

In this blog post, we will explore how network partitions impact group replication and the way it detects and responds to failures. In case you haven’t checked out my previous blog post about group replication recovery strategies, please have a look at them for some insight.
Topology:
|
1 2 3 4 5 6 7 8 9 |
node1 [localhost:23637] {msandbox} ((none)) > select * from performance_schema.replication_group_members; +---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+----------------------------+ | CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE | MEMBER_ROLE | MEMBER_VERSION | MEMBER_COMMUNICATION_STACK | +---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+----------------------------+ | group_replication_applier | 00023637-1111-1111-1111-111111111111 | 127.0.0.1 | 23637 | ONLINE | PRIMARY | 8.0.36 | XCom | | group_replication_applier | 00023638-2222-2222-2222-222222222222 | 127.0.0.1 | 23638 | ONLINE | SECONDARY | 8.0.36 | XCom | | group_replication_applier | 00023639-3333-3333-3333-333333333333 | 127.0.0.1 | 23639 | ONLINE | SECONDARY | 8.0.36 | XCom | +---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+----------------------------+ 3 rows in set (0.00 sec) |
Scenario 1: One of the GR nodes [node3] faces some network interruption
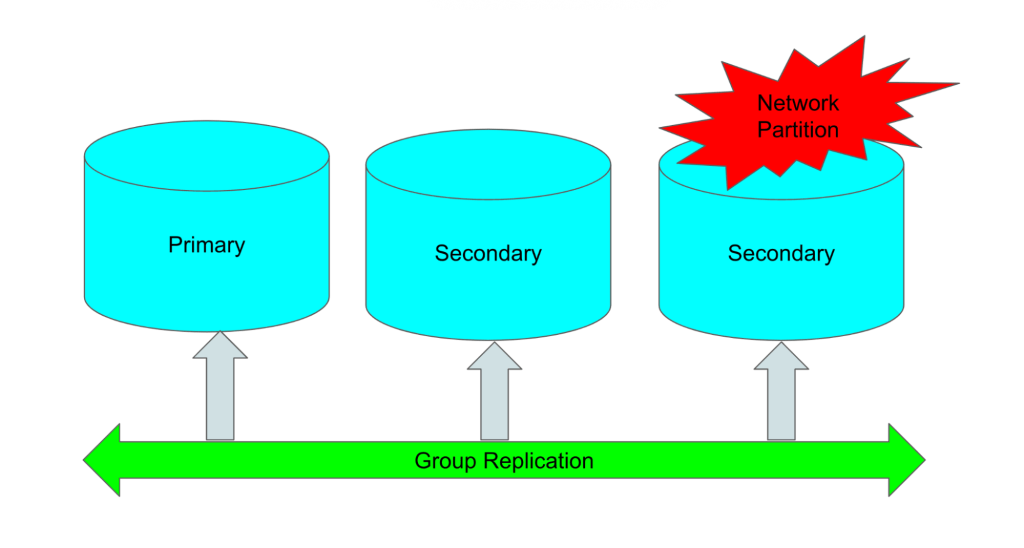
This diagram depicts a single node down/partitioned.
1. Here, we will block the group replication communication on port[23764] for node3.
|
1 2 3 4 5 6 7 |
node3 [localhost:23639] {msandbox} ((none)) > select @@group_replication_group_seeds; +-------------------------------------------------+ | @@group_replication_group_seeds | +-------------------------------------------------+ | 127.0.0.1:23762,127.0.0.1:23763,127.0.0.1:23764 | +-------------------------------------------------+ 1 row in set (0.00 sec) |
Blocking communication:
|
1 |
shell> echo "block drop on lo0 proto tcp from 127.0.0.1 to 127.0.0.1 port 23764" | sudo pfctl -ef - |
Note – PF(packet filter) tool is used here for enabling the firewall and ruleset because it’s compatible with the macOS which I used for my setup. On Linux/Windows other native firewalls/tools can be used for similar network breaking things.
