
In this blog post, we will discuss the best practices on the MongoDB ecosystem applied at the Operating System (OS) and MongoDB levels. We’ll also go over some best practices for MongoDB security as well as MongoDB data modeling. The main objective of this post is to share my experience over the past years tuning MongoDB and centralize the diverse sources that I crossed in this journey in a unique place.
Spoiler alert: This post focuses on MongoDB 3.6.X series and higher since previous versions have reached End-of-Life (EOL).
Note that the intent of tuning the settings is not exclusively about improving performance but also enhancing the high availability and resilience of the MongoDB database.
Without further ado, let’s start with the OS settings.
Swappiness is a Linux kernel setting that influences the behavior of the Virtual Memory manager when it needs to allocate a swap, ranging from 0-100. A setting of “0” tells the kernel to swap only to avoid out-of-memory problems. A setting of 100 determines it to swap aggressively to disk. The Linux default is usually 60, which is not ideal for database usage.
It is common to see a value of “0″ (or sometimes “10”) on database servers, telling the kernel to prefer to swap to memory for better response times. However, Ovais Tariq details a known bug (or feature) when using a setting of “0”.
|
1 2 |
# Non persistent - the value will change to the previous value if you reboot the OS echo 1 > /proc/sys/vm/swappiness |
|
1 2 |
# Change in sysctl.conf will make the change persistent across reboots sudo sysctl -w vm.swappiness=1 |
Non-uniform memory access (NUMA) is a memory design where a symmetric multiprocessing system processor(SMP) can access its local memory faster than non-local memory (the one assigned locally to other CPUs). Here is an example of a system that has NUMA enabled:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# NUMA system $ numactl --hardware available: 2 nodes (0-1) node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 24 25 26 27 28 29 30 31 32 33 34 35 node 0 size: 130669 MB node 0 free: 828 MB node 1 cpus: 12 13 14 15 16 17 18 19 20 21 22 23 36 37 38 39 40 41 42 43 44 45 46 47 node 1 size: 131072 MB node 1 free: 60 MB node distances: node 0 1 0: 10 21 1: 21 10 |
Unfortunately, MongoDB is not NUMA-aware, and because of this, MongoDB can allocate memory unevenly, leading to the swap issue even with memory available. To solve this issue the mongod process can use the interleaved mode (fair memory allocation on all the nodes) in two ways:
Start the mongod process with numactl --interleave=all :
|
1 |
numactl --interleave=all /usr/bin/mongod -f /etc/mongod.conf |
Or if systemd is in use:
|
1 2 |
# Edit the file /etc/systemd/system/multi-user.target.wants/mongod.service |
If the existing ExecStart statement reads:
Restart any running mongod instances:
And to validate the memory usage:
|
1 2 3 4 5 6 7 8 9 10 11 |
$ sudo numastat -p $(pidof mongod) Per-node process memory usage (in MBs) for PID 35172 (mongod) Node 0 Node 1 Total --------------- --------------- --------------- Huge 0.00 0.00 0.00 Heap 19.40 27.36 46.77 Stack 0.03 0.03 0.05 Private 1.61 24.23 25.84 ---------------- --------------- --------------- --------------- Total 21.04 51.62 72.66 |
In some OS versions, the vm.zone_reclaim_mode is enabled. The zone_reclaim_mode parameter allows someone to set more or less aggressive approaches to reclaim memory when a zone runs out of memory. If it is set to zero, then no zone reclaim occurs.
It is necessary to disable vm.zone_reclaim_mode when NUMA is enabled. To disable it, you can execute the following command:
|
1 |
sudo sysctl -w vm.zone_reclaim_mode=0 |
The IO scheduler is an algorithm the kernel will use to commit reads and writes to disk. By default, most Linux installs use the CFQ (Completely-Fair Queue) scheduler. The CFQ works well for many general use cases but lacks latency guarantees. Two other schedulers are deadline and noop. The deadline excels at latency-sensitive use cases (like databases), and noop is closer to no schedule at all. For bare metals, any algorithm among deadline or noop (the performance difference between them is imperceptible) will be better than CFQ.
