

Innodb Cluster or ClusterSet topologies already have secondary instances that can act as a failover for primary or also offload read requests. However, with MySQL 8.4, we now have the feasibility of adding a separate async replica to the cluster for serving various special/ad-hoc queries or some reporting purposes. This will also help offload read traffic away from primary or secondary.
Let me now showcase the practical implementation and deployment of the read replica inside the InnoDB cluster. For demo purposes, I am deploying the instances using MySQL sandbox commands available with MySQL Shell.
Topology
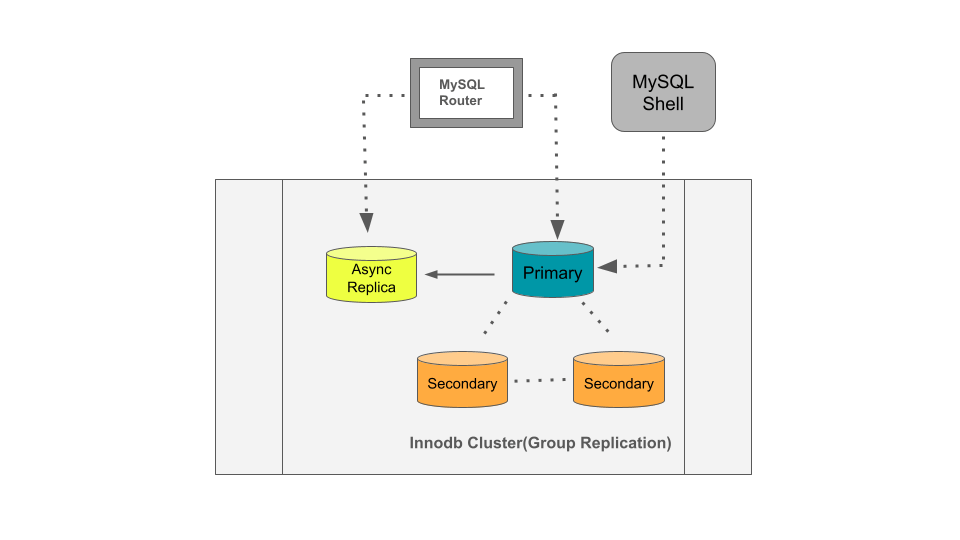
Async read replica auto source failover
-
InnoDB cluster nodes
|
1 2 3 |
MySQL JS > dba.deploySandboxInstance(3307) MySQL JS > dba.deploySandboxInstance(3308) MySQL JS > dba.deploySandboxInstance(3309) |
-
Async replica
|
1 |
MySQL JS > dba.deploySandboxInstance(3310) |
Quickly deploying InnoDB Cluster
|
1 2 3 |
|
1 2 3 |
|
1 2 3 |
Bootstrapping the first node
|
1 2 |
MySQL JS > cluster1 = dba.createCluster('Cluster1') |
Adding other nodes
|
1 2 |
Verifying cluster status
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
MySQL JS > cluster1.status() { "clusterName": "Cluster1", "defaultReplicaSet": { "name": "default", "primary": "127.0.0.1:3307", "ssl": "REQUIRED", "status": "OK", "statusText": "Cluster is ONLINE and can tolerate up to ONE failure.", "topology": { "127.0.0.1:3307": { "address": "127.0.0.1:3307", "memberRole": "PRIMARY", "mode": "R/W", "readReplicas": {}, "replicationLag": "applier_queue_applied", "role": "HA", "status": "ONLINE", "version": "8.4.5" }, "127.0.0.1:3308": { "address": "127.0.0.1:3308", "memberRole": "SECONDARY", "mode": "R/O", "readReplicas": {}, "replicationLag": "applier_queue_applied", "role": "HA", "status": "ONLINE", "version": "8.4.5" }, "127.0.0.1:3309": { "address": "127.0.0.1:3309", "memberRole": "SECONDARY", "mode": "R/O", "readReplicas": {}, "replicationLag": "applier_queue_applied", "role": "HA", "status": "ONLINE", "version": "8.4.5" } }, "topologyMode": "Single-Primary" }, "groupInformationSourceMember": "127.0.0.1:3307" } |
Adding async replica
Now we have the InnoDB cluster ready. Next, we can add the async replica.
