

- Is your PostgreSQL database Feeling Sluggish? Are SQL statements taking more time than in earlier days?
- Are you experiencing performance cliffs (Unexpected, sudden drops in performance)?
- Are backups taking a long time to complete? Are you getting a bigger bill for storage?
- Are standby rebuilds and development refreshes becoming a herculean task? Are the auditors raising concerns about data retention?
- Afraid that a database restore may cause unacceptable downtime?
If yes, it’s time for a Data Clean-Up! – The Data Retention Policy implementation.
I usually say: Ever-growing database is not sustainable. But cancerous.
As applications run for a long time, their databases get huge. This uncontrolled growth becomes a serious problem. Large tables and indexes become uncacheable, resulting in high I/O, which slows down the entire system, frustrates users, and costs the business money. Basic tasks, such as backups and maintenance, also become slow, difficult, and expensive.
Such ever-growing tables are easy to spot. Here is an example from a pg_gather report of a regular table receiving a large number of INSERTS per day, But No DELETEs.
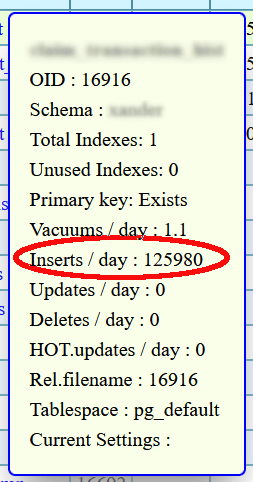
This is especially true for data like logs, where old, useless information clogs the system and slows down access to new data.
Without a plan, the database becomes the system’s biggest bottleneck. Therefore, managing data growth is crucial to maintaining the application’s health and availability. Removing old and obsolete data from the database is as important as a drainage system for a City and Kidneys for the human body; without it, the system collapses.
Regulatory and Legal Implications
In addition to performance and cost implications mentioned above, holding old and obsolete data can have legal and regulatory implications.
When Big data breach/leak incidents get reported, like this recent one https://cybersecuritynews.com/ey-data-leak/.The first question which comes to mind is, why do they hold this much information? An organisation will be responsible for every piece of information that it holds.
GDPR clearly mandates with clauses like “identification of data subjects for no longer than is necessary for the purposes for which the personal data are processed” [1]
There are major provisions like Right to Erasure (Article 17) Also known as the “Right to be Forgotten.”. There are other regulations like CCPA/CPRA, SOX, FINRA, MiFID II, HIPAA , PCI DSS, which provide guidelines for data retention.
In summary : You must only collect and retain data that is strictly necessary, for as long as necessary. At the end of the retention period, data must be disposed of securely and irreversibly
Implementation Strategies
Purging (Deletion): Physically removing the data from the database. The data which must be deleted can be permanently removed from the database. Just marking for deletion may not be sufficient.
Archiving & Anonymization: Moving data to a separate, secure archive, warehouse and/or removing all identifying elements so the data is no longer “personal data” but can be used for analytics. Many of the analytical systems need only summarised data. So regular ETL methods can be used.
Moving the data from the main transaction tables to separate archive tables is also a common strategy.
Planning: Key Factors to Consider Before You Begin
1. Table partitioned or not
Ideally, Data retention policy should be part of the core design of every system. If that is considered during the design phase of the system, tables could be designed and partitioned to facilitate the easy removal of old data. Partitions which hold the obsolete data can be just dropped off.
As the PostgreSQL documentation [2] explains
“Dropping an individual partition using DROP TABLE, or doing ALTER TABLE DETACH PARTITION, is far faster than a bulk operation. These commands also entirely avoid the VACUUM overhead caused by a bulk DELETE.”
PostgreSQL supports DETACH ing a Partition from a table and ATTACH ing that partition to another table. This is the easiest way to achieve data archiving if the archive table is maintained on the same database.
Even though it’s simple and straightforward to DETACH or DROP partitions explicitly or using custom scripts, Extensions like pg_partman can be used for retention management. Other specialised extensions also contain features for implementing data retention policies.