Get database support for MongoDB
If you are running MongoDB inside a VM (which has its own IO scheduler beneath it), it is best to use “noop” and let the virtualization layer take care of the IO scheduling itself.
To change it, run these as root (accordingly to the disk):
|
1 2 3 4 5 6 |
# Verifying $ cat /sys/block/xvda/queue/scheduler noop [deadline] cfq # Adjusting the value dynamically $ echo "noop" > /sys/block/xvda/queue/scheduler |
To make this change persistent, you must edit the GRUB configuration file (usually /etc/sysconfig/grub ) and add an elevator option to GRUB_CMDLINE_LINUX_DEFAULT . For example, you would change this line:
|
1 |
GRUB_CMDLINE_LINUX="console=tty0 crashkernel=auto console=ttyS0,115200 |
With this line:
|
1 |
GRUB_CMDLINE_LINUX="console=tty0 crashkernel=auto console=ttyS0,115200 elevator=noop" |
Note for AWS setups: There are cases where the I/O scheduler has a value of none, most notably in AWS VM instance types where EBS volumes are exposed as NVMe block devices. This is because the setting has no use in modern PCIe/NVMe devices. The reason is that they have a substantial internal queue, and they bypass the IO scheduler altogether. The setting, in this case, is none, and it is optimal in such disks.
Databases use small memory pages, and the Transparent Huge Pages tend to become fragmented and impact performance:
To disable it on the runtime for RHEL/CentOS 6 and 7:
|
1 2 |
$ echo "never" > /sys/kernel/mm/transparent_hugepage/enabled $ echo "never" > /sys/kernel/mm/transparent_hugepage/defrag |
To make this change survive a server restart, you’ll have to add the flag transparent_hugepage=never to your kernel options (/etc/sysconfig/grub):
|
1 |
GRUB_CMDLINE_LINUX="console=tty0 crashkernel=auto console=ttyS0,115200 elevator=noop transparent_hugepage=never" |
Rebuild the /boot/grub2/grub.cfg file by running the grub2-mkconfig -o command. Before rebuilding the GRUB2 configuration file, ensure to take a backup of the existing /boot/grub2/grub.cfg.
On BIOS-based machines
|
1 |
$ grub2-mkconfig -o /boot/grub2/grub.cfg |
Troubleshooting
If Transparent Huge Pages (THP) is still not disabled, continue and use the option below:
Disable tuned services
Disable the tuned services if it is re-enabling the THP using the below commands.
|
1 2 |
$ systemctl stop tuned $ systemctl disable tuned |
The dirty_ratio is the percentage of total system memory that can hold dirty pages. The default on most Linux hosts is between 20-30%. When you exceed the limit, the dirty pages are committed to the disk, creating a small pause. To avoid the hard pause, there is a second ratio: dirty_background_ratio (default 10-15%) which tells the kernel to start flushing dirty pages to disk in the background without any pause.
20-30% is a good general default for “dirty_ratio,” but on large-memory database servers, this can be a lot of memory. For example, on a 128GB memory host, this can allow up to 38.4GB of dirty pages. The background ratio won’t kick in until 12.8GB. It is recommended to lower this setting and monitor the impact on query performance and disk IO. The goal is to reduce memory usage without impacting query performance negatively.
A recommended setting for dirty ratios on large-memory (64GB+) database servers is: vm.dirty_ratio = 15 and vm.dirty_background_ratio = 5, or possibly less. (Red Hat recommends lower ratios of 10 and 3 for high-performance/large-memory servers.)