Before adding the async replica, some prerequisites need to be met on the replica.
Prerequisites:
- It should be a standalone MySQL instance with version 8.0.23 or higher.
- There should be no unmanaged replication channels configured.
- The instance should have the same credentials as those used to manage the cluster.
- It is recommended you run “dba.checkInstanceConfiguration()” or “dba.configureInstance()” before attempting to create a Read Replica to have the same compatibility as Innodb cluster nodes.
|
1 2 |
Once all prerequisites are set, we can add the async replica by executing the below command on one of the InnoDB cluster nodes.
|
1 2 3 |
MySQL JS > c root@127.0.0.1:3307 MySQL JS > var cluster1 = dba.getCluster() MySQL JS > cluster1.addReplicaInstance('127.0.0.1:3310') |
Output:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
Please select a recovery method [C]lone/[A]bort (default Abort): c * Checking connectivity and SSL configuration... Monitoring Clone based state recovery of the new member. Press ^C to abort the operation. Clone based state recovery is now in progress. ... * Configuring Read-Replica managed replication channel... ** Changing replication source of 127.0.0.1:3310 to 127.0.0.1:3307 * Waiting for Read-Replica '127.0.0.1:3310' to synchronize with Cluster... ** Transactions replicated ############################################################ 100% '127.0.0.1:3310' successfully added as a Read-Replica of Cluster 'Cluster1'. |
By default the source node will be the Primary node (“127.0.0.1:3307”) of the cluster. In the cluster status, we can see the “readReplicas” section with the async node details.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
MySQL 127.0.0.1:3307 ssl JS > cluster1.status() { "clusterName": "Cluster1", "defaultReplicaSet": { "name": "default", "primary": "127.0.0.1:3307", "ssl": "REQUIRED", "status": "OK", "statusText": "Cluster is ONLINE and can tolerate up to ONE failure.", "topology": { "127.0.0.1:3307": { "address": "127.0.0.1:3307", "memberRole": "PRIMARY", "mode": "R/W", "readReplicas": { "127.0.0.1:3310": { "address": "127.0.0.1:3310", "role": "READ_REPLICA", "status": "ONLINE", "version": "8.4.5" } }, "replicationLag": "applier_queue_applied", "role": "HA", "status": "ONLINE", "version": "8.4.5" }, ... |
We can verify the source instance using the replication status command below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
MySQL 127.0.0.1:3310 ssl SQL > show replica statusG; *************************** 1. row *************************** Replica_IO_State: Waiting for source to send event Source_Host: 127.0.0.1 Source_User: mysql_innodb_replica_1145913617 Source_Port: 3307 Connect_Retry: 3 Source_Log_File: Anils-MacBook-Pro-bin.000002 Read_Source_Log_Pos: 68034 Relay_Log_File: Anils-MacBook-Pro-relay-bin-read_replica_replication.000002 Relay_Log_Pos: 4342 Relay_Source_Log_File: Anils-MacBook-Pro-bin.000002 Replica_IO_Running: Yes Replica_SQL_Running: Yes |
Now comes the good part. Suppose the primary goes down or switches to another secondary, and the async replica automatically switches to the next primary of the cluster.
