

This post was originally published in 2023, and we’ve updated it in 2025 for clarity and relevance, reflecting current practices while honoring its original perspective.
Running PostgreSQL on Kubernetes promises flexibility, but storage decisions can quickly make or break your deployment. From balancing cost with performance to ensuring high availability, every choice adds complexity. That’s why there are multiple storage strategies for PostgreSQL on Kubernetes in Percona Operator for PostgreSQL, giving you a path to configure for your unique needs without locking into rigid, proprietary solutions.
In this post, we’ll walk through different storage strategies, starting with the basics and moving into more advanced approaches, to help you build a setup that scales.
Basic storage strategies for PostgreSQL on Kubernetes
Setting StorageClass
StorageClass resource in Kubernetes allows users to set various parameters of the underlying storage. For example, you can choose the public cloud storage type – gp3, io2, etc, or set file system.
You can check existing storage classes by running the following command:
|
1 2 3 4 5 6 |
$ kubectl get sc NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE premium-rwo pd.csi.storage.gke.io Delete WaitForFirstConsumer true 54m regionalpd-storageclass pd.csi.storage.gke.io Delete WaitForFirstConsumer false 51m standard kubernetes.io/gce-pd Delete Immediate true 54m standard-rwo (default) pd.csi.storage.gke.io Delete WaitForFirstConsumer true 54m |
As you see standard-rwo is a default StorageClass, meaning that if you don’t specify anything, the Operator will use it.
To instruct Percona Operator for PostgreSQL which storage class to use, set it the spec.instances.[].dataVolumeClaimSpec section:
|
1 2 3 4 5 6 7 |
dataVolumeClaimSpec: accessModes: - ReadWriteOnce storageClassName: STORAGE_CLASS_NAME resources: requests: storage: 1Gi |
Storage strategy: using a dedicated volume for PostgreSQL WALs on Kubernetes
Write-Ahead Logs (WALs) keep the recording of every transaction in your PostgreSQL deployment. They are useful for point-in-time recovery and minimizing your Recovery Point Objective (RPO). In Percona Operator, it is possible to have a separate volume for WALs to minimize the impact on performance and storage capacity. To set it, use spec.instances.[].walVolumeClaimSpec section:
|
1 2 3 4 5 6 7 |
walVolumeClaimSpec: accessModes: - ReadWriteOnce storageClassName: STORAGE_CLASS_NAME resources: requests: storage: 1Gi |
If you enable walVolumeClaimSpec, the Operator will create two volumes per replica Pod – one for data and one for WAL:
|
1 2 3 4 5 6 |
cluster1-instance1-8b2m-pgdata Bound pvc-2f919a49-d672-49cb-89bd-f86469241381 1Gi RWO standard-rwo 36s cluster1-instance1-8b2m-pgwal Bound pvc-bf2c26d8-cf42-44cd-a053-ccb6abadd096 1Gi RWO standard-rwo 36s cluster1-instance1-ncfq-pgdata Bound pvc-7ab7e59f-017a-4655-b617-ff17907ace3f 1Gi RWO standard-rwo 36s cluster1-instance1-ncfq-pgwal Bound pvc-51baffcf-0edc-472f-9c95-7a0cea3e6507 1Gi RWO standard-rwo 36s cluster1-instance1-w4d8-pgdata Bound pvc-c60282ed-3599-4033-afc7-e967871efa1b 1Gi RWO standard-rwo 36s cluster1-instance1-w4d8-pgwal Bound pvc-ef530cb4-82fb-4661-ac76-ee7fda1f89ce 1Gi RWO standard-rwo 36s |
Expanding storage for PostgreSQL on Kubernetes clusters
If your StorageClass and storage interface (CSI) supports VolumeExpansion, you can just change the storage size in the Custom Resource manifest. The operator will do the rest and expand the storage automatically. This is a zero-downtime operation and is limited by underlying storage capabilities only.
Adjusting storage classes for PostgreSQL on Kubernetes
It is also possible to change the storage capabilities, such as filesystem, IOPs, and type. Right now, it is possible through creating a new storage class and applying it to the new instance group.
|
1 2 3 4 5 6 7 8 9 10 |
spec: instances: - name: newGroup dataVolumeClaimSpec: accessModes: - ReadWriteOnce storageClassName: NEW_STORAGE_CLASS resources: requests: storage: 2Gi |
Creating a new instance group replicates the data to new replica nodes. This is done without downtime, but replication might introduce additional load on the primary node and the network.
There is work in progress under Kubernetes Enhancement Proposal (KEP) #3780. It will allow users to change various volume attributes on the fly vs through the storage class.
Ensuring data persistence in PostgreSQL on Kubernetes
Finalizers
By default, the Operator keeps the storage and secret resources if the cluster is deleted. We do it to protect the users from human errors and other situations. This way, the user can quickly start the cluster, reusing the existing storage and secrets.
This default behavior can be changed by enabling a finalizer in the Custom Resource:
|
1 2 3 4 5 6 7 |
apiVersion: pgv2.percona.com/v2 kind: PerconaPGCluster metadata: name: cluster1 finalizers: - percona.com/delete-pvc - percona.com/delete-ssl |
This is useful for non-production clusters where you don’t need to keep the data.
Protecting PostgreSQL data with Kubernetes StorageClass policies
There are extreme cases where human error is inevitable. For example, someone can delete the whole Kubernetes cluster or a namespace. Good thing that StorageClass resource comes with reclaimPolicy option, which can instruct Container Storage Interface to keep the underlying volumes. This option is not controlled by the operator, and you should set it for the StorageClass separately.
|
1 2 3 4 5 6 |
> apiVersion: storage.k8s.io/v1 > kind: StorageClass > ... > provisioner: pd.csi.storage.gke.io - reclaimPolicy: Delete + reclaimPolicy: Retain |
In this case, even if Kubernetes resources are deleted, the physical storage is still there.
Using regional disks for PostgreSQL on Kubernetes
Regional disks are available at Azure and Google Cloud but not yet at AWS. In a nutshell, it is a disk that is replicated across two availability zones (AZ).