You can set this by adding the following lines to the /etc/sysctl.conf:
|
1 2 |
vm.dirty_ratio = 15 vm.dirty_background_ratio = 5 |
MongoDB recommends the XFS filesystem for on-disk database data. Furthermore, proper mount options can improve performance noticeably. Make sure the drives are mounted with noatime and also if the drives are behind a RAID controller with appropriate battery-backed cache. It is possible to remount on the fly; For example, in order to remount /mnt/db/ with these options:
|
1 |
mount -oremount,rw,noatime/mnt/db |
It is necessary to add/edit the corresponding line in /etc/fstab for the option to persist on reboots. For example:
|
1 |
UUID=f41e390f-835b-4223-a9bb-9b45984ddf8d / xfs rw,noatime,attr2,inode64,noquota 0 0 |
Most UNIX-like operating systems, including Linux and macOS, provide ways to limit and control the usage of system resources such as threads, files, and network connections on a per-process and per-user basis. These “ulimits” prevent single users from using too many system resources. Sometimes, these limits have low default values that can cause several issues during regular MongoDB operations. For Linux distributions that use systemd, you can specify limits within the [Service] :
First, open the file for editing:
|
1 |
vi /etc/systemd/system/multi-user.target.wants/mongod.service |
And under [Service] add the following:
All of these deeper tunings make it easy to forget about something as simple as your clock source. As MongoDB is a cluster, it relies on a consistent time across nodes. Thus the NTP Daemon should run permanently on all MongoDB hosts, mongos and arbiters included.
This is installed on RedHat/CentOS with the following:
|
1 |
sudo yum install ntp |
Values can range from 1 to 500 milliseconds (default is 200 ms). Lower values increase the durability of the journal at the expense of disk performance. Since MongoDB usually works with a replica set, it is possible to increase this parameter to get better performance:
|
1 2 3 4 5 |
# edit /etc/mongod.conf storage: journal: enabled: true commitIntervalMs: 300 |
For dedicated servers, it is possible to increase the WiredTiger(WT) cache. By default, it uses 50% of the memory + 1 GB. Set the value to 60-70% and monitor the memory usage. For example, to set the WT cache to 50Gb:
|
1 2 3 4 |
# edit /etc/mongod.conf wiredTiger: engineConfig: cacheSizeGB: 50 |
If there’s a monitoring tool in place, such as Percona Monitoring and Management (Get Percona Monitoring and Management for MongoDB), it is possible to monitor memory usage. For example:
WiredTiger uses tickets to control the number of read/write operations simultaneously processed by the storage engine. The default value is 128 and works well for most cases, but in some cases case, the number of tickets is not enough. To adjust:
|
1 2 3 |
use admin db.adminCommand( { setParameter: 1, wiredTigerConcurrentReadTransactions: 256 } ) db.adminCommand( { setParameter: 1, wiredTigerConcurrentWriteTransactions: 256 } ) |
https://docs.mongodb.com/manual/reference/parameters/#wiredtiger-parameters
To make persistent add to the Mongo configuration file:
|
1 2 3 4 |
# Two options below can be used for wiredTiger and inMemory storage engines setParameter: wiredTigerConcurrentReadTransactions: 256 wiredTigerConcurrentWriteTransactions: 256 |
And to estimate is necessary to observe the workload behavior. Again, PMM is suitable for this situation:
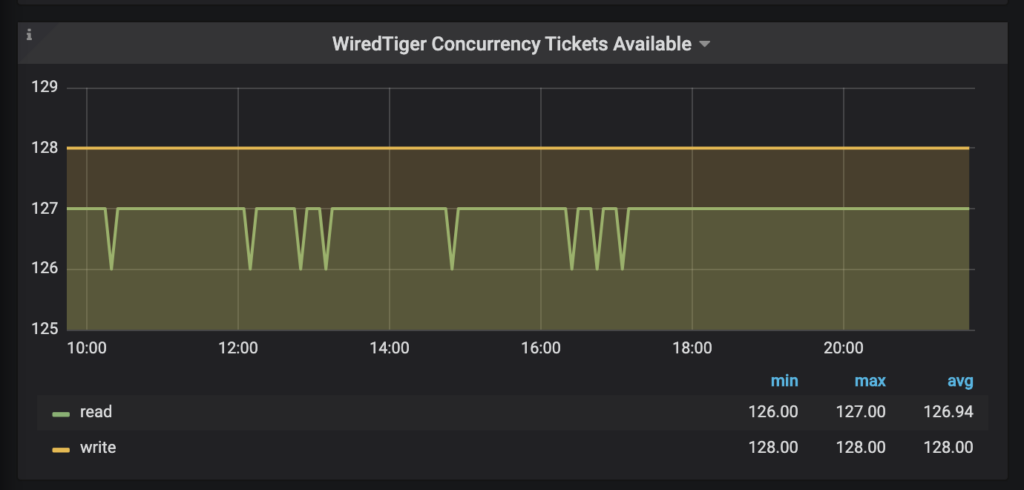