Verifying the rule:
|
1 |
shell> sudo pfctl -sr |
Output:
|
1 |
block drop on lo0 inet proto tcp from 127.0.0.1 to 127.0.0.1 port = 23764 |
2. Now, let’s verify the group status again.
|
1 2 3 4 5 6 7 8 9 |
node1 [localhost:23637] {msandbox} ((none)) > select * from performance_schema.replication_group_members; +---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+----------------------------+ | CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE | MEMBER_ROLE | MEMBER_VERSION | MEMBER_COMMUNICATION_STACK | +---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+----------------------------+ | group_replication_applier | 00023637-1111-1111-1111-111111111111 | 127.0.0.1 | 23637 | ONLINE | PRIMARY | 8.0.36 | XCom | | group_replication_applier | 00023638-2222-2222-2222-222222222222 | 127.0.0.1 | 23638 | ONLINE | SECONDARY | 8.0.36 | XCom | | group_replication_applier | 00023639-3333-3333-3333-333333333333 | 127.0.0.1 | 23639 | UNREACHABLE | SECONDARY | 8.0.36 | XCom | +---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+----------------------------+ 3 rows in set (0.00 sec) |
Note – node3[127.0.0.1:23639] is showing “UNREACHABLE” however the node will be expelled/removed from the group after ~10 seconds because there is a 5 second waiting period as well before suspicion is created.
|
1 2 3 4 5 6 7 |
node1 [localhost:23637] {msandbox} ((none)) > select @@group_replication_member_expel_timeout; +------------------------------------------+ | @@group_replication_member_expel_timeout | +------------------------------------------+ | 5 | +------------------------------------------+ 1 row in set (0.00 sec) |
Note – In cases dealing with less stable/slow networks we can also increase the value of group_replication_member_expel_timeout to avoid unnecessary expulsions.
Finally, node3 does not appear anymore in the list.
|
1 2 3 4 5 6 7 8 |
node1 [localhost:23637] {msandbox} ((none)) > select * from performance_schema.replication_group_members; +---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+----------------------------+ | CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE | MEMBER_ROLE | MEMBER_VERSION | MEMBER_COMMUNICATION_STACK | +---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+----------------------------+ | group_replication_applier | 00023637-1111-1111-1111-111111111111 | 127.0.0.1 | 23637 | ONLINE | PRIMARY | 8.0.36 | XCom | | group_replication_applier | 00023638-2222-2222-2222-222222222222 | 127.0.0.1 | 23638 | ONLINE | SECONDARY | 8.0.36 | XCom | +---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+----------------------------+ 2 rows in set (0.00 sec) |
While looking over the node3 details it displays the “ERROR” and “Invalid Protocol”. The caveat here is if an application is still using this node it will serve the stall data. Well, we can change the behaviour using setting group_replication_exit_state_action if the node left the cluster/unable to join back.
|
1 2 3 4 5 6 7 |
node3 [localhost:23639] {msandbox} ((none)) > select * from performance_schema.replication_group_members; +---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+----------------------------+ | CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE | MEMBER_ROLE | MEMBER_VERSION | MEMBER_COMMUNICATION_STACK | +---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+----------------------------+ | group_replication_applier | 00023639-3333-3333-3333-333333333333 | 127.0.0.1 | 23639 | ERROR | | 8.0.36 | Invalid Protocol | +---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+----------------------------+ 1 row in set (0.00 sec) |
3. Now, we will remove that port[23764] blocking from node3 by flushing/clearing the rules.
|
1 |
shell> sudo pfctl -F all |
We can see node3 showing in RECOVERING mode, which resembles it doing some distributed recovery to accommodate the changes/sync up.
|
1 2 3 4 5 6 7 8 9 |
node3 [localhost:23639] {msandbox} ((none)) > select * from performance_schema.replication_group_members;; +---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+----------------------------+ | CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE | MEMBER_ROLE | MEMBER_VERSION | MEMBER_COMMUNICATION_STACK | +---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+----------------------------+ | group_replication_applier | 00023637-1111-1111-1111-111111111111 | 127.0.0.1 | 23637 | ONLINE | PRIMARY | 8.0.36 | XCom | | group_replication_applier | 00023638-2222-2222-2222-222222222222 | 127.0.0.1 | 23638 | ONLINE | SECONDARY | 8.0.36 | XCom | | group_replication_applier | 00023639-3333-3333-3333-333333333333 | 127.0.0.1 | 23639 | RECOVERING | SECONDARY | 8.0.36 | XCom | +---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+----------------------------+ 3 rows in set (0.00 sec) |
In the logs, we can verify that it is performing Incremental recovery from the donor. Well, if the missing transaction gap/threshold doesn’t reach the value of [group_replication_clone_threshold], the node tries to pull the data from the donor’s binary logs to perform the incremental recovery. In case the threshold is reached, a fully distributed recovery via the clone process will trigger. So, binary log retention is equally important to allow the data sync.
|
1 2 3 |
2024-08-18T11:24:32.268983Z 0 [System] [MY-013471] [Repl] Plugin group_replication reported: 'Distributed recovery will transfer data using: Incremental recovery from a group donor' ... 2024-08-18T11:28:48.898763Z 0 [System] [MY-011490] [Repl] Plugin group_replication reported: 'This server was declared online within the replication group.' |
Note – The default value[9223372036854775807] of group_replication_clone_threshold is very high and unrealistic so in the production environment it is better to consider some safe threshold so in case of missing binary logs the full distributed recovery doesn’t halt.
