

There are quite a number of methods these days for installing Patroni. I want to discuss the next step, which is how to start tuning a running system.
The manner of updating a running Postgres server typically involves editing the standard Postgres files:
- postgresql.conf
- postgresql.auto.conf
- pg_hba.conf
Working with a Patroni HA cluster, one has the added ability to tune both individual hosts and simultaneously across the entire cluster.
For the purposes of demonstration, I’m using Spilo, which is a docker image of an HA PostgreSQL cluster and consists of the following:
- HAPROXY: 1 node
- ETCD: 3 nodes
- PostgreSQL: 3 nodes
- PRIMARY: 1 node
- REPLICA: 2 nodes

The first step is, of course, to download and install SPILO:
|
1 2 3 4 5 |
sudo snap install docker git clone https://github.com/zalando/patroni.git cd patroni docker build -t patroni . docker compose up -d |
Once installed, you can stop and restart with the following commands:
|
1 2 |
docker compose -f /root/patroni/docker-compose.yml start docker compose -f /root/patroni/docker-compose.yml stop |
Next, query the system in order to identify the entry points:
|
1 |
docker ps -a |
|
1 2 3 4 5 6 7 8 |
CONTAINER ID IMAGE COMMAND CREATED STATUS NAMES 34e6cc709361 patroni "/bin/sh /entrypoint..." 14 minutes ago Up 10 minutes demo-patroni2 848177ca9509 patroni "/bin/sh /entrypoint..." 14 minutes ago Up 10 minutes demo-etcd2 cc94547ee3dc patroni "/bin/sh /entrypoint..." 14 minutes ago Up 10 minutes demo-patroni3 28f270af156a patroni "/bin/sh /entrypoint..." 14 minutes ago Up 10 minutes demo-patroni1 c05d59db4896 patroni "/bin/sh /entrypoint..." 14 minutes ago Up 10 minutes demo-haproxy e9db2b735a2a patroni "/bin/sh /entrypoint..." 14 minutes ago Up 10 minutes demo-etcd1 2749a600952f patroni "/bin/sh /entrypoint..." 14 minutes ago Up 10 minutes demo-etcd3 |
Logging into any of the Postgres containers, or even the haproxy container itself, allows me to identify the PRIMARY node. Typically, patronictl requires an argument to the configuration file but not on SPILO.
|
1 2 |
docker exec -ti demo-haproxy bash patronictl list |
In my case, my PRIMARY is currently set on member “patroni2”. Note that the name of this Patroni cluster is demo:
|
1 2 3 4 5 6 7 |
+ Cluster: demo (7373687402552852504) --------+----+-----------+ | Member | Host | Role | State | TL | Lag in MB | +----------+------------+---------+-----------+----+-----------+ | patroni1 | 172.18.0.8 | Replica | streaming | 2 | 0 | | patroni2 | 172.18.0.4 | Leader | running | 2 | | | patroni3 | 172.18.0.2 | Replica | streaming | 2 | 0 | +----------+------------+---------+-----------+----+-----------+ |
FYI, one can locate the Patroni configuration file thusly:
|
1 2 |
docker exec -ti demo-patroni2 bash ps aux | grep patroni | head -n 1 |
In this case, the configuration file is postgres0.yml:
|
1 2 |
postgres@patroni2:~$ ps aux| grep patroni | head -n 1 1 postgres dumb-init python3 /patroni.py postgres0.yml |
In order to update runtime parameters across the entire cluster, one can use the Patroni REST API. In this case, though, the patronictl edit-config tool is demonstrated editing changes to the cluster’s Distributed Configuration Store (DCS):
|
1 2 3 4 5 6 7 8 |
patronictl edit-config [ CLUSTER_NAME ] [ --group CITUS_GROUP ] [ { -q | --quiet } ] [ { -s | --set } CONFIG="VALUE" [, ... ] ] [ { -p | --pg } PG_CONFIG="PG_VALUE" [, ... ] ] [ { --apply | --replace } CONFIG_FILE ] [ --force ] |
These are my defaulted parameter settings: notice that both the Postgres runtime parameters, postgresql.conf, and the host-based authentication rules, pg_hba, are editable:
|
1 |
patronictl show-config |
As you can see, there’s not much here by way of configuration. Only max_connections has been set. Notice also that the host-based authentication, pg_hba.conf, can be updated too:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
loop_wait: 10 maximum_lag_on_failover: 1048576 postgresql: parameters: max_connections: 100 pg_hba: - local all all trust - host replication replicator all md5 - host all all all md5 use_pg_rewind: true retry_timeout: 10 ttl: 30 |

