
 This is a three-part blog series that focuses on dealing with an unexpected high traffic event as it is happening. Part one can be found here and part three can be found here.
This is a three-part blog series that focuses on dealing with an unexpected high traffic event as it is happening. Part one can be found here and part three can be found here.Complexity: Low
Potential Impact: High
If your data does not fit into memory well, your MySQL performance is likely to be severely limited. If your data already fits in well, adding even more memory will not provide any performance improvements.
Even when you’re running on very fast storage, such as Intel Optane or directly Attached NVMe Storage, accessing data in memory is still more than an order of magnitude faster.
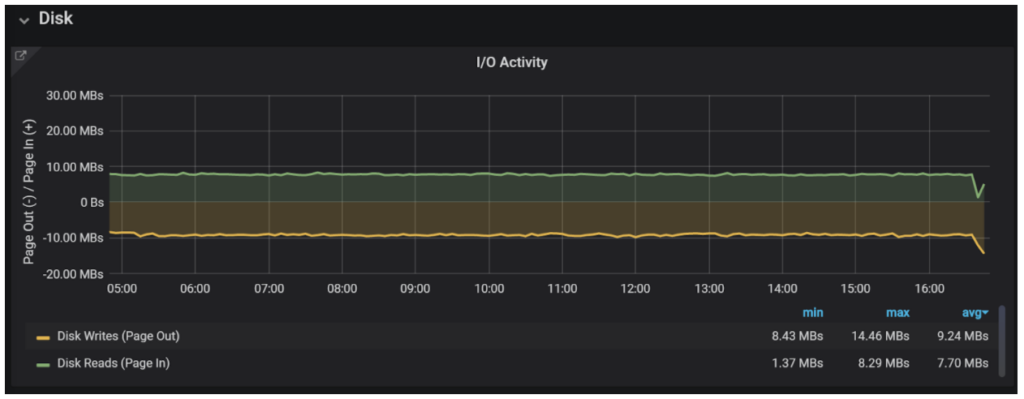
How do you know if you have enough memory? Look at Memory Utilization and I/O Activity.
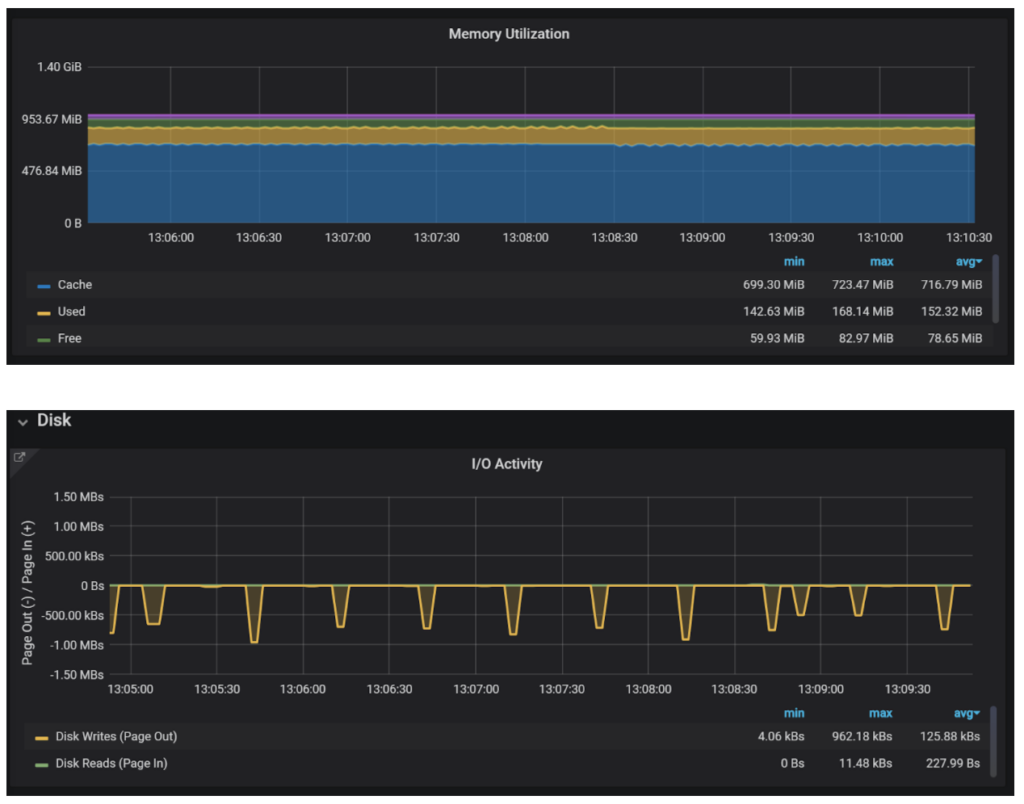
I/O Activity is actually the first item I would look at. If, as in this case, you have no read IO to speak about, all your data is in the cache — either MySQL’s data caches or Operating System file cache. Write activity, however, will not be eliminated completely even if all data fits in the cache as database modifications need to be recorded on the disk.
