
In this blog post, I want to share a case we worked on a few days ago. I’ll show you how we approached the resolution of a MySQL performance issue and used Percona Monitoring and Management PMM to support troubleshooting. The customer had noticed a linear high CPU usage in one of their MySQL instances and was not able to figure out why as there was no much traffic hitting the app. We needed to reduce the high CPU usage on MySQL. The server is a small instance:
|
1 2 |
Models | 6xIntel(R) Xeon(R) CPU E5-2430 0 @ 2.20GHz 10GB RAM |
This symptom can be caused by various different reasons. Let’s see how PMM can be used to troubleshoot the issue.
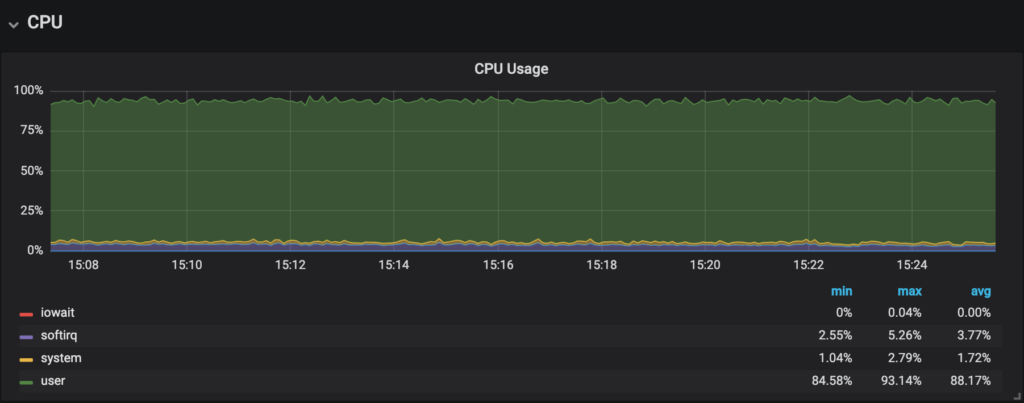
It’s important to understand where the CPU time is being consumed: user space, system space, iowait, and so on. Here we can see that CPU usage was hitting almost 100% and the majority of the time was being spent on user space. In other words, the time the CPU was executing user code, such as MySQL. Once we determined that the time was being spent on user space, we could discard other possible issues. For example, we could eliminate the possibility that a high amount of threads were competing for CPU resources, since that would cause an increase in context switches, which in turn would be taken care of by the kernel – system space.