Performing manual switchover over node (“127.0.0.1:3308”)
|
1 |
Output:
|
1 2 3 4 5 |
Setting instance '127.0.0.1:3308' as the primary instance of cluster 'Cluster1'... Instance '127.0.0.1:3309' remains SECONDARY. Instance '127.0.0.1:3308' was switched from SECONDARY to PRIMARY. Instance '127.0.0.1:3307' was switched from PRIMARY to SECONDARY. The instance '127.0.0.1:3308' was successfully elected as primary. |
The async replica automatically chooses the new primary/source.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
MySQL 127.0.0.1:3310 ssl SQL > show replica statusG; *************************** 1. row *************************** Replica_IO_State: Waiting for source to send event Source_Host: 127.0.0.1 Source_User: mysql_innodb_replica_1145913617 Source_Port: 3308 Connect_Retry: 3 Source_Log_File: Anils-MacBook-Pro-bin.000002 Read_Source_Log_Pos: 16638 Relay_Log_File: Anils-MacBook-Pro-relay-bin-read_replica_replication.000003 Relay_Log_Pos: 498 Relay_Source_Log_File: Anils-MacBook-Pro-bin.000002 Replica_IO_Running: Yes Replica_SQL_Running: Yes |
In the cluster status, we can see the “readReplicas” under the new primary now.
|
1 |
MySQL 127.0.0.1:3307 ssl JS > cluster1.status() |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
... "127.0.0.1:3308": { "address": "127.0.0.1:3308", "memberRole": "PRIMARY", "mode": "R/W", "readReplicas": { "127.0.0.1:3310": { "address": "127.0.0.1:3310", "role": "READ_REPLICA", "status": "ONLINE", "version": "8.4.5" } ... |
If we want the chosen source to be a secondary rather than a primary, we can define “replicationSources” as “secondary.” In this case, the async will always fail over to one of the secondary instead of the primary.
E.g.,
|
1 2 |
MySQL 127.0.0.1:3307 ssl JS > cluster1.addReplicaInstance('127.0.0.1:3310',{label: 'RReplica1', replicationSources: 'secondary'}) |
We can get more information like label, replication source type, etc, with the help of the below command.
|
1 |
MySQL 127.0.0.1:3307 ssl JS > cluster1.describe() |
|
1 2 3 4 5 6 7 8 9 10 |
… "address": "127.0.0.1:3310", "label": "RReplica1", "replicationSources": [ "SECONDARY" ], "role": "READ_REPLICA" } … |
Monitoring
Under performance_schema and mysql database, we have tables (replication_asynchronous_connection_failover & replication_asynchronous_connection_failover_managed) which basically keep the source node information and also update it when the cluster topology changes and the source has to be changed for the async replica. Currently, we see a high weight (“80”) for secondary nodes, as the source will be decided among them only.
|
1 2 3 4 5 6 7 8 9 |
mysql> select * from replication_asynchronous_connection_failover; +--------------------------+-----------+------+-------------------+--------+--------------------------------------+ | Channel_name | Host | Port | Network_namespace | Weight | Managed_name | +--------------------------+-----------+------+-------------------+--------+--------------------------------------+ | read_replica_replication | 127.0.0.1 | 3307 | | 80 | 4f1b10ee-2192-11f0-b039-52041b7c2028 | | read_replica_replication | 127.0.0.1 | 3308 | | 60 | 4f1b10ee-2192-11f0-b039-52041b7c2028 | | read_replica_replication | 127.0.0.1 | 3309 | | 80 | 4f1b10ee-2192-11f0-b039-52041b7c2028 | +--------------------------+-----------+------+-------------------+--------+--------------------------------------+ 3 rows in set (0.01 sec) |
|
1 2 3 4 5 6 7 |
mysql> select * from replication_asynchronous_connection_failover_managed; +--------------------------+--------------------------------------+------------------+------------------------------------------------+ | Channel_name | Managed_name | Managed_type | Configuration | +--------------------------+--------------------------------------+------------------+------------------------------------------------+ | read_replica_replication | 4f1b10ee-2192-11f0-b039-52041b7c2028 | GroupReplication | {"Primary_weight": 60, "Secondary_weight": 80} | +--------------------------+--------------------------------------+------------------+------------------------------------------------+ 1 row in set (0.00 sec) |
For the rest, we can track the async node information via cluster commands like “cluster.status()” and “cluster.describe(),” as we saw in the implementation above.