Once the recovery is finished the node3 appears ONLINE.
|
1 2 3 4 5 6 7 8 9 |
node1 [localhost:23637] {msandbox} ((none)) > select * from performance_schema.replication_group_members; +---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+----------------------------+ | CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE | MEMBER_ROLE | MEMBER_VERSION | MEMBER_COMMUNICATION_STACK | +---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+----------------------------+ | group_replication_applier | 00023637-1111-1111-1111-111111111111 | 127.0.0.1 | 23637 | ONLINE | PRIMARY | 8.0.36 | XCom | | group_replication_applier | 00023638-2222-2222-2222-222222222222 | 127.0.0.1 | 23638 | ONLINE | SECONDARY | 8.0.36 | XCom | | group_replication_applier | 00023639-3333-3333-3333-333333333333 | 127.0.0.1 | 23639 | ONLINE | SECONDARY | 8.0.36 | XCom | +---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+----------------------------+ 3 rows in set (0.02 sec) |
Scenario 2: Now, two of the GR nodes [node2 & node3] face some network interruption
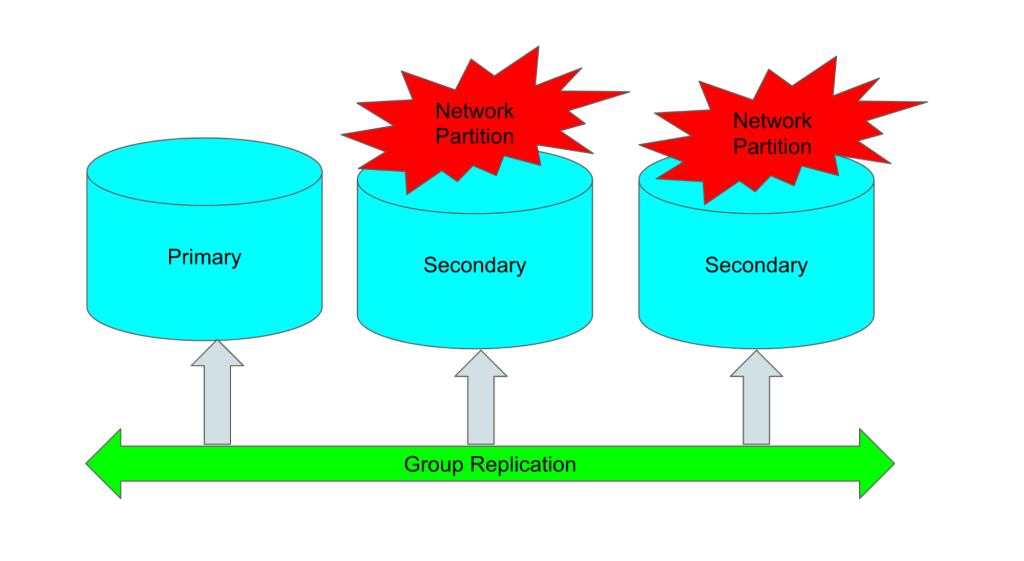
This diagram depicts multiple node failures.
1. Here again, we will block the group replication communication on ports[23763 & 23764 ] for both node3/node4.
Blocking communication:
|
1 |
shell> echo -e "block drop on lo0 proto tcp from 127.0.0.1 to 127.0.0.1 port 23763nblock drop on lo0 proto tcp from 127.0.0.1 to 127.0.0.1 port 23764" | sudo pfctl -ef - |
Verifying the rule:
|
1 |
shell> sudo pfctl -sr |
Output:
|
1 2 3 |
ALTQ related functions disabled block drop on lo0 inet proto tcp from 127.0.0.1 to 127.0.0.1 port = 23763 block drop on lo0 inet proto tcp from 127.0.0.1 to 127.0.0.1 port = 23764 |
2. Now, let’s verify the group status again from node1.
|
1 2 3 4 5 6 7 8 9 |
node1 [localhost:23637] {msandbox} ((none)) > select * from performance_schema.replication_group_members; +---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+----------------------------+ | CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE | MEMBER_ROLE | MEMBER_VERSION | MEMBER_COMMUNICATION_STACK | +---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+----------------------------+ | group_replication_applier | 00023637-1111-1111-1111-111111111111 | 127.0.0.1 | 23637 | ONLINE | PRIMARY | 8.0.36 | XCom | | group_replication_applier | 00023638-2222-2222-2222-222222222222 | 127.0.0.1 | 23638 | UNREACHABLE | SECONDARY | 8.0.36 | XCom | | group_replication_applier | 00023639-3333-3333-3333-333333333333 | 127.0.0.1 | 23639 | UNREACHABLE | SECONDARY | 8.0.36 | XCom | +---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+----------------------------+ 3 rows in set (0.01 sec) |
Now, do the same for node2.