With that we decided to look into MySQL metrics.
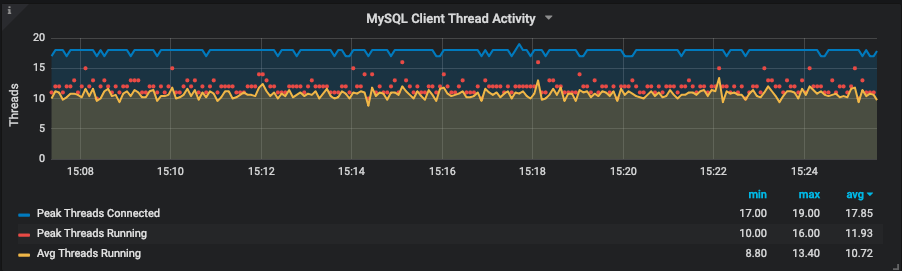
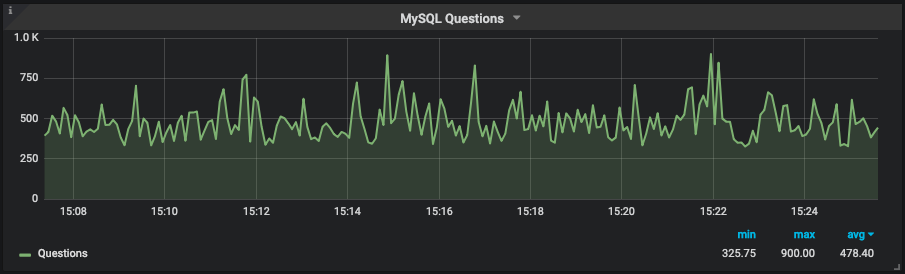
As expected, there weren’t a lot of threads running—10 on average—and MySQL wasn’t being hammered with questions/transactions. It was running from 500 to 800 QPS (queries per second). Next step was to check the type of workload that was running on the instance:
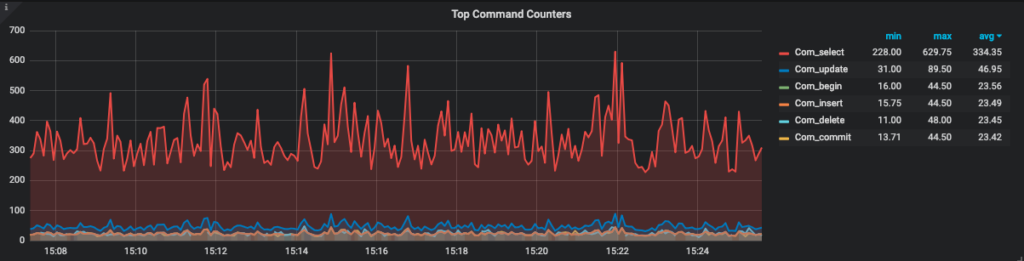
In red we can see that almost all commands are SELECTS. With that in mind, we checked the handlers using SHOW STATUS LIKE 'Handler%' to verify if those selects were doing an index scan, a full table scan or what.
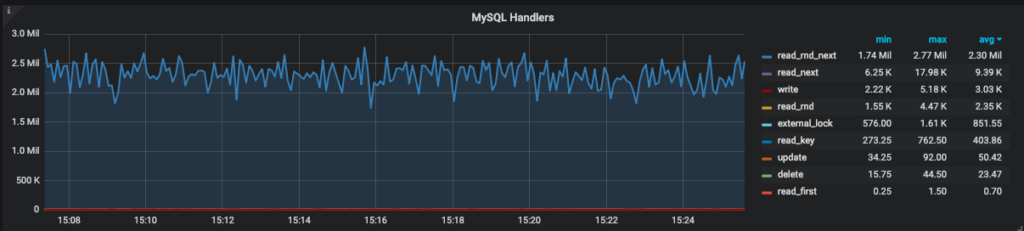
Blue in this graph represents Handler_read_rnd_next , which is the counter MySQL increments every time it reads a row when it’s doing a full table scan. Bingo!!! Around 350 selects were reading 2.5 million rows. But wait—why was this causing CPU issues rather than IO issues? If you refer to the first graph (CPU graph) we cannot see iowait.
That is because the data was stored in the InnoDB Buffer Pool, so instead of having to read those 2.5M rows per second from disk, it was fetching them from memory. The stress had moved from disk to CPU. Now that we identified that the issue had been caused by some queries or query, we went to QAN to verify the queries and check their status:

First query, a SELECT on table store.clients was responsible for 98% of the load and was executing in 20+ seconds.

EXPLAIN confirmed our suspicions. The query was accessing the table using type ALL, which is the last type we want as it means “Full Table Scan”. Taking a look into the fingerprint of the query, we identified that it was a simple query:


The query was filtering clients based on the status field SELECT * FROM store.clients WHERE status = ? As shown in the indexes, that column was not indexed. Talking with the customer, this turned out to be a query that was introduced as part of a new software release.
From that point, we were confident that we had identified the problem. There could be more, but this particular query was definitely hurting the performance of the server. We decided to add an index and also sent an annotation to PMM, so we could refer back to the graphs to check when the index has been added, check if CPU usage had dropped, and also check Handler_read_rnd_next.
To run the alter we decided to use pt-online-schema-change as it was a busy table, and the tool has safeguards to prevent the situation from becoming even worse. For example, we wanted to pause or even abort the alter in the case of the number of Threads_Running exceeding a certain threshold. The threshold is controlled by --max-load (25 by default) and --critical-load (50 by default):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
pmm-admin annotate "Started ALTER store.clients ADD KEY (status)" && pt-online-schema-change --alter "ADD KEY (status)" --execute u=root,D=store,t=clients && pmm-admin annotate "Finished ALTER store.clients ADD KEY (status)" Your annotation was successfully posted. No slaves found. See --recursion-method if host localhost.localdomain has slaves. Not checking slave lag because no slaves were found and --check-slave-lag was not specified. Operation, tries, wait: analyze_table, 10, 1 copy_rows, 10, 0.25 create_triggers, 10, 1 drop_triggers, 10, 1 swap_tables, 10, 1 update_foreign_keys, 10, 1 Altering `store`.`clients`... Creating new table... Created new table store._clients_new OK. Altering new table... Altered `store`.`_clients_new` OK. 2019-02-22T18:26:25 Creating triggers... 2019-02-22T18:27:14 Created triggers OK. 2019-02-22T18:27:14 Copying approximately 4924071 rows... Copying `store`.`clients`: 7% 05:46 remain Copying `store`.`clients`: 14% 05:47 remain Copying `store`.`clients`: 22% 05:07 remain Copying `store`.`clients`: 30% 04:29 remain Copying `store`.`clients`: 38% 03:59 remain Copying `store`.`clients`: 45% 03:33 remain Copying `store`.`clients`: 52% 03:06 remain Copying `store`.`clients`: 59% 02:44 remain Copying `store`.`clients`: 66% 02:17 remain Copying `store`.`clients`: 73% 01:50 remain Copying `store`.`clients`: 79% 01:23 remain Copying `store`.`clients`: 87% 00:53 remain Copying `store`.`clients`: 94% 00:24 remain 2019-02-22T18:34:15 Copied rows OK. 2019-02-22T18:34:15 Analyzing new table... 2019-02-22T18:34:15 Swapping tables... 2019-02-22T18:34:27 Swapped original and new tables OK. 2019-02-22T18:34:27 Dropping old table... 2019-02-22T18:34:32 Dropped old table `store`.`_clients_old` OK. 2019-02-22T18:34:32 Dropping triggers... 2019-02-22T18:34:32 Dropped triggers OK. Successfully altered `store`.`clients`. Your annotation was successfully posted. |
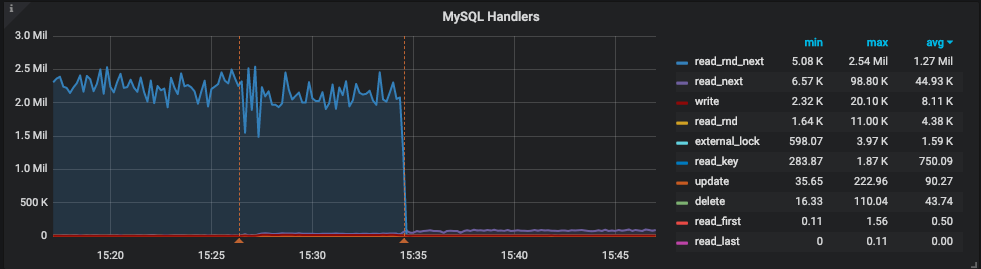
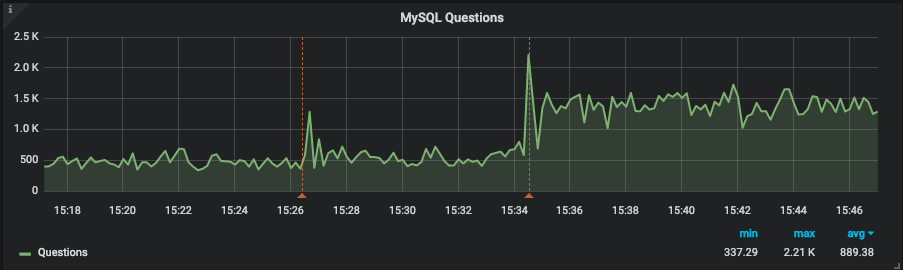

As we can see, above, CPU usage dropped to less than 25%, which is 1/4 of the previous usage level. Handler_read_rnd_next dropped and we can’t even see it once pt-osc has finished. We had a small increase on Handler_read_next as expected because now MySQL is using the index to resolve the WHERE clause. One interesting outcome is that the instance was able to increase it’s QPS by 2x after the index was added as CPU/Full Table Scan was no longer limiting performance. On average, query time has dropped from 20s to only 661ms.
Disclosure: For security reasons, sensitive information, such as database, table, column names have been modified and graphs recreated to simulate a similar problem.





Great article Marcelo!. I recently encountered a similar situation on Oracle where a seemingly infrequent query hurt the performance badly by causing full table scans on a fully buffered table. Symptoms we’re similar, 100% CPU, no disk IO.
I love the way these problems manifest themselves 🙂
Just wonder why this kind of query could NOT be found in slow query log…?!?
Hi vvhung,
You can use slow query log to find those type of queries. Using the slow log together with pt-query-digest will give you similar results.
In the case presented on this blog post, Customer had PMM with QAN installed, so it’s much easier to use whatever is already in place. Also, QAN from PMM gives you compiled information from table / index and so on.
Another thing that worth mentioning is that one of the sources from QAN is in fact MySQL slow log.
the photo
Wondering why the ADD INDEX did not name the filename of the index to be meaningful rather than system generated for future trouble shooting and meaningful names when someone is troubleshooting EXPLAIN results 6 months from now?
Would be interesting to show perf stat -a outputs before and after index addition… sorry I came in late for the comments 😀
Is that still possible while having slaves ?
Any risks in that case ?
Regard.s