Note that sometimes increasing the level of parallelism might lead to an opposite effect than desired in an already loaded server. At this point, it might be necessary to reduce the number of tickets to the current number of CPUs/vCPUs available (if the server has 16 cores, set the read/write tickets for 16 each). This parameter needs to be extensively tested!
mongos in containersThe mongos process is not cgroups aware, which means it can blow up the CPU usage creating tons of TaskExecutor threads. Secondly, grouping containers in Kubernetes Pods creates tons of mongos processes, resulting in additional overhead. We can also extend this for automation(using Ansible, for example), which in general, DevOps engineers tend to create a pool of mongos.
To avoid pool explosion, set the parameter taskExecutorPoolSize in the containerized mongos by running it with the following argument or setting this parameter in a configuration file: --setParameter taskExecutorPoolSize=X, where X is the number of CPU cores you assign to the container (for example, ‘CPU limits’ in Kubernetes or ‘cpuset/cpus’ in Docker). For example:
|
1 |
$ /opt/mongodb/4.0.6/bin/mongos --logpath /home/vinicius.grippa/data/data/mongos.log --port 37017 --configdb configRepl/localhost:37027,localhost:37028,localhost:37029 --keyFile /home/vinicius.grippa/data/data/keyfile --fork --setParameter taskExecutorPoolSize=1 |
Or using the configuration file:
|
1 2 |
setParameter: taskExecutorPoolSize: 1 |
When MongoDB is initially deployed, it does not enable authentication or authorization by default, making data susceptible to unauthorized access and potential data leaks. However, by activating these security features, users must authenticate themselves before accessing the database, thus reducing the likelihood of unauthorized access and data breaches. Enabling authentication and authorization from the outset is crucial to safeguarding data and can help prevent security vulnerabilities from being exploited.
Regular backups are essential for MongoDB, as they serve as a safeguard against potential data loss caused by various factors, such as system failures, human errors, or malicious attacks. MongoDB backup methods include full, incremental, and continuous backups. Percona Backup for MongoDB is a custom-built backup utility designed to cater to the needs of users who don’t want to pay for proprietary software but require a fully supported community backup tool capable of performing cluster-wide consistent backups in MongoDB.
Regular backups can significantly reduce the potential downtime and losses resulting from data loss, enabling organizations to restore their data promptly after a failure. Moreover, backups play a crucial role in data security by mitigating the risks of data breaches and other vulnerabilities. By restoring the database to its previous state using backups, organizations can minimize the impact of an attack and quickly resume their operations.
As with any database, it’s essential to monitor MongoDB performance to ensure it’s running with optimal efficiency and effectiveness. By monitoring MongoDB, database administrators can get insights into potential bottlenecks, pinpoint sluggish queries, and improve application performance, as well as proactively address issues before they become critical, reducing downtime and ensuring a better user experience.
MongoDB databases that are left unmonitored are susceptible to various security threats, including, but not limited to, unauthorized access, data breaches, and data loss. If, for instance, an unsecured MongoDB instance is infiltrated by a malicious attacker, they may be able to steal sensitive information or even completely delete the data. Additionally, unmonitored databases can lead to security vulnerabilities that may be exploited.