Changing a runtime variable not requiring a server restart, a SIGHUP, will be updated automatically across the cluster within 10 seconds, which is controlled by loop_wait. Recall the name of this Patroni cluster is demo:
|
1 2 |
# EXAMPLE: increase the work_mem patronictl edit-config demo --pg work_mem="10MB" --force |
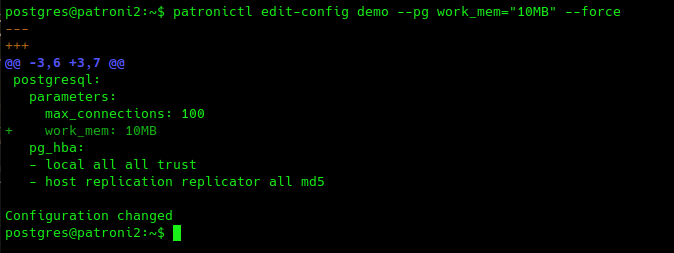
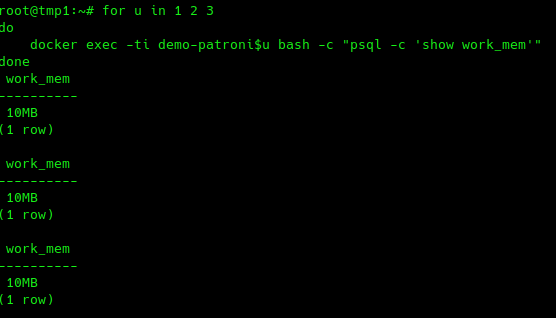
Polling all three nodes demonstrates the updates have taken place across the cluster:
|
1 2 3 4 |
for u in 1 2 3 do docker exec -ti demo-patroni$u bash -c "psql -c 'show work_mem'" done |
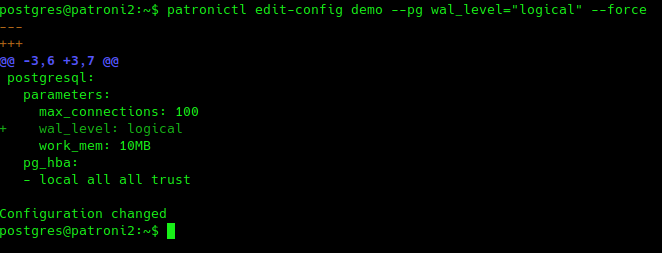
On the other hand, a runtime parameter requiring a restart needs administrative intervention:
|
1 2 |
# EXAMPLE: change the wal_level patronictl edit-config demo --pg wal_level="logical" --force |
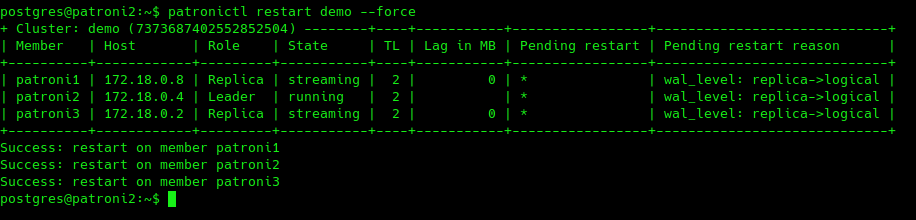
After waiting 10 seconds, one can see that the column Pending restart appears, thus indicating that a restart is required:
|
1 |
postgres@haproxy:~$ patronictl list |

