

In a previous article, Scalability for the Large-Scale: File Copy-Based Initial Sync for Percona Server for MongoDB, we presented some early benchmarks of the new File Copy-Based Initial Sync (FCBIS) available in Percona Server for MongoDB. Those first results already suggested significant improvements compared to the default Logical Initial Sync.
In this post, we extend our testing with a more structured comparison between the two methods. We performed several Initial Sync operations using databases of different sizes, ranging from a few gigabytes to several hundred gigabytes and a few terabytes. We also tested the impact of having a different number of indexes and collections. For each test, we measured the time it took to perform the Initial Sync, stopping one node, removing the data directory, and restarting it. This triggered the Initial Sync.
In the graphs provided, you can see the comparison of the times between the two methods.
Important note
The FCBIS feature is available only in a ProBuild of Percona Server for MongoDB starting from 8.0.12-4 and 7.0.22-12.
ProBuild of Percona Server for MongoDB is a build of Percona Server for MongoDB that contains purpose-built enterprise features. It is wrapped in packages created and tested by Percona and is available for Percona customers. Non-paying Percona software users can also benefit from Percona ProBuilds, but they’ll have to build them from the source code provided by Percona and available to everyone.
How to use it
The FCBIS method is a physical copying of the data files from the source to the target. It is much faster than the default logical initial sync. It is especially beneficial for large data sets. Using this initial sync method speeds up cluster scaling and increases restore performance.
Percona’s file copy-based initial sync implementation is compatible with that of MongoDB Enterprise Advanced and has the same configuration parameters.
To select the initial sync method, specify the initialSyncMethod parameter in the configuration file for the target node:
|
1 2 |
setParameter: initialSyncMethod: fileCopyBased |
You can only set this server parameter at startup. If you want to return to the default behavior, you can set the parameter to logical or simply remove the configuration.
The test environment
We deployed a 3-node Replica Set (Primary-Secondary-Secondary) on AWS with EC2 instances. Here are the specifications:
INSTANCE TYPE: t3.xlarge
vCPUs: 4
RAM: 16 GB
STORAGE: 1.2TB, gp2, 3600 IOPS
For all the tests, we used Percona Server for MongoDB 8.0.12-4 with default settings.
POCDriver was used for creating fake collections and data.
First test: Small dataset with different indexes
Let’s see how the FCBIS impacts a very small data set with different numbers of indexes. Only one collection was created.
| collections | 1 | 1 | 1 | 1 |
| indexes/collection | 1 | 2 | 5 | 10 |
| data size | 30GB | 30GB | 30GB | 30GB |
| storage size | 10GB | 10GB | 10GB | 10GB |
| size per doc | 500 bytes | 500 bytes | 500 bytes | 500 bytes |
| Logical (min) | 4 | 5 | 8 | 12 |
| FCBIS (min) | 2 | 2 | 3 | 3 |
Here is the graph. Less is better.
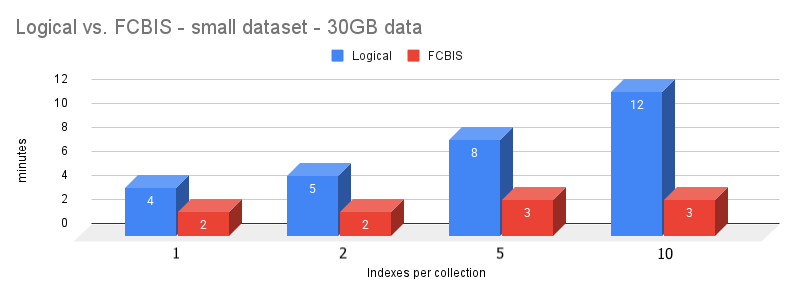
FCBIS time increases more slowly than Logical when adding more indexes. During the Logical Initial Sync, the index rebuild requires more time. In the physical copy, there are a few more files, but the indexes don’t need rebuilding. For this reason, the Logical sync increases more rapidly the more indexes we create.
Second test: 300GB dataset with different indexes
Let’s try now with a larger dataset with a couple of collections.
| collections | 2 | 2 | 2 | 2 |
| indexes/collection | 2 | 3 | 4 | 5 |
| data size | 300GB | 300GB | 300GB | 300GB |
| storage size | 100GB | 100GB | 100GB | 100GB |
| size per doc | 10KB | 10KB | 10KB | 10KB |
| Logical (min) | 25 | 26 | 28 | 29 |
| FCBIS (min) | 9 | 11 | 12 | 12 |
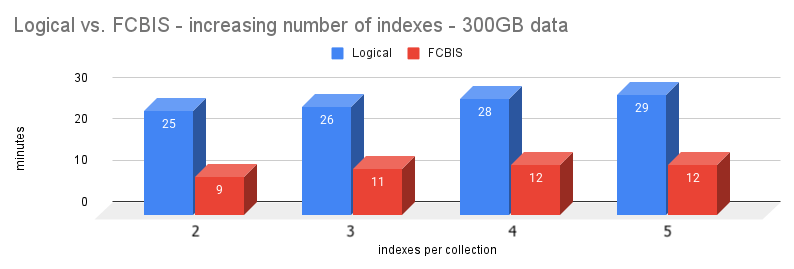
The tests confirm that FCBIS is 2x to 3x faster than Logical. They also confirm the impact of having more indexes.