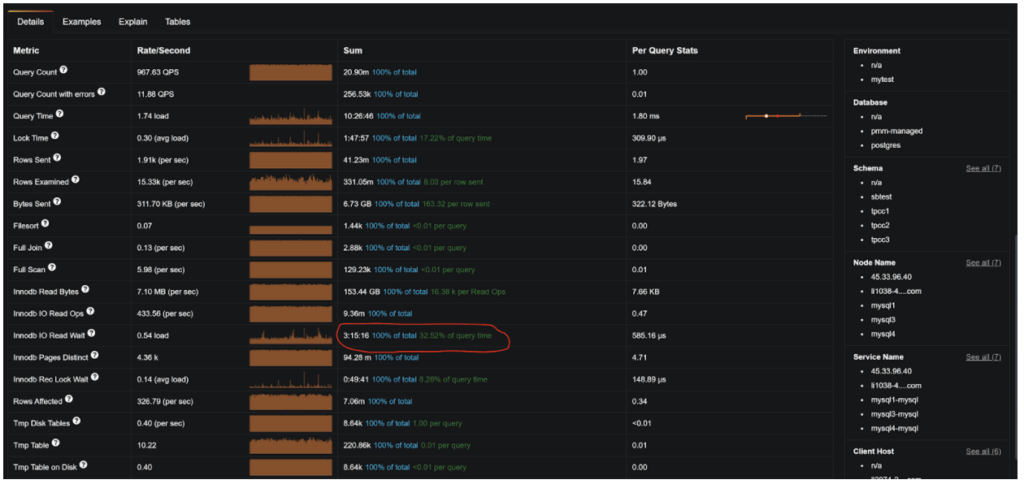
Typically you will not look to eliminate Read IO Completely — it will just require too much memory in most cases, and not needed. However, you want to make sure Read IO does not impact your performance substantially. You can do this by ensuring your disk load is manageable or, if you have Percona Monitoring and Management (PMM) installed, you can check how much disk reads impact your specific queries performance in Query Analytics.
Note: While you will get some value from simply adding more memory because it will be used by Operating System as a cache, to get most of the newly available memory, you should configure MySQL to use it. Innodb_buffer_pool_size is the most important variable to consider. 80% of memory is often used as a rule of thumb but there is more to that.
One thing you should be mindful of, as you configure MySQL to take advantage of all your memory, is to ensure you do not overcommit memory and MySQL does not run out of virtual memory (as it may crash or be killed by Out of Memory (OOM) Killer).
You also want to make sure there is no significant swapping activity (1MB/sec or more) but some swap space use is OK. Check out “In defense of swap: common misconceptions” for more details.
Complexity: Medium
Potential Impact: High
When your data size is small, fitting it into memory is the best way to scale reads. If your database is large, it can become impractical and a faster disk may be a better choice. Additionally, you get Writes which need to be handled even if you have a lot of memory. This old but still valid article goes into detail on this topic.
With CPUs, you need to know whenever you need more or faster cores, the situation with storage is even more complicated. You need to understand the difference between throughput (IOPS) and latency (check out this fantastic article on the topic) as well as the difference between read and write performance.
One way to look at IO performance is by looking at the Number of IOPS storage being served or the Bandwidth of IO activity.
It is helpful if you know what the limits of your storage are and if you’re close to or running into them. You may not know the exact performance storage can provide. In this case, it is helpful to take a look at Disk IO Load which roughly shows you how many IO operations are in flight at the time.