If partitioning features can be used for retention management, most of the points discussed in the following sections may not be applicable.
2. Need for DELETE statement
If the table where the Retention policy needs to be implemented is not designed/partitioned, OR if there is complex logic to identify the candidate records, we may have to run regular DELETE statements. As mentioned above it is comparatively costly to run DELETE statements rather than just dropping the partition. High WAL generation, Fragmentation / Bloat, High Autovacuum activity, etc, are expected.
3. Indexes on the Table
Indexes show their strong negative aspects when DML statements like DELETE run on a table. I want to avoid repeating all those in this post, because all negative aspects of Indexes were discussed in a different blog post: PostgreSQL Indexes Can Hurt Performance, and there is an additional benchmark by Pablo Svampa on this: The Hidden Cost of Over-Indexing. The higher the number of indexes, the heavier the DELETE is expected to be.
4. Referential Integrity checks
This is one of the most common factors which is often overlooked. If DELETE need to run on a table which is referenced by other tables, all those integrity checks will be fired for each row involved. On the other hand, if the DELETE statement is running on a table which refers to other tables, a shared lock will be placed on all those referenced tables. This may lead to increased Mutixid generation and use.
5. Triggers
We should be checking whether any of the triggers get fired on DELETE statements. If yes, that may need a detailed investigation. Because Triggers could be inserting/copying data to some other tables. Using triggers for generating audit records is a common practice by many architects
6. Wide Rows
The physical size of the rows in a table, often referred to as the “row width,” plays a significant role in the performance of data retention operations. A wider row, which contains more columns or columns with large data types (such as TEXT, BYTEA, or JSONB), will occupy more space on disk and in memory. These variable-sized datatypes are generally stored in a separate table-like structure called TOAST. So a DELETE has to take care of the table and the associated TOAST. This has several implications for a Data Retention Policy. First, when deleting wide rows, the database has to read and write more data for each row that is removed. This increases the I/O load and can slow down the deletion process. Second, wider rows mean that fewer rows can fit into a single database page (typically 8KB in PostgreSQL). This can lead to more page reads and writes during the deletion process, further increasing I/O contention.
7. Volume and Records of Data to be Removed
Before executing a Data Retention Policy, it is crucial to have a clear understanding of the volume of data that will be affected. This involves not only counting the number of rows that will be deleted but also estimating the total amount of disk space that will be freed up. This information is essential for planning the deletion process, assessing its potential impact on the system, and verifying its success afterwards. To estimate the number of rows to be deleted, you can run a SELECT COUNT(*) query with the same WHERE clause that you plan to use in your DELETE statement. This will give you a precise count of the rows that match your deletion criteria. For example, SELECT COUNT(*) FROM logs WHERE log_date < '2023-01-01' will tell you exactly how many old log entries you are about to remove. Considering the factors like the current size of the table, current bloat, number of live tuples, and number of tuples to be deleted, can give us a rough estimate of the size of the purge activity.
8. Understanding Checkpoints and Their Impact
A checkpoint is a point in time at which the database guarantees that all data changes committed up to that point have been written from the buffer cache to permanent storage on disk. This process is essential for crash recovery, as it establishes a known good state from which the database can be restored in the event of a failure. However, the process of writing all the dirty (modified) pages from the buffer cache to disk can be a very I/O-intensive operation.
If a large number of pages have been modified since the last checkpoint, the checkpoint process can cause a sudden increase in I/O activity, which can slow down other queries and degrade the overall system performance. During a large deletion operation, a massive amount of WAL is generated, which can cause checkpoints to occur more frequently than usual. This can lead to a phenomenon known as “checkpoint saturation,” where the system is constantly busy writing dirty pages to disk, leaving little I/O capacity for other tasks. There will be Full Page Writes after each checkpoint, which further amplify the I/O activity. I discussed this problem in a previous blog post which discusses the WAL Compression in PostgreSQL
Therefore, before the bulk purging activity, it is crucial to ensure that checkpointing is tuned to a level where there won’t be back-to-back, frequent checkpointing during the DELETE run.
