

Recently I listened to Lenny Rachitsky’s podcast, where he invited Shreyas Doshi for the second time. The session was titled “4 questions Shreyas Doshi wishes he’d asked himself sooner”. One of the questions Shreyas brought up was, “Do I actually have a good taste?”. This is an interesting question to ask for an experienced product leader. Having taste is about “the ability to identify what is really good, without needing to see its results.” It is easy to say today that GenAI is a hot technology; you don’t need to have good taste for it. But saying this 5-10 years ago, predicting the patterns would definitely require good visionary taste.
These were my thoughts when I was talking to users about databases on Kubernetes during the Kubecon in Utah two weeks ago. These conversations were not new to me, but both quantity and quality evolved greatly.
When I joined Percona more than four years ago, I was running and building various Platforms-as-a-Service, including Kubernetes and DBaaS. The mindset was that K8s was for stateless workloads only. This was for various reasons: immature storage, lack of proper support from vendors, and 12-factor app framework.
Joining Percona was sort of a challenge for me, as I had an idea to run databases on Kubernetes, which is the product to run. Back in the day, technology choices were limited; using helm charts was the norm, and only a few looked at “still not so mature” Operators.
So users had both immature storage implementation in Kubernetes itself and quite limited technology choices. And that was understandable, as the demand curve for running stateful apps in k8s (and even in containers) was at its lowest point. Thinking about product taste, it was already stated that Kubernetes is much more than just an orchestrator, but a platform to build platforms. Yet, the belief that it would be a home for stateful applications was not on the horizon.
Evolution
We can see the evolution of stateful applications on Kubernetes through various data points.
Operatorhub
Operatorhub is the registry of Kubernetes Operators. It appeared in 2019. From seven operators for databases at the start, today it has 50. Among the first vendors were Percona, CrunchyData, PlanetScale (Vitess), MongoDB, and Redis.
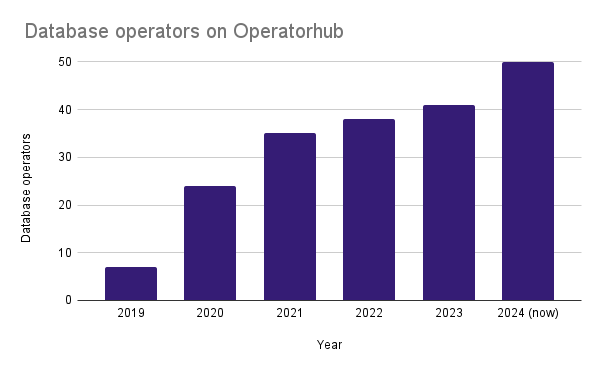
It is also interesting to look at Operator Capability Levels. Here is how they were changing year over year:
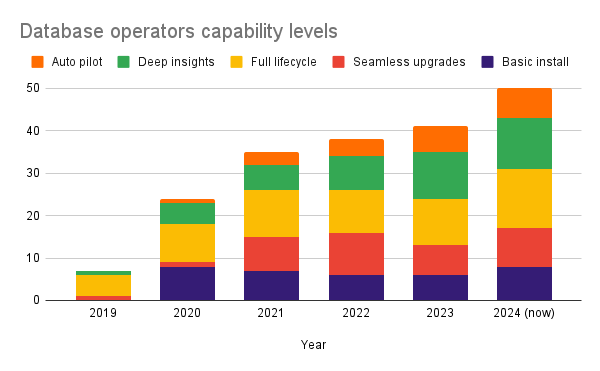
There is an expectation that more Operators will eventually reach maturity levels and get to the autopilot level.
Community
Data on Kubernetes Community (DoKC) was founded in August 2020. It facilitates the creation and sharing of best practices for users to advance in their DoK journey. Since its inception, the community has shown steady growth and has become a source of information and truth for many users who are running stateful workloads on k8s.