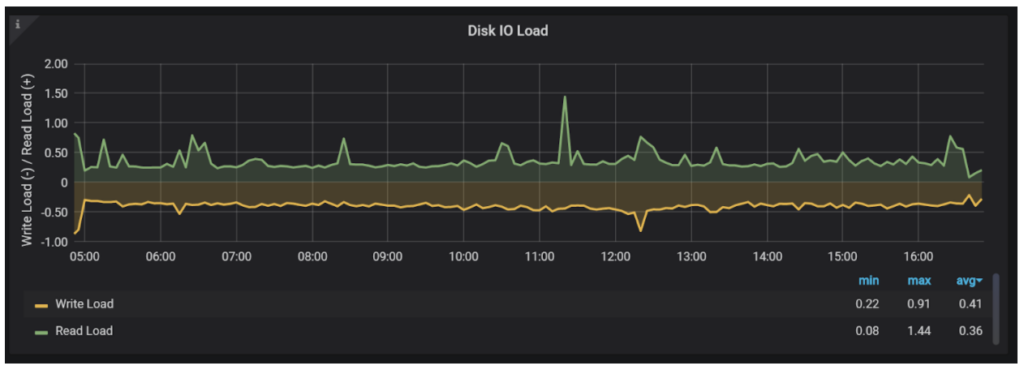
If you see this number in tens or hundreds, chances are your disk is overloaded. The problem with storage, unlike CPU, is that we have no way to know what is the “natural level of concurrency,” when requests can proceed in parallel, or when queueing needs to happen.
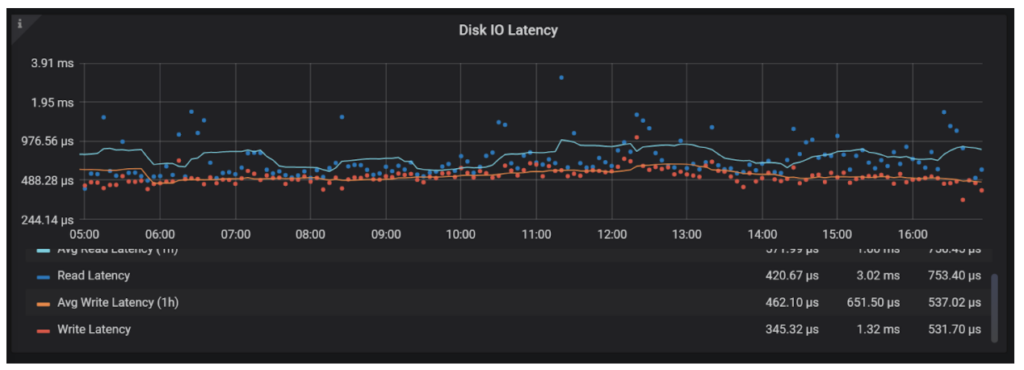
Take a look at request latency for reads and writes and see if they are any different from the time before traffic spike. Also, read and write latencies can be independently impacted and should be looked at separately.
How much can a faster disk impact your queries’ performance? From the reads standpoint, you can check PMM Query Analytics as I explained in the 7. Get More Memory section, but for writes, it is more complicated.
Write to InnoDB Redo Log, or more specifically, persisting it on disk through fsync() is a very common bottleneck. You will see if this happens in your system by looking at the number of pending fsyncs (MySQL Innodb Details dashboard, Innodb Disk IO Section).
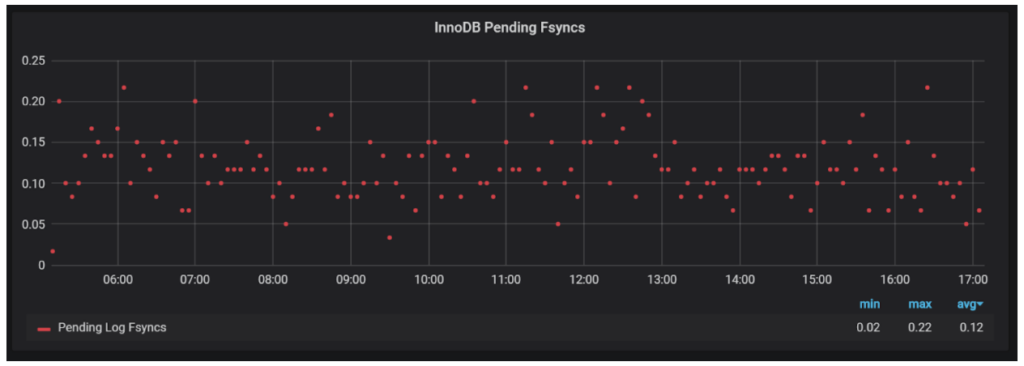
If it is close to 1 all the time, you likely have a bottleneck with disk flushing. To improve the situation you will need storage with better write (fsync()) latency. You can adjust your MySQL configuration to reduce durability guarantee or adjust your workload to group queries in smaller numbers of transactions.