To use regional disks, you need a storage class that specifies in which AZs will it be available and replicated to:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
kind: StorageClass apiVersion: storage.k8s.io/v1 metadata: name: regionalpd-storageclass provisioner: pd.csi.storage.gke.io parameters: type: pd-balanced replication-type: regional-pd volumeBindingMode: WaitForFirstConsumer allowedTopologies: - matchLabelExpressions: - key: topology.gke.io/zone values: - us-central1-a - us-central1-b |
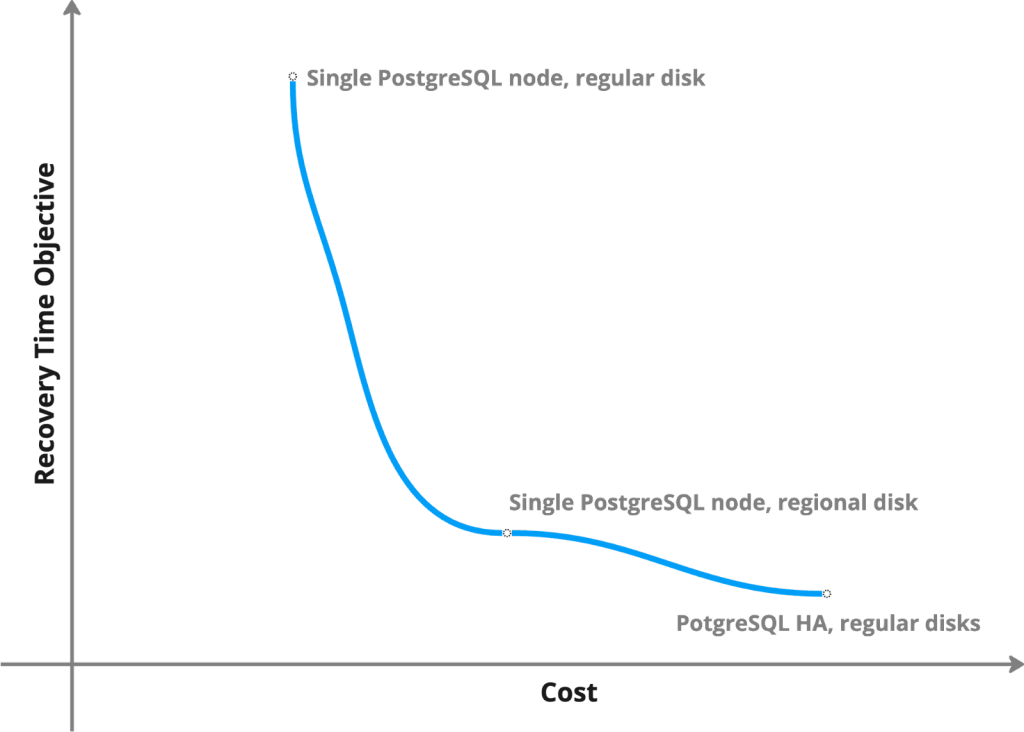
There are some scenarios where regional disks can help with cost reduction. Let’s review three PostgreSQL topologies:
- Single node with regular disks
- Single node with regional disks
- PostgreSQL Highly Available cluster with regular disks

If we apply availability zone failure to these topologies, we will get the following:
- Single node with regular disks is the cheapest one, but in case of AZ failure, recovery might take hours or even days – depending on the data.
- With single node and regional disks, you will not be spending a dime on compute for replicas, but at the same time, you will recover within minutes.
- PostgreSQL cluster provides the best availability, but also comes with high compute costs.
| Single PostgreSQL node, regular disk | Single PostgreSQL node, regional disks | PostgreSQL HA, regular disks | |
| Compute costs | $ | $ | $$ |
| Storage costs | $ | $$ | $$ |
| Network costs | $0 | $0 | $ |
| Recovery Time Objective | Hours | Minutes | Seconds |
Leveraging local storage for PostgreSQL on Kubernetes
One of the ways to reduce your total cost of ownership (TCO) for stateful workloads on Kubernetes and boost your performance is to use local storage as opposed to network disks. Public clouds provide instances with NVMe SSDs that can be utilized in k8s with tools like OpenEBS, Portworx, and more. The way it is consumed is through regular storage classes and deserves a separate blog post.

Bringing your PostgreSQL storage strategy together
Choosing the right storage strategy is a big step toward running PostgreSQL effectively on Kubernetes, but it’s only part of the challenge. Scaling deployments, automating operations, and keeping costs predictable all add to the daily pressure on your team. That’s where Percona can help.
We’ve put together a guide that shows how to take the complexity out of PostgreSQL in the cloud with automation, scalability, and zero lock-in. Explore it here:

About the Author
 Sergey Pronin
Sergey ProninSergey is a product leader at Percona focusing on delivering robust open-source database and cloud-native solutions. Prior to Percona Sergey led product management and engineering teams in other organizations with a primary focus on products in infrastructure and platforms space.






Good ?