

Percona ClusterSync for MongoDB (PCSM) replicates data between MongoDB clusters — whether replica sets or sharded — handling both the initial bulk data clone and continuous change replication via MongoDB’s change streams. It’s designed for migrations, failover preparation, and keeping a secondary cluster in sync with production.
Version 0.8.0 brings two architectural changes to the change replication pipeline that significantly improve throughput and reduce replication lag under high write workloads. Both changes target the continuous replication phase — the long-running process that tails the source cluster’s change stream and applies events to the target.
In this post, we’ll walk through what changed, why it matters, and how the new architecture works.
The Starting Point: A Simple, Correct Pipeline
The original change replication pipeline in PCSM was intentionally simple. A single goroutine handled the entire flow: reading events from the MongoDB change stream, parsing the BSON payloads, and writing bulk operations to the target cluster — all sequentially, in a single thread.
This design was a deliberate choice. Replicating data between MongoDB clusters involves subtle correctness challenges — preserving document-level operation ordering, handling DDL events that affect schema, and maintaining checkpoint consistency so replication can resume safely after a failure. Getting all of this right was the priority, and a single-threaded pipeline made the logic easier to reason about, test, and verify.
The trade-off was performance. Under high write throughput, the sequential pipeline became a bottleneck. While the worker waited for MongoDB to acknowledge a bulk write, it couldn’t read new events from the change stream. Write latency on the target directly blocked read throughput from the source. Replication lag would grow under sustained load, even when both clusters had spare capacity.
With the correctness foundation proven across months of testing and production use than adding support for sharded clusters in 0.7.0, 0.8.0 was the right time to unlock performance — without compromising those guarantees.
Feature 1: Document-Level Parallel Replication
The first major change replaces the single-goroutine pipeline with a worker pool architecture that processes events in parallel across multiple workers.
How It Works
The pipeline is now split into three stages:
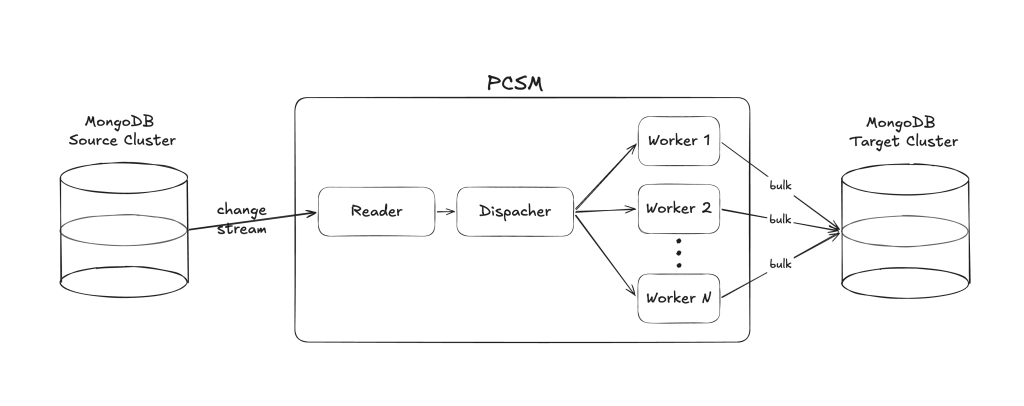
- Reader — A single goroutine reads events from the MongoDB change stream. Instead of parsing and applying them immediately, it passes the raw BSON downstream.
- Dispatcher — Routes each event to a specific worker based on a consistent hash of the document key. This is the critical design decision: the same document always maps to the same worker, which preserves per-document operation ordering without any cross-worker coordination.
- Workers — Each worker independently parses BSON and builds bulk write operations for its assigned documents. By default, the number of workers matches the number of available CPU cores.
Preserving Correctness
Parallelism introduces risk if you’re not careful. PCSM 0.8.0 handles the edge cases:
- Per-document ordering is guaranteed by the hashing scheme — all operations for a given document flow through the same worker, in order. This way, we ensure we don’t insert a document after it was deleted.