Third test: 1.5TB dataset with different indexes
Let’s move to a large scale for a replica set. Let’s test now with a 1.5TB
| collections | 5 | 5 | 5 | 5 |
| indexes/collection | 1 | 4 | 7 | 10 |
| data size | 1.5TB | 1.5TB | 1.5TB | 1.5TB |
| storage size | 500GB | 500GB | 500GB | 500GB |
| size per doc | 10KB | 10KB | 10KB | 10KB |
| Logical (min) | 111 | 125 | 129 | 131 |
| FCBIS (min) | 44 | 46 | 46 | 48 |
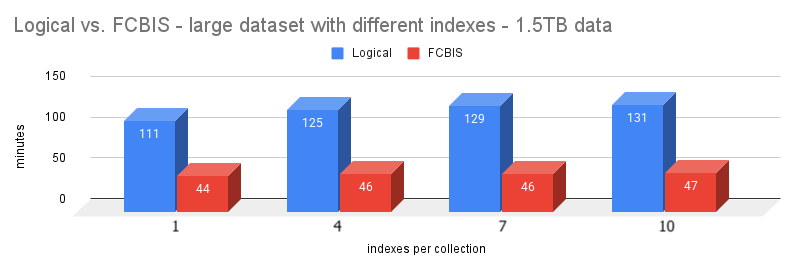
Again, FCBIS is from 2x to 3x faster than Logical. The ratio increases the more indexes we have per collection.
Fourth test: 3TB dataset with different indexes
Let’s move to a very large scale for a replica set. Let’s test now with a 3TB and different indexes as usual.
| collections | 60 | 60 | 60 |
| indexes/collection | 0 | 5 | 10 |
| data size | 3TB | 3TB | 3TB |
| storage size | 1TB | 1TB | 1TB |
| size per doc | 8KB | 8KB | 8KB |
| Logical (min) | 212 | 235 | 275 |
| FCBIS (min) | 87 | 93 | 102 |
Again, the same behavior is confirmed. FCBIS is preferable at a very large scale, and the more indexes we create, the slower the Logical Sync.
Fifth test: Effect of increasing the number of collections
In this last test, the goal is to test the effect of having more collections increasing the data size, but maintaining the same number of indexes per collection.
| collections | 1 | 5 | 10 | 20 | 40 | 60 | 80 | 100 |
| indexes/collection | 5 | 5 | 5 | 5 | 5 | 5 | 5 | 5 |
| data size | 4GB | 30GB | 66GB | 123GB | 230GB | 330GB | 426GB | 530GB |
| storage size | 2GB | 10GB | 22GB | 41GB | 76GB | 110GB | 142GB | 177GB |
| size per doc | 3KB | 3KB | 3KB | 3KB | 3KB | 3KB | 3KB | 3KB |
| Logical (min) | 1 | 4 | 9 | 17 | 35 | 54 | 82 | 96 |
| FCBIS (min) | 2 | 2 | 3 | 5 | 9 | 13 | 17 | 21 |
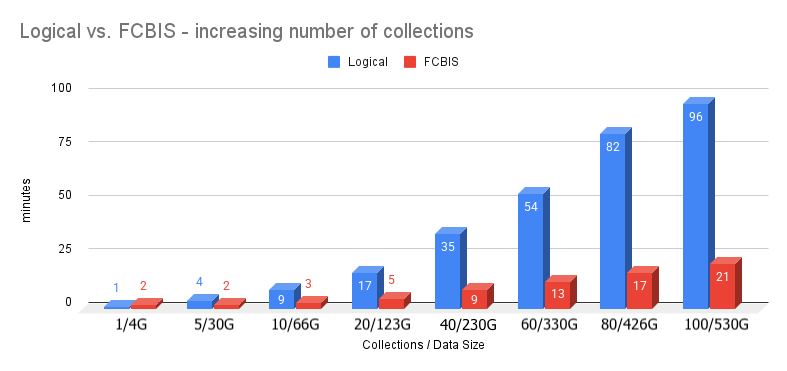
As expected, both methods take longer with more and more data, but the Logical increases almost exponentially with more collections than FCBIS, which looks linear instead. The ratio is from 2x to 4x, and it should further increase with even larger data sets.
Conclusion
On large datasets, the File Copy Based approach can deliver 2x to 4x faster initial sync times compared to the Logical Initial Sync, particularly with a large number of collections and more indexes. This means that adding new replica set members or recovering nodes after failures can be done in a fraction of the time previously required.
For environments running large MongoDB deployments, the File Copy Based Initial Sync is a game-changer, providing significant efficiency and operational advantages over the traditional logical method.
Keep in mind that the results can be affected by external factors like network overhead, storage resources, and MongoDB-specific tunings. In any case, we can say FCBIS is definitely faster in the majority of use cases.
We’re excited to hear about your experiences with the new file copy-based initial sync method in Percona Server for MongoDB. Your feedback and performance results are invaluable to us as we continue to improve our software. Please share your thoughts, benchmarks, and any issues you’ve encountered on our community forum at https://forums.percona.com/c/mongodb/percona-server-for-mongodb/17. We look forward to hearing from you and appreciate your contributions to the Percona community!

About the Author
 Corrado Pandiani
Corrado PandianiPrior to joining Percona as a Senior Consultant, Corrado spent more than 20 years in developing web sites and designing and administering MySQL. He is a MySQL enthusiast since version 3.23 and his skills are focused on performances and architectural design. He's also a trainer and a MongoDB consultant.