In addition, unmonitored databases can also result in non-compliance with regulatory standards such as the General Data Protection Regulation (GDPR) or the California Consumer Privacy Act (CCPA). These regulations require organizations to protect user data and take measures to ensure data privacy.
Percona Monitoring and Management (PMM) is an open source database observability, monitoring, and management tool that provides actionable performance data for MongoDB variants, including Percona Server for MongoDB, MongoDB Community, and MongoDB Enterprise. Learn how you can Improve MongoDB Performance with Percona Monitoring and Management.
The traditional approach in designing a database schema in relational databases involves creating tables that store data in a tabular format. In this approach, each table represents an entity, and the relationships between the entities are defined through foreign key constraints. This schema design approach ensures data consistency and enables complex queries involving multiple tables, but it can be rigid and may pose scaling challenges as data volume increases.
On the other hand, MongoDB schema design takes a document-oriented approach. Instead of storing data in tables, data is stored in documents that can be nested to represent complex relationships, providing more flexibility in data modeling. This approach enables faster queries, as related data can be retrieved with a single query. However, it can lead to the storage of redundant data and make it more difficult to maintain data consistency.
Deciding between these two schema design approaches depends on the specific requirements of the application. For applications with complex relationships between entities, a relational database may be more suitable. However, for applications that require more flexibility in data modeling and faster query performance, MongoDB’s document-oriented approach may be the better option.
MongoDB offers two strategies for storing related data: embedding and referencing. Embedding involves storing associated data within a single document while referencing involves storing related data in separate documents and using a unique identifier to link them.
The key advantage of utilizing embedding is that it minimizes the necessity for multiple queries to retrieve associated data. Since all of the related data is stored in one document, a query for that particular document will enable the retrieval of all associated data simultaneously.
Embedding further simplifies database operations, reduces network overhead, and boosts read and query performance. However, it is worth noting that embedding may lead to the creation of large documents, which can negatively impact write performance and consume more memory.
Alternatively, referencing provides greater flexibility in querying and updating related data. It results in the creation of smaller documents, which can benefit write performance and memory usage. Still, it does require multiple queries to retrieve related data, which can affect read performance.
Replication and sharding are techniques used to enhance performance and ensure the high availability of MongoDB databases.
Replication in MongoDB involves the utilization of replica sets, with one functioning as the primary and the others as secondary. The primary instance receives write operations, while the secondary instances replicate the data from the primary and can also be used for read operations. In case the primary instance fails, one of the secondary instances becomes the primary instance, providing redundancy and guaranteeing database high availability.
Sharding is the process of partitioning data across multiple servers in a cluster. In MongoDB, sharding is achieved by creating shards, each of which contains a subset of the data, which are then distributed across multiple machines in a cluster, with each machine hosting one or more shards. This allows MongoDB to scale horizontally, handling large datasets and high traffic loads.
Replication and sharding are good options to consider when your MongoDB database becomes slow. Replication is particularly useful for read-heavy workloads, while sharding is more suited to write-heavy workloads. When dealing with both read and write-heavy workloads, a combination of the two may be the best option, depending on the specific needs and demands of your application(s).
Ensure data availability for your applications with Percona Distribution for MongoDB
I tried to cover and summarize the most common questions and incorrect settings that I see in daily activities. Using recommended settings is not a silver bullet, but it will cover the majority of the cases and will help have a better user experience for those who use MongoDB. Finally, having a proper monitoring system in place must be a priority to adjust its settings according to the application workload.
Percona’s open source database monitoring tool monitors the health of your database infrastructure and helps you improve MongoDB performance. Download today.
Download Percona Monitoring and Management
Finally, you can reach us through social networks, our forum, or access our material using the links presented below:
Resources
RELATED POSTS