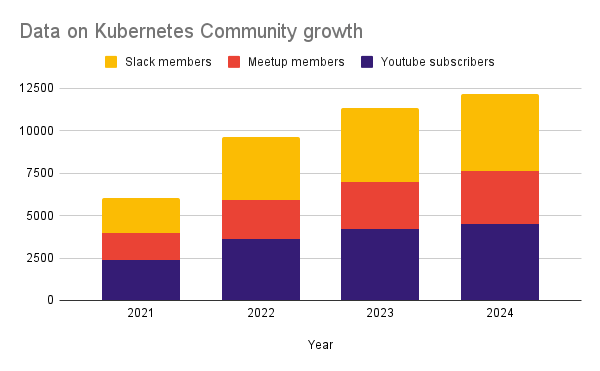
DoK started releasing annual reports in 2021. Since then, it has been a tradition to release the results during KubeCon NA, which usually happens in November. Find reports here: 2021, 2022, 2024. In 2023, instead of a report, DoK released a whitepaper about Database Patterns on k8s.
In the 2024 report you will spot a trend of maturation of DoK. More and more organizations are running stateful workloads in Kubernetes, and its percentage is growing:
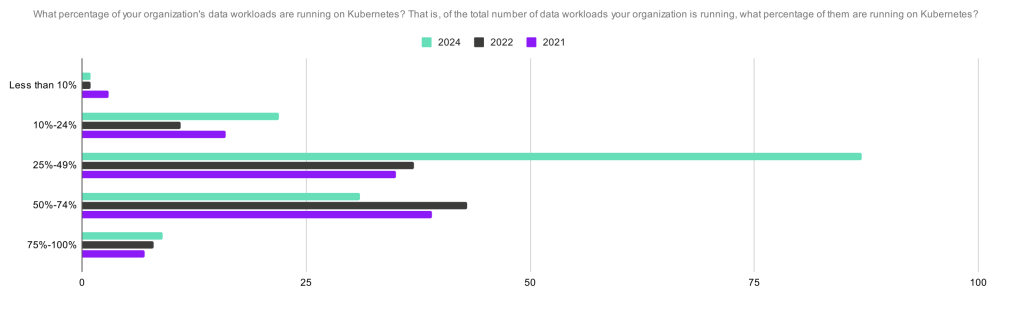
But also Databases are the #1 in the DoK workload types for three consecutive years:
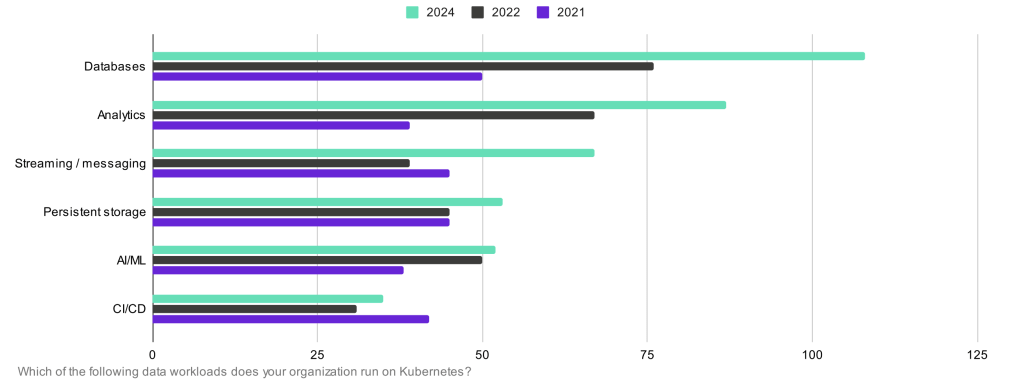
And it is quite interesting to see how it correlates with what Datadog captured in their report: databases and web servers are the leading workload categories for containers.
Adoption
As with most open source products, we capture anonymous telemetry in Percona operators. Mostly we learn how many clusters were deployed and which key features are in use, this helps us to collaborate with the community better and focus on the things that really matter. Telemetry, of course, can be disabled and does not work in air-gapped environments.