- DDL events (collection drops, renames, index changes) trigger a write barrier: All workers flush their pending writes before the DDL is applied, then resume. This prevents schema changes from racing with in-flight DML operations. Essentially ensures we don’t insert documents into a collection that was dropped in the meantime.
- Capped collections are routed by namespace rather than document key, that way all the documents from capped collections are routed to the same worker, preserving insertion order as MongoDB requires.
Deferred Parsing
A secondary but meaningful optimization: BSON parsing now happens inside the workers rather than in the reader. In the old pipeline, the single goroutine parsed every event before doing anything else. Now, raw BSON is passed to N workers, which parse it in parallel. This spreads CPU-bound work across cores and keeps the reader focused on consuming events from the change stream as fast as possible.
Feature 2: Async Bulk Write Pipeline
The second change goes one level deeper. Even with multiple workers, each worker still had the original problem: when it called flush() to write a bulk operation to MongoDB, it blocked until the write was acknowledged. During that time, the worker couldn’t read new events from its queue.
The async bulk-write pipeline decouples bulk building from bulk writing within each worker.
How It Works
Each worker now has two goroutines:
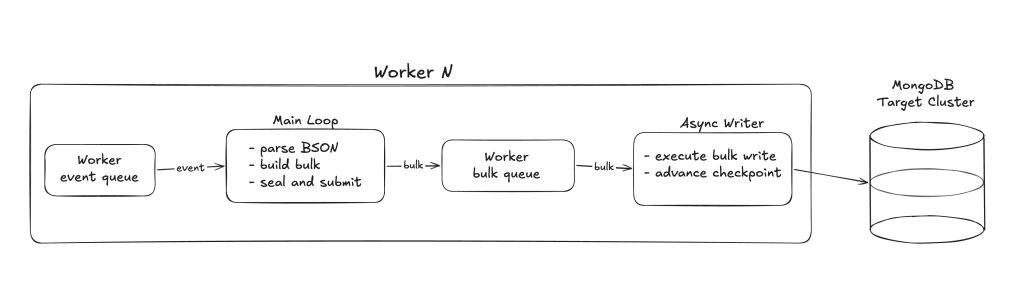
- Main loop — Reads events from its queue, parses BSON, and assembles bulk write operations. When a bulk is full (or the flush interval fires), it seals the bulk and submits it to a bounded queue. After the sealed bulk is queued, the loop continues processing events and building the next bulk without waiting.
- Async writer — A dedicated goroutine that dequeues sealed bulks and executes them against MongoDB. While a write is in-flight, the main loop continues building the next batch.
This means workers are never idle waiting for MongoDB. They’re always reading and batching the next set of operations while the previous write completes.
Backpressure and Memory Bounds
The bulk queue per worker is bounded (default size: 3). When the queue is full, the main loop blocks on submit() until the writer dequeues a bulk. This provides natural backpressure — if MongoDB can’t keep up, workers slow down rather than consuming unbounded memory.
Maximum memory per worker is capped at: workers event queue size + bulk batches queue size + 1 bulk being written + 1 bulk being built. This is predictable and configurable.
Checkpoint Safety
Each sealed bulk captures the checkpoint timestamp at seal time — the timestamp of the latest event included in that bulk. The committed checkpoint is only advanced after the async writer confirms the bulk was persisted to MongoDB. This ensures that if PCSM crashes or restarts, it resumes from a timestamp that reflects what was actually written, never skipping events.
Barrier Handling
When a barrier event arrives (DDL or stop request), the main loop closes the bulk queue and waits for the async writer to finish all pending bulks. Only after everything is flushed does the barrier proceed. On resume, the writer goroutine is restarted with fresh state.
The Combined Effect
Together, these two features transform the pipeline from a single-threaded sequential process into a fully pipelined, parallel architecture:
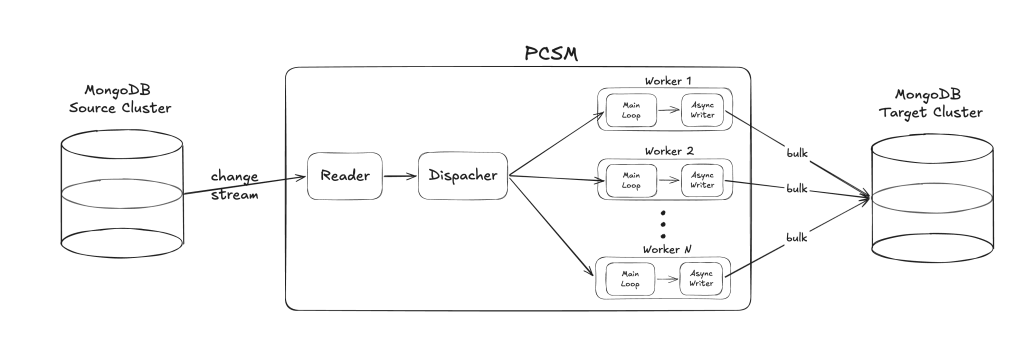
The improvement is multiplicative:
- Parallel replication spreads work across N workers (CPU cores).
- Async writes ensure each worker overlaps I/O with computation, eliminating idle time waiting for MongoDB acknowledgments.
The result is that the pipeline can sustain substantially higher event throughput before replication lag begins to grow.
Tuning options
All replication tuning parameters (worker count, queue sizes, batch sizes, flush intervals) are now configurable via CLI flags, environment variables, and the HTTP API. The defaults are auto-tuned and work well for most deployments. For the full list of options and guidance on when to adjust them, see the PCSM Configuration Reference.
Benchmark Results
We tested change replication throughput across document sizes ranging from 500 bytes to 200 KB. Source client compressors set for maximizing change stream read throughput. The metric is maximum sustained QPS (queries per second on the source) before replication lag begins to accumulate.
PCSM was running on an AWS i3en.3xlarge instance with 12 CPU cores and 96 GiB of RAM.
Replica Set Clusters Test Results
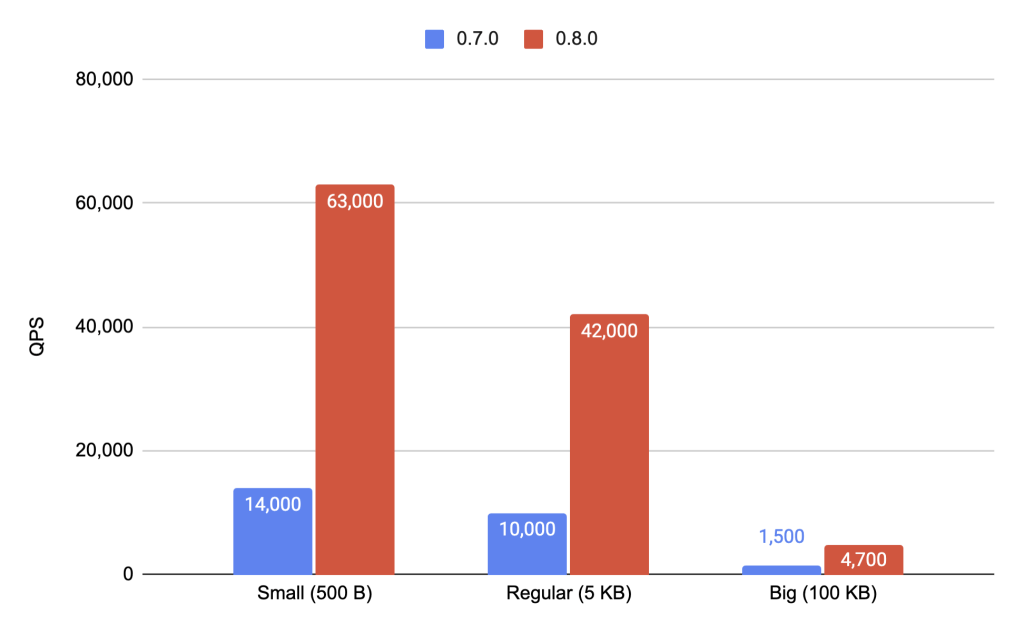
From the graph we can see that we have 4.5x improvement for small, 4.2x for regular and 3.1x for big documents.
