to end with a small number of big files because mydumper can export a large table, creating the same number of files as the number of threads that we configure with -t.
Take into account that MyDumper used to use the files to isolate the loader threads, which means that it used one execution thread per file:
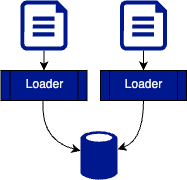
And now, we can use multiple connections:

You can see more details about it in #1474 and #1477.
Performance improvements
To test the performance improvement, I used a 5M row sysbench table that was created with the next command:
|
1 |
# sysbench /usr/share/sysbench/oltp_write_only.lua --table-size=5000000 --tables=1 --threads=1 --mysql-user=root --mysql-db=sbtest --rate=10 --time=0 --report-interval=10 --create_secondary=off prepare |
The myloader command was the same in all the cases:
|
1 |
./myloader -u root -v 4 -o -d ~/data |
Test with a single file
To create just a single file with the 5M rows, I run this command:
|
1 |
# ./mydumper -o ~/data/ -B sbtest --clear |
The import with v0.16.1-3 used one single thread and took 65.2 seconds to complete
|
1 2 |
** Message: 20:29:51.125: Thread 3: restoring sbtest.sbtest1 part 1 of 1 from sbtest.sbtest1.00000.sql. Progress 1 of 1. Tables 0 of 1 completed ** Message: 20:30:56.385: Thread 3: Data import ended |
The new version took 28.7 seconds as it used four connections to import the table:
|
1 2 3 4 5 |
** Message: 20:28:14.302: Thread 2: restoring sbtest.sbtest1 part 1 of 1 from sbtest.sbtest1.00000.sql. Progress 1 of 1. Tables 0 of 1 completed ** Message: 20:28:14.302: Thread 1: Data import ended ** Message: 20:28:14.302: Thread 4: Data import ended ** Message: 20:28:14.302: Thread 3: Data import ended ** Message: 20:28:43.089: Thread 2: Data import ended |
Test with multiple files
To create a backup with files of 200MB, I executed this command, which is going to create five files:
|
1 |
./mydumper -o ~/data/ -B sbtest --clear -F 200 |
The v0.16.1-3 now decreased the time to 33.4 seconds as it is using the four threads:
|
1 2 3 4 5 6 7 8 9 |
** Message: 20:31:42.153: Thread 2: restoring sbtest.sbtest1 part 3 of 5 from sbtest.sbtest1.00000.00001.sql. Progress 1 of 5. Tables 0 of 1 completed ** Message: 20:31:42.153: Thread 1: restoring sbtest.sbtest1 part 5 of 5 from sbtest.sbtest1.00000.sql. Progress 2 of 5. Tables 0 of 1 completed ** Message: 20:31:42.153: Thread 3: restoring sbtest.sbtest1 part 1 of 5 from sbtest.sbtest1.00000.00002.sql. Progress 3 of 5. Tables 0 of 1 completed ** Message: 20:31:42.153: Thread 4: restoring sbtest.sbtest1 part 4 of 5 from sbtest.sbtest1.00000.00003.sql. Progress 4 of 5. Tables 0 of 1 completed ** Message: 20:32:04.148: Thread 1: restoring sbtest.sbtest1 part 2 of 5 from sbtest.sbtest1.00000.00004.sql. Progress 5 of 5. Tables 0 of 1 completed ** Message: 20:32:04.585: Thread 4: Data import ended ** Message: 20:32:04.818: Thread 2: Data import ended ** Message: 20:32:05.236: Thread 3: Data import ended ** Message: 20:32:15.589: Thread 1: Data import ended |
And the new version takes 27.6 seconds:
|
1 2 3 4 5 6 7 8 9 |
** Message: 20:32:54.550: Thread 1: restoring sbtest.sbtest1 part 5 of 5 from sbtest.sbtest1.00000.sql. Progress 1 of 5. Tables 0 of 1 completed ** Message: 20:32:54.550: Thread 2: restoring sbtest.sbtest1 part 3 of 5 from sbtest.sbtest1.00000.00001.sql. Progress 2 of 5. Tables 0 of 1 completed ** Message: 20:32:54.550: Thread 4: restoring sbtest.sbtest1 part 1 of 5 from sbtest.sbtest1.00000.00002.sql. Progress 3 of 5. Tables 0 of 1 completed ** Message: 20:32:54.550: Thread 3: restoring sbtest.sbtest1 part 4 of 5 from sbtest.sbtest1.00000.00003.sql. Progress 4 of 5. Tables 0 of 1 completed ** Message: 20:33:15.626: Thread 3: restoring sbtest.sbtest1 part 2 of 5 from sbtest.sbtest1.00000.00004.sql. Progress 5 of 5. Tables 0 of 1 completed ** Message: 20:33:16.932: Thread 4: Data import ended ** Message: 20:33:17.242: Thread 1: Data import ended ** Message: 20:33:17.306: Thread 2: Data import ended ** Message: 20:33:22.139: Thread 3: Data import ended |
Test with multiple files of the same size
As you can see from the previous test, there were five files whose sizes were not the same. The command that I executed to check with files with the same sizes was:
|
1 2 3 4 5 6 7 8 9 10 |