9. Long-Running Transactions
When implementing a Data Retention Policy, it is generally advisable to avoid long-running transactions, especially those that span multiple checkpoints. A long-running transaction can have several negative consequences on the performance and stability of the database. First, it can hold locks on the rows or tables it is modifying for an extended period, which can block other queries and lead to lock contention. So the Purge activities need to be planned for a time window with fewer long-running transactions. Preferably, an off-peak time.
Moreover, the purge job we create shouldn’t become another long-running statement. So we need to divide the activity into small batches. The purge (DELETE) activity is expected to generate a large number of dead tuples. Long-running transactions will prevent autovacuum from cleaning up these dead tuples.
10. Current Replication/Standby configuration and behaviour.
The puge (DELETE) activity is expected to generate large volumes of WAL files. The impact on replication/standby depends on the configuration and current standby behaviour. For example, if there is any Synchronous replication, Bulk WAL generation can result in a notorious IPC::SyncRep wait event. Since there is already a lot of material about this IPC::SyncRep problem and associated severe performance degradation, I am not repeating it here. If there is already high latency or lag with the standby, the impact will be much more severe. There were many incidents where the standby went out of sync due to purge activity
11. Logical replication and its impact.
Logical replication is much heavier than physical replication by its very design. The publisher has to do the logical decoding, which involves the commit reordering. This happens because everything gets recorded in the same WAL stream / WAL files. When you execute a DELETE statement on the primary (publisher) database, each deleted row is recorded in the Write-Ahead Log (WAL) as a separate logical replication message. These messages are then sent to the replica (subscriber) database, where they apply the changes to its own copy of the data. If you perform a bulk delete that removes a large number of rows, this can generate a massive amount of WAL traffic, which can overwhelm the replication stream and cause significant replication lag.
Strategies
Since there are many factors as explained in the previous section, the Same strategy won’t work for all systems and cases of purging (DELETE) activity. However, at least it will be clear that a single bulk DELETE operation is not desirable in most cases and should be performed in multiple batches. It is essential to allow a time gap between each batch operation for cases where autovacuum or replication struggle to catch up.
Sample Implementations of Purging
Simple, sample statements may help you to get started. There is no single solution which works best for all cases.
As mentioned long-running statement could adversely affect many parts of the system. Therefore, we need protection to prevent us from causing a long-running statement. PostgreSQL allows this using statement_timeout parameter. I don’t prefer a statement to take more than 5 minutes. I would suggest having this setting for the session which is going to perform the purge activity.
|
1 |
set statement_timeout = '300s'; |
With this setting in place, if any statement crosses 5 minutes, it will be cancelled with an error as follows
|
1 |
ERROR: canceling statement due to statement timeout |
The purge statement DELETE can be as simple as
|
1 2 3 4 5 6 7 8 |
WITH delctid AS ( SELECT ctid FROM table_a WHERE ts < '2016-01-05 00:01:00+00' LIMIT 100000 FOR UPDATE SKIP LOCKED) DELETE FROM table_a USING delctid WHERE table_a.ctid = delctid.ctid; |
Let me explain why CTE is used and why it is recommended.
The first reason is that the DELETE statement cannot have a LIMIT clause. CTE can be used to work around this limitation. Another major reason is to use the SELECT statement to scan the table, apply the LIMIT clause, and take a lock on the rows/tuples that will be affected using the “FOR UPDATE” clause. The additional “SKIP LOCKED” clause serves as a safety mechanism in case conflicting sessions are working on those rows/tuples. Overall, this works as a pre-filtering before the DELETE part.