|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
Usage: patronictl restart [OPTIONS] CLUSTER_NAME [MEMBER_NAMES]... Restart cluster member Options: --group INTEGER Citus group -r, --role [leader|primary|standby-leader|replica|standby|any|master] Restart only members with this role --any Restart a single member only --scheduled TEXT Timestamp of a scheduled restart in unambiguous format (e.g. ISO 8601) --pg-version TEXT Restart if the PostgreSQL version is less than provided (e.g. 9.5.2) --pending Restart if pending --timeout TEXT Return error and fail over if necessary when restarting takes longer than this. --force Do not ask for confirmation at any point --help Show this message and exit. |
The restart command can invoke a server restart across one or more nodes. The –force argument precludes the interactive question/answer mode:
|
1 |
patronictl restart demo --force |
As you can see, editing runtime parameters is trivial. The only caveat is to watch the indentation. Referring to the documentation, you’ll find there’s an entire gamut of options that can further configure the cluster’s overall behavior:
EXAMPLE: Change replication from async to synchronous replication.
STEP ONE: Query the PRIMARY
|
1 |
psql -c 'select usename, application_name, sync_state from pg_stat_replication' |

STEP TWO: Perform the update. Note the number count of sync’d nodes, parameter synchronous_node_count, is by default set at only 1:
|
1 2 3 4 |
patronictl edit-config demo --set synchronous_mode='true' --set synchronous_node_count=2 --pg synchronous_commit='true' --force |
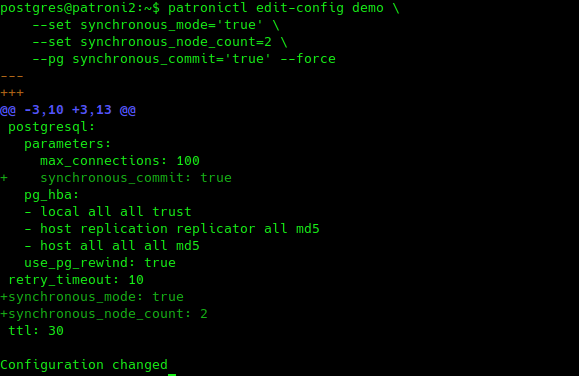
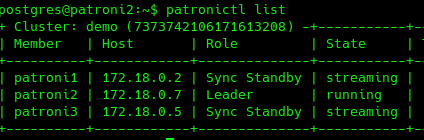
STEP 3: Confirm update has taken place, this does not require a restart.
|
1 |
patronictl list |
STEP 4: Query the PRIMARY; replication is now synchronous.
|
1 |
psql -c 'select usename, application_name, sync_state from pg_stat_replication' |

Multiple changes can also be made using your favorite editor, which in this case, defaults to vim:
|
1 |
patronictl edit-config |

Conclusion
Properly configured, the Patroni DCS manages not only the standard multi-node streaming replication cluster but also disaster recovery procedures and hybrid configurations that include logical nodes and citrus clusters and even administers and manages entire STANDBY data centers.
See why running open source PostgreSQL in-house demands more time, expertise, and resources than most teams expect — and what it means for IT and the business.
PostgreSQL in the Enterprise: The Real Cost of Going DIY
About the Author
 Robert Bernier
Robert BernierRobert's first working computer was the very user-friendly IBM 360 with an awesome 4MB RAM. After a round of much needed therapy overcoming the trauma of programming with punch cards he discovered the IBM-XT and the miracle of DOS 2.0. Years later, Robert became enamored with Linux and the opensource world and after meeting one of the members of CORE his primary focus had become all things PostgreSQL. Robert has since then worked in mom and pop companies, fortune 50 corporations and a number of very cool environments including the famed Los Alamos National Laboratory in New Mexico, birthplace of the atomic age. Although reluctant to leave the enjoyable experience of California's Silicon Valley commuter life, he returned to the Pacific Northwest and once again experienced real weather. These days, he serves as the PostgreSQL Consultant here at Percona.





Nice article, very well explained.