Traffic routing
MySQLRouter comes very handy when we talk about sending read-only traffic (ad-hoc, reporting, etc) to these async nodes. First, we can set up an account for the MySQL router service.
|
1 |
MySQL 127.0.0.1:3307 ssl JS > cluster1.setupRouterAccount('router_usr') |
Then, we can bootstrap the mysqlrouter with our existing cluster information and start the service.
|
1 |
shell> mysqlrouter --bootstrap root@127.0.0.1:3307 --account=router_usr --name='Router1' --force |
|
1 |
shell> mysqlrouter -c /opt/homebrew/Cellar/mysql@8.4/8.4.5/mysqlrouter.conf & |
Below are the read & write endpoints available under both Classic and X protocols.
|
1 2 3 4 5 6 7 8 9 10 |
## MySQL Classic protocol - Read/Write Connections: localhost:6446 - Read/Only Connections: localhost:6447 - Read/Write Split Connections: localhost:6450 ## MySQL X protocol - Read/Write Connections: localhost:6448 - Read/Only Connections: localhost:6449 |
Here is the router(“Router1”) information.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
MySQL 127.0.0.1:3307 ssl JS > cluster1.listRouters() { "clusterName": "Cluster1", "routers": { "Anils-MacBook-Pro.local::Router1": { "hostname": "Anils-MacBook-Pro.local", "lastCheckIn": "2025-04-25 19:37:15", "roPort": "6447", "roXPort": "6449", "rwPort": "6446", "rwSplitPort": "6450", "rwXPort": "6448", "version": "8.4.5" } } } |
Next, we need to set the setRoutingOption() as below so the read-only traffic goes to the read replicas connected via the “Router1″ service.
|
1 |
MySQL 127.0.0.1:3307 ssl JS > cluster1.setRoutingOption("Anils-MacBook-Pro.local::Router1", "read_only_targets", "read_replicas") |
Output:
|
1 |
Routing option 'read_only_targets' successfully updated in router 'Anils-MacBook-Pro.local::Router1'. |
Finally, we can verify the “routingOptions()” status as below.
|
1 |
MySQL 127.0.0.1:3307 ssl JS > cluster1.routingOptions("Anils-MacBook-Pro.local::Router1") |
Output:
|
1 2 3 4 5 |
{ "Anils-MacBook-Pro.local::Router1": { "read_only_targets": "read_replicas" } } |
For the connection test, we can simply connect to the router service over read-only port 6447.
|
1 |
shell> mysql -h 127.0.0.1 -uroot -p -P6447 -e "select 1"; |
Recovery of the async replica
If the async replica somehow disconnected from the source node or broke due to some unfixable errors, then we can try rejoining the instance via the “rejoinInstance()” function. Based on the necessity, we can try both incremental and full recovery via clone.
|
1 |
MySQL 127.0.0.1:3308 ssl JS > cluster.rejoinInstance("127.0.0.1:3310") |
Output:
|
1 2 3 4 5 6 7 8 |
Rejoining Read-Replica '127.0.0.1:3310' to Cluster 'Cluster1'... ... Incremental state recovery was selected because it seems to be safely usable. ** Changing replication source of 127.0.0.1:3310 to 127.0.0.1:3308 * Waiting for Read-Replica '127.0.0.1:3310' to synchronize with Cluster... ** Transactions replicated ############################################################ 100% |
Final thought
Setting up and managing isolated read replicas is quite easy and handy under the Innodb Cluster and ClusterSet ecosystem. We can also use a dedicated routing endpoint and leverage MySQLrouter to distribute read traffic over different replicas. This allows the main cluster secondary nodes to be focused on handling more critical production workloads and maintaining high availability by diverting the less critical workload to the async nodes.

About the Author
 Anil Joshi
Anil JoshiI am Anil Joshi, and I work for Percona as a support engineer. I've worked with some well-known Open Source database technologies (MySQL/MariaDB, MongoDB, and Redis) for almost ten years. I am keenly interested in learning new databases and writing database content.