# ./mydumper -o ~/data/ -B sbtest --clear -F 242 # ls -l ~/data total 969M -rw-r--r-- 1 root root 483 Apr 30 20:59 metadata -rw-r----- 1 root root 404 Apr 30 20:59 sbtest-schema-create.sql -rw-r----- 1 root root 530 Apr 30 20:59 sbtest.sbtest1-schema.sql -rw-r----- 1 root root 243M Apr 30 20:59 sbtest.sbtest1.00000.00001.sql -rw-r----- 1 root root 243M Apr 30 20:59 sbtest.sbtest1.00000.00002.sql -rw-r----- 1 root root 242M Apr 30 20:59 sbtest.sbtest1.00000.00003.sql -rw-r----- 1 root root 243M Apr 30 20:59 sbtest.sbtest1.00000.sql |
This is the only case where the v0.16.1-3 performed at the same level as the new version, as it took 28.5 seconds:
|
1 2 3 4 5 6 7 8 |
** Message: 20:36:59.366: Thread 1: restoring sbtest.sbtest1 part 1 of 4 from sbtest.sbtest1.00000.00002.sql. Progress 1 of 4. Tables 0 of 1 completed ** Message: 20:36:59.366: Thread 3: restoring sbtest.sbtest1 part 2 of 4 from sbtest.sbtest1.00000.00001.sql. Progress 2 of 4. Tables 0 of 1 completed ** Message: 20:36:59.367: Thread 4: restoring sbtest.sbtest1 part 3 of 4 from sbtest.sbtest1.00000.00003.sql. Progress 3 of 4. Tables 0 of 1 completed ** Message: 20:36:59.376: Thread 2: restoring sbtest.sbtest1 part 4 of 4 from sbtest.sbtest1.00000.sql. Progress 4 of 4. Tables 0 of 1 completed ** Message: 20:37:26.036: Thread 3: Data import ended ** Message: 20:37:27.352: Thread 1: Data import ended ** Message: 20:37:27.725: Thread 4: Data import ended ** Message: 20:37:27.867: Thread 2: Data import ended |
The new version is still taking 28.1 seconds:
|
1 2 3 4 5 6 7 8 |
** Message: 20:36:00.480: Thread 2: restoring sbtest.sbtest1 part 4 of 4 from sbtest.sbtest1.00000.sql. Progress 1 of 4. Tables 0 of 1 completed ** Message: 20:36:00.480: Thread 1: restoring sbtest.sbtest1 part 2 of 4 from sbtest.sbtest1.00000.00001.sql. Progress 2 of 4. Tables 0 of 1 completed ** Message: 20:36:00.480: Thread 3: restoring sbtest.sbtest1 part 1 of 4 from sbtest.sbtest1.00000.00002.sql. Progress 3 of 4. Tables 0 of 1 completed ** Message: 20:36:00.481: Thread 4: restoring sbtest.sbtest1 part 3 of 4 from sbtest.sbtest1.00000.00003.sql. Progress 4 of 4. Tables 0 of 1 completed ** Message: 20:36:28.342: Thread 3: Data import ended ** Message: 20:36:28.430: Thread 4: Data import ended ** Message: 20:36:28.577: Thread 1: Data import ended ** Message: 20:36:28.592: Thread 2: Data import ended |
Fragmentation
The next graphs were built with the https://github.com/jeremycole/innodb_ruby/ tool.
On the left is the new version, and on the right is the v0.16.1-3:
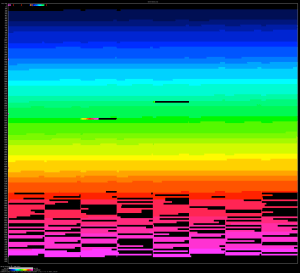
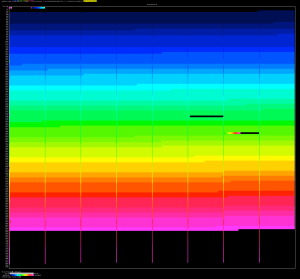
As you can see, the new version is causing a high fragmentation at the end of the process. This is expected when you insert rows with multiple threads in sequential order due to the split of the pages.
This is why it is so important to use -F when you take backups, as it will split the tables and/or the chunks into multiple pieces, which, in the end, reduces fragmentation when you import the table.
Conclusions
As we can see, the new version takes a consistent amount of time and is faster in most scenarios. It does not rely on how you take the backup to improve performance. The only drawback is that some undesirable fragmentation on the table can occur, but it can be reduced with the proper configuration when you take the backups.
Percona for MySQL offers enterprise-grade scalability and performance without traditional enterprise drawbacks. We deliver secure, tested, open source software complete with advanced features like backup, monitoring, and encryption only otherwise found in MySQL Enterprise Edition.
Learn Why Customers Choose Percona for MySQL
About the Author
 David Ducos
David DucosDavid studied Computer Science in National University of La Plata and has worked as a DBA consultant since 2008. For the past 3 years he worked with a worldwide platform of free classifieds up until he joined Percona's consulting team in November 2014. David lives near Buenos Aires, Argentina and in his free time loves to spend time with his family.






I love those illustrations at the bottom! I finally found the old blog post where that specific part of the innodb_ruby tool is talked about, for anyone else wanting that it’s here: Illustrating Primary Key models in InnoDB and their impact on disk usage