|
1 2 3 4 5 6 7 8 9 |
node2 [localhost:23638] {msandbox} ((none)) > select * from performance_schema.replication_group_members; +---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+----------------------------+ | CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE | MEMBER_ROLE | MEMBER_VERSION | MEMBER_COMMUNICATION_STACK | +---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+----------------------------+ | group_replication_applier | 00023637-1111-1111-1111-111111111111 | 127.0.0.1 | 23637 | ONLINE | PRIMARY | 8.0.36 | XCom | | group_replication_applier | 00023638-2222-2222-2222-222222222222 | 127.0.0.1 | 23638 | ONLINE | SECONDARY | 8.0.36 | XCom | | group_replication_applier | 00023639-3333-3333-3333-333333333333 | 127.0.0.1 | 23639 | UNREACHABLE | SECONDARY | 8.0.36 | XCom | +---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+----------------------------+ 3 rows in set (0.01 sec) |
Finally, let’s check from node3’s perspective.
|
1 2 3 4 5 6 7 8 9 |
node3 [localhost:23639] {msandbox} ((none)) > select * from performance_schema.replication_group_members; +---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+----------------------------+ | CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE | MEMBER_ROLE | MEMBER_VERSION | MEMBER_COMMUNICATION_STACK | +---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+----------------------------+ | group_replication_applier | 00023637-1111-1111-1111-111111111111 | 127.0.0.1 | 23637 | UNREACHABLE | PRIMARY | 8.0.36 | XCom | | group_replication_applier | 00023638-2222-2222-2222-222222222222 | 127.0.0.1 | 23638 | UNREACHABLE | SECONDARY | 8.0.36 | XCom | | group_replication_applier | 00023639-3333-3333-3333-333333333333 | 127.0.0.1 | 23639 | ONLINE | SECONDARY | 8.0.36 | XCom | +---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+----------------------------+ 3 rows in set (0.00 sec) |
So here only node1 [127.0.0.1:23637] is ONLINE and in PRIMARY state, while each node has a different VIEW of the cluster.
As the cluster was not able to reach a majority, node1 could not continue further with any load/traffic.
|
1 |
2024-08-18T14:14:51.655814Z 0 [ERROR] [MY-011495] [Repl] Plugin group_replication reported: 'This server is not able to reach a majority of members in the group. This server will now block all updates. The server will remain blocked until contact with the majority is restored. It is possible to use group_replication_force_members to force a new group membership. |
Workload impacted:
|
1 2 3 4 |
[ 278s ] thds: 100 tps: 0.00 qps: 0.00 (r/w/o: 0.00/0.00/0.00) lat (ms,95%): 0.00 err/s: 0.00 reconn/s: 0.00 [ 279s ] thds: 100 tps: 0.00 qps: 0.00 (r/w/o: 0.00/0.00/0.00) lat (ms,95%): 0.00 err/s: 0.00 reconn/s: 0.00 [ 280s ] thds: 100 tps: 0.00 qps: 0.00 (r/w/o: 0.00/0.00/0.00) lat (ms,95%): 0.00 err/s: 0.00 reconn/s: 0.00 [ 281s ] thds: 100 tps: 0.00 qps: 0.00 (r/w/o: 0.00/0.00/0.00) lat (ms,95%): 0.00 err/s: 0.00 reconn/s: 0.00 |
3. Now, we will remove those ports [23763 & 23764] blocking from both node2/node3.
|
1 |
shell> sudo pfctl -F all |
4. After a few time frames, node2 and node3 joined the group with the usual recovery process.
|
1 2 3 4 5 6 7 8 9 |
node1 [localhost:23637] {msandbox} ((none)) > select * from performance_schema.replication_group_members; +---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+----------------------------+ | CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE | MEMBER_ROLE | MEMBER_VERSION | MEMBER_COMMUNICATION_STACK | +---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+----------------------------+ | group_replication_applier | 00023637-1111-1111-1111-111111111111 | 127.0.0.1 | 23637 | ONLINE | PRIMARY | 8.0.36 | XCom | | group_replication_applier | 00023638-2222-2222-2222-222222222222 | 127.0.0.1 | 23638 | ONLINE | SECONDARY | 8.0.36 | XCom | | group_replication_applier | 00023639-3333-3333-3333-333333333333 | 127.0.0.1 | 23639 | ONLINE | SECONDARY | 8.0.36 | XCom | +---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+----------------------------+ 3 rows in set (0.00 sec) |
There are some limits on how many attempts the expelled node tries to join the cluster. This is decided by the settings below. Group_replication_autorejoin_tries tells the number of tries (default ~3) that a member does to automatically rejoin the group if it is expelled/removed OR in case unable to contact a majority of the group.
|
1 2 3 4 5 6 7 |
node1 [localhost:23637] {msandbox} ((none)) > select @@group_replication_autorejoin_tries; +--------------------------------------+ | @@group_replication_autorejoin_tries | +--------------------------------------+ | 3 | +--------------------------------------+ 1 row in set (0.00 sec) |
After having an unsuccessful auto-rejoin attempt, the member waits ~five minutes before the next try. If the specified limit is exhausted without the member rejoining or being stopped, the member proceeds to the action specified by the group_replication_exit_state_action [ABORT_SERVER, OFFLINE_MODE, READ_ONLY] ]parameter.
|
1 2 3 4 5 6 7 |
node1 [localhost:23637] {msandbox} ((none)) > select @@group_replication_exit_state_action; +---------------------------------------+ | @@group_replication_exit_state_action | +---------------------------------------+ | READ_ONLY | +---------------------------------------+ 1 row in set (0.02 sec) |
In some situations, especially if the auto rejoins [Group_replication_autorejoin_tries], attempts are exhausted, and even fixing the network or other blockers, the node doesn’t auto rejoin the group members. In those scenarios, some manual intervention would be required like restarting the group replication or the database service itself.
E.g.,
|
1 2 |
mysql> stop group_replication; mysql> start group_replication; |
How long a member will wait, especially under the network partition when the majority will be lost, is decided by the “group_replication_unreachable_majority_timeout”. This specifies the number of seconds a member that suffers a network partition/is unable to reach out to the majority wait before leaving the group. The default value is set to 0, which means that members that find themselves in a minority due to a network partition wait forever to leave the group.
|
1 2 3 4 5 6 7 |
node1 [localhost:23637] {msandbox} ((none)) > select @@group_replication_unreachable_majority_timeout; +--------------------------------------------------+ | @@group_replication_unreachable_majority_timeout | +--------------------------------------------------+ | 0 | +--------------------------------------------------+ 1 row in set (0.00 sec) |
If you set any timeout and that time period elapses, all pending transactions processed by the minority nodes are rolled back, and the server will move to the ERROR state.
If we define a timeout for the above variable, the node in the minority group will leave the cluster. Unless we have the majority of nodes available, this parameter wouldn’t come into any effect. This is only applicable when the majority of members in the group have lost.
E.g.,
In a 3-node setup if we lose the two members and comprise the majority then based on the value of group_replication_unreachable_majority_timeout the action decided. Either the node will wait forever or leaves the group.
For testing purposes, we have set it to ~10 seconds so the node leaves the group after reaching the threshold.
|
1 2 3 4 5 6 7 |
node1 [localhost:23435] {msandbox} ((none)) > select @@group_replication_unreachable_majority_timeout; +--------------------------------------------------+ | @@group_replication_unreachable_majority_timeout | +--------------------------------------------------+ | 10 | +--------------------------------------------------+ 1 row in set (0.00 sec) |
|
1 |
2024-09-19T15:17:03.513110Z 0 [Warning] [MY-011499] [Repl] Plugin group_replication reported: 'Members removed from the group: 127.0.0.1:23435' |
Final thoughts:
So, in the above blog post we see how the network partition or interruption affects the group nodes and how the resilient behavior of group replication can help in adding the nodes back to the group again. We also discussed some important parameters that could affect the node expelled/rejoining process. Well, network partition has also a serious impact on the performance of the transactions/workload. It’s worth mentioning a performance problem reported here – https://bugs.mysql.com/bug.php?id=99133 by one of my colleagues, which highlights the dropout in write throughput when the network partition triggers among the group nodes. It seems this behavior is still the same and not fully solved.
MySQL Performance Tuning is our essential guide covering
the critical aspects of MySQL performance optimization.
Download the guide and unlock the full potential of your MySQL database today!
About the Author
 Anil Joshi
Anil JoshiI am Anil Joshi, and I work for Percona as a support engineer. I've worked with some well-known Open Source database technologies (MySQL/MariaDB, MongoDB, and Redis) for almost ten years. I am keenly interested in learning new databases and writing database content.