Sharded Cluster Test Results
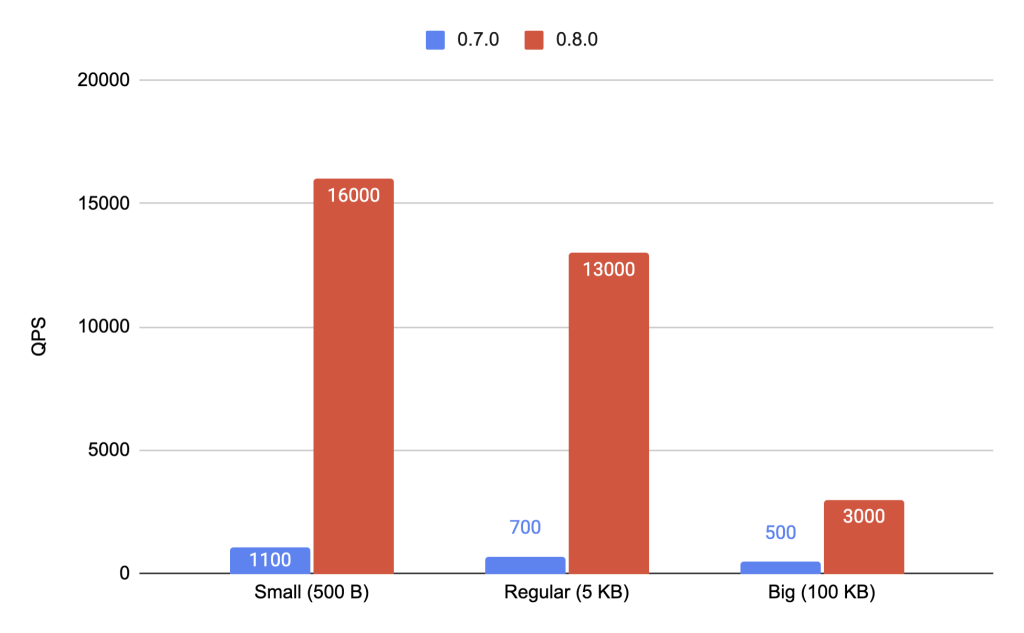
On sharded clusters we can see much bigger improvements, that is 14,5x for small, 18,5x for regular and 6x improvement for big documents.
What’s Next
PCSM 0.8.0 removes the major bottleneck that existed during the apply phase — parsing events and writing them to the target. With parallel workers and async writes, the apply pipeline can now saturate the target cluster’s write capacity much more effectively.
Interestingly, this shifts the bottleneck. In our testing, the primary limiting factor is now the rate at which events can be read from MongoDB’s change stream, particularly when documents are large. Change stream throughput is ultimately governed by MongoDB server-side performance and network bandwidth, which are outside PCSM’s control. This is an area we’re actively investigating for future releases.
For sharded clusters, we plan to add support for multi-instance PCSM deployment, where each PCSM instance handles a single shard independently. This will allow replication throughput to scale linearly with the number of shards.
If you’re evaluating PCSM for a migration or considering an upgrade, 0.8.0 is a significant step forward for write-heavy workloads. The defaults are designed to work well without tuning, but the new configuration options give you full control when you need it.
Join the Community
Percona thrives on community collaboration. As we continue to refine PCSM and celebrate its production-ready GA release, we invite you to get involved. We welcome bug reports, feature suggestions, and code contributions. Your input helps us build the tools the MongoDB community actually needs. We encourage you to deploy PCSM in your production environments today! Check out the PCSM repository and join the journey with us!
Ready to break free from vendor lock-in? Check out the PCSM Documentation to get started with your first sync today.
About the Author
 Inel Pandzic
Inel PandzicInel is a senior software engineer specializing in distributed systems and database infrastructure. He previously built Kubernetes database operators at Percona and is currently working on a MongoDB cluster-to-cluster replication tool. With over 10 years of experience, he focuses on designing reliable systems and building tools that empower developers and platform teams. He shares his insights at inelpandzic.com and on his YouTube channel.