CTEs help the users to have explicit sort and filter orders. The EXPLAIN ANALYZE makes it clear
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
Delete on table_a (cost=6250303.20..6371578.20 rows=0 width=0) (actual time=31625.841..31625.879 rows=0 loops=1) CTE delctid -> Limit (cost=0.00..6250303.20 rows=30000 width=12) (actual time=0.742..31618.652 rows=5760 loops=1) -> LockRows (cost=0.00..6250303.20 rows=30000 width=12) (actual time=0.741..31618.396 rows=5760 loops=1) -> Seq Scan on table_a table_a_1 (cost=0.00..6250003.20 rows=30000 width=12) (actual time=0.256..31614.723 rows=5760 loops=1) Filter: (ts < '2016-01-05 00:01:00+00'::timestamp with time zone) Rows Removed by Filter: 299994240 -> Nested Loop (cost=0.00..121275.00 rows=30000 width=36) (actual time=0.905..31622.581 rows=5760 loops=1) -> CTE Scan on delctid (cost=0.00..600.00 rows=30000 width=36) (actual time=0.890..31620.067 rows=5760 loops=1) -> Tid Scan on table_a (cost=0.00..4.01 rows=1 width=6) (actual time=0.000..0.000 rows=1 loops=5760) TID Cond: (ctid = delctid.ctid) Planning Time: 0.743 ms Execution Time: 31626.235 ms (13 rows) |
Even though this example uses the ctid to make it generic, any key columns will be a great option. At least in a few cases, key columns showed better performance if indexes are involved.
For those new to PostgreSQL: The ctid is a system column present in every table that identifies the physical location of a specific row version (known as a “tuple”) within its table. Think of it as the row’s physical disk address. It’s the fastest possible way to access a single, specific row if you already know its ctid
There can be complex logic implemented using CTE, for example, “Delete those records which are not logically referenced by any of the records in another table, but no formal foreign keys doesn’t exist”. MATERIALIZED or NOT MATERIALIZED clauses can be used to control the planner. In summary, test the execution plan using a SELECT statement instead of a DELETE statement and make sure that it completes in the time (say, less than 4 minutes)
What if we need to copy the data to another archive table or a remote foreign table as part of purging the data from the main transaction table?
Here is a quick example:
|
1 2 3 4 5 |
WITH rows AS ( DELETE FROM pgbench_accounts WHERE aid < 10000 RETURNING *) INSERT INTO pgbench_accountsarchives SELECT * FROM rows; |
The “RETURNING” clause gives all the rows which are deleted. The Same can be INSERTED into another table. Since a statement is atomic by default, we can be sure that all those rows which are deleted are inserted into the archive table.
What if we manage a Warehouse system where all the old data is collected?
The MERGE statement available in modern SQL is sufficient. Yes single statement is enough. Which is a different topic than this blog objective.
Once we crafted a DELETE statement for a specific purge activity, it needs to be executed in a loop again and again, until all the records/tuples are purged or moved to a different table. Once we review all the factors, we may come to the conclusion whether there should be a delay between each execution or not. Most importantly, what should be the batch size for each table
Properly planning and architecting the database, including Partitions and necessary provisions to maintain retention, is key. But if such things do not exist, running DELETE statements is the option. Avoid bulk deletes; instead, divide them into smaller batches.
Additional References
[1] https://gdpr-info.eu/art-5-gdpr/
[2] https://www.postgresql.org/docs/16/ddl-partitioning.html
About the Author
 Jobin Augustine
Jobin AugustineJobin Augustine is a PostgreSQL expert, enthusiast, and Open Source advocate with more than 25 years of experience as a consultant, architect, administrator, writer, developer, and trainer. He is an active participant in Open Source communities, with a primary focus on database performance and optimization. A contributor to various open-source projects and an active blogger, Jobin also loves to code in C++ and Python. He is a senior member of the PostgreSQL community in India and a regular speaker at many international conferences. Jobin holds a Master’s in Computer Applications from NIT Calicut. He joined Percona in 2018 to launch their PostgreSQL chapter and currently serves as the Tech Lead for PostgreSQL. Prior to Percona, he worked at OpenSCG as an architect and was part of the BigSQL core team. His earlier career includes a decade-long tenure at Dell as a Senior Database Advisor, along with roles at several other technology firms.