What faster storage options are available? Intel Optane SSD or NVMe storage tends to offer the best performance and fastest and most predictable latency. However, if you use those solutions, especially in the cloud, make sure you use some form of replication for data redundancy.
If you need to use network storage, look for throughput optimized options such as AWS EBS io1 volume type. Traditional “general purpose” gp2 volumes can be a lot more cost-effective, but they have a lower peak performance.
Complexity: Low
Potential Impact: High
When checking if a network is a bottleneck in your traffic spike event, you need to be looking at Bandwidth, Latency, and Errors.
Networks tend to be more complicated than other resources because all these have to be measured for different clients separately. For example, clients running on “localhost” tend not to have a problem, however, clients running in other parts of the world communicating with your database will have issues.
Network bandwidth, at least when it comes to the local node, is rarely the problem.
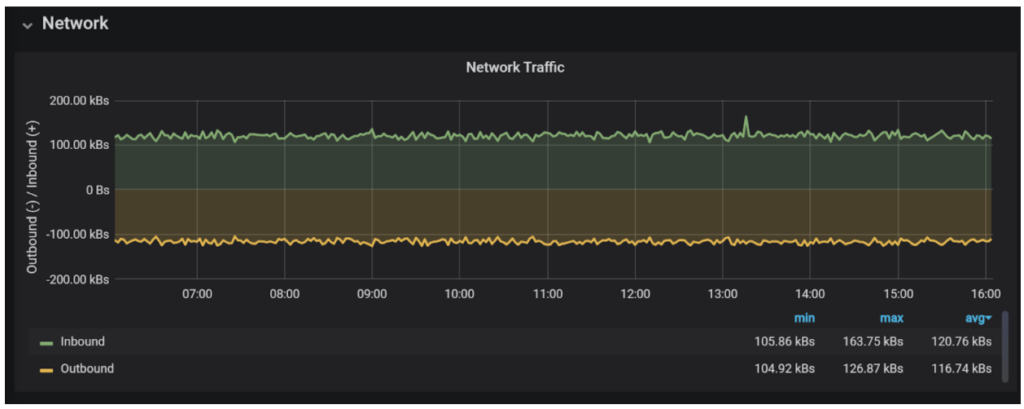
Rarely, applications retrieve large result sets and saturate the network. Network backups and other large data transfers can saturate the network causing the slowness of other user transactions.
The latency between your client and database server can be roughly measured by the “ping” or “mtr” tool. If you have a 10Gb network you may expect 0.2ms in the same data center. It is generally slightly higher in the cloud providers within the same availability zone. Different high availability zones come with higher latency and latency between distant regions can be 100ms and can have significantly higher variance than the local network.

In this case, we see the path between client and server passes through only one router (and perhaps a few switches) with an average latency of 1.5ms and no packet lost.
You should keep your application server and your database as close as possible — in the same availability zone if possible, but surely in the same region for latency-sensitive applications.
When it comes to errors, TCP retransmission is your worst enemy as it can add very significant latency.
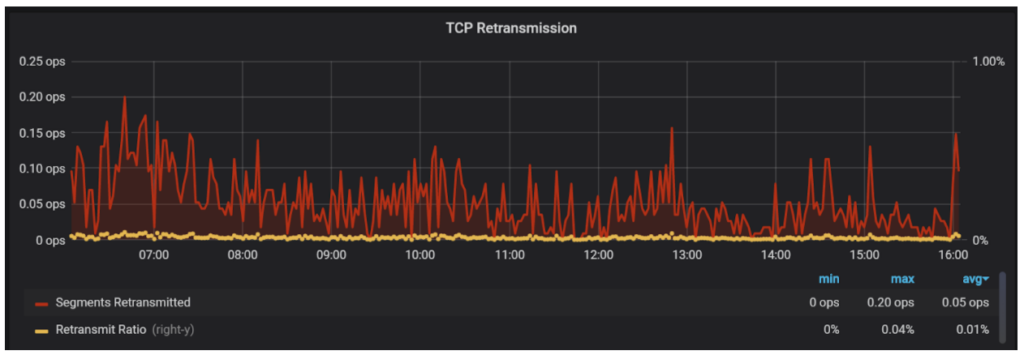
If you’re seeing increased retransmission rates during your traffic spike event, chances are there are problems on the network level which need to be addressed.
Complexity: Medium
Potential Impact: High
Locating and optimizing bad queries is one of the highest value activities you can do as it provides long-term benefits. Unlike beefing up your hardware, it does not require additional investment (other than time).