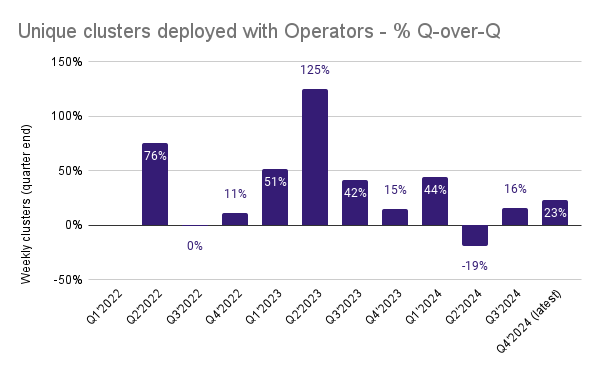
With the exception of the second quarter of 2024, we see steady growth in the number of unique clusters deployed across all our Operators.
AI angle
Artificial intelligence is the new buzz. AI and machine learning technologies are blooming, and it is not a surprise that we also see it in the database world. According to the DoK 2024 report:
Organizations are increasingly viewing Kubernetes for AI/ML workloads as a competitive advantage, with a majority agreeing that it will serve as a key platform for accelerating their AI strategy.
For databases, we see an increased interest in vector solutions, which are important to support the business retrieval-augmented generation (RAG) journey. Among new technologies like Milvus (it also has a k8s operator), established database vendors introduce vector search capabilities into their core:
- pgvector in PostgreSQL (read in our blog how it can be used with Percona Operator)
- Various solutions for MySQL:
- Oracle’s implementation in MySQL (Only heatwave and enterprise, though.)
- mysql_vss plugin by Spotify
- MongoDB Atlas Vector Search
- Even Redis vector database
Projects like Kubeflow are pushing AI/ML on Kubernetes even further and showing steady growth in production (almost doubling it since 2021; read more).
The rise of AI/ML on Kubernetes has significant implications for databases. We can expect to see increased demand for operators that seamlessly integrate with AI/ML workflows, enabling features like automated scaling and optimized resource allocation for model training and inference. Additionally, tools will likely emerge to streamline the deployment and management of specialized database technologies like vector databases, further simplifying the development and operation of AI-powered applications on Kubernetes.
User experience is important
In my talk at KubeCon, I looked at how databases on k8s were deployed in the past (YAML, helm), now (Operators), and what the future holds. Let’s be honest: Kubernetes is a complex beast. Adding databases on top of it, even with the support of Operators, may lead you to the dark corners of troubleshooting. Also, a vast and expanding Cloud Native ecosystem requires you to build your own castle (Database-as-a-Service) using various building blocks.
But what if this complexity is taken away? This is where we believe the future is, where the open source community can leverage a tool that allows you to deploy and manage databases with ease without the need to go deep into the woods of the ecosystem. I know at least about two solutions in the open source world:
Both solutions allow you to deploy multiple open source databases and are Kubernetes-focused. They provide simple UI and API interfaces rather than directly interacting with K8s API.
There are also Operators that have built-in UI – StackGres and Zalando postgres-operator, but they are single-tech focused – PostgreSQL.
Conclusion
The evolution is clear: Kubernetes has matured beyond stateless applications, becoming a robust platform for stateful workloads, particularly databases. The Data on the Kubernetes Community’s growth and the increasing sophistication of operators demonstrate this shift. As AI/ML adoption accelerates and technologies like vector databases gain traction, Kubernetes is poised to become even more critical for data-intensive applications. This ongoing evolution presents exciting opportunities for developers, platform engineers, and organizations alike to innovate and optimize their data infrastructure.
Percona is committed to supporting you in your Cloud Native journey. Try our open source Operators for MySQL, MongoDB, and PostgreSQL, or Percona Everest, which simplifies database deployment and management in any Kubernetes environment.
About the Author
 Sergey Pronin
Sergey ProninSergey is a product leader at Percona focusing on delivering robust open-source database and cloud-native solutions. Prior to Percona Sergey led product management and engineering teams in other organizations with a primary focus on products in infrastructure and platforms space.





Great article, Sergey!
The talk you mentioned is also great https://www.youtube.com/watch?v=0gSSmdNB-Zo