If you’re running Percona Monitoring and Management you should take a look at the Query Analytics tool, which by default sorts queries by the load they generate.
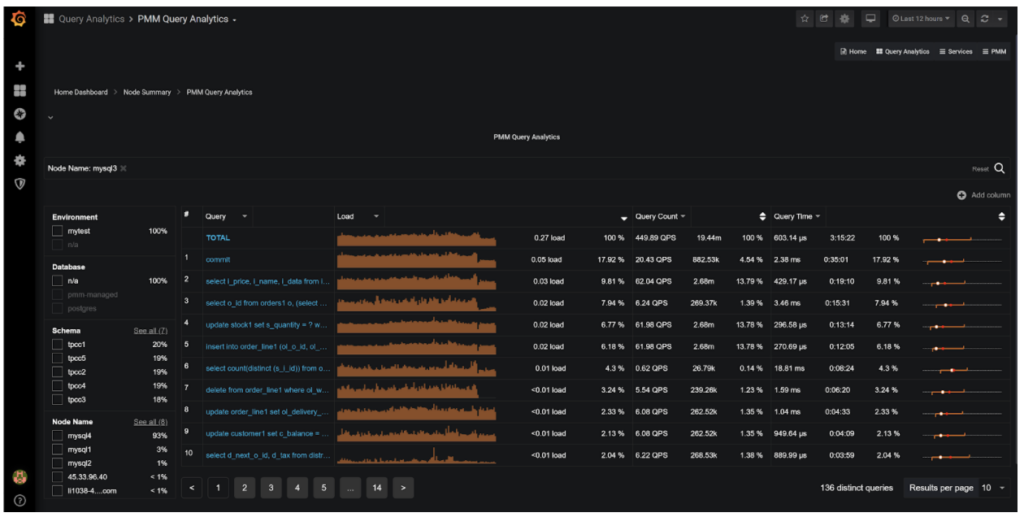
Examining and optimizing queries in this order is a fantastic way to make your system run faster. In some cases, like commit query, you can’t really optimize the query itself, but you can speed it up through hardware changes or MySQL configuration.
Check out query execution details:
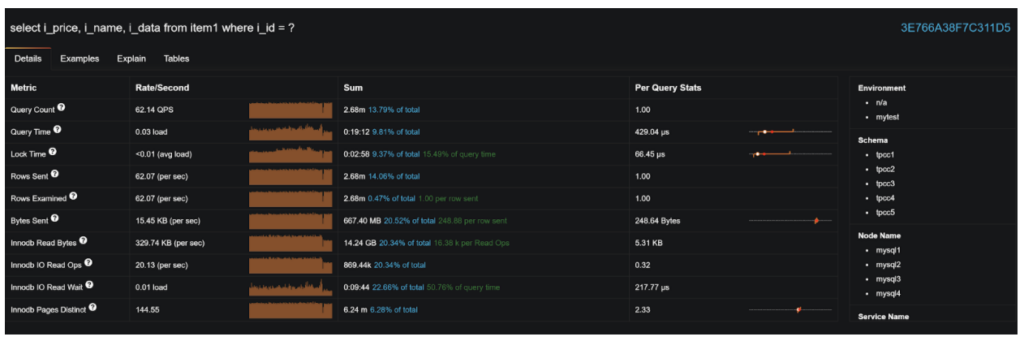
And Explain Plan to see if and how this query can be optimized:

MySQL Query Optimization is too complex a topic to cover in one blog post. I would consider learning to read EXPLAIN and attending a Webinar.
Complexity: Low
Potential Impact: High
Full query optimization may require changes to how a query is written, which requires development and testing time that may be hard to obtain. This is why, as the first pass, you may want to focus on adding missing indexes only. This does not require application changes and is reasonably safe (with rare exceptions), and should not change the results of the query.
Check out this webinar for some additional details.
Complexity: Medium
Potential Impact: Medium
Over time, it is common for database schema to accumulate indexes that are duplicate, redundant or unused. Some are added by mistake or misunderstanding, others were valuable in the past but aren’t anymore as the application changed.
You can read more about redundant and duplicate indexes in this blog post. The pt-duplicate-key-checker from Percona Toolkit is also a great tool to find them.
An unused index is a bit more complicated and risky — just because there was no query which needed this index in the last week, does not mean there is no monthly or quarterly report which needs one.
The blog post, Basic Housekeeping for MySQL Indexes, provides a recipe on how to find such indexes. If you’re running MySQL 8, you may consider making such an index invisible for a while before dropping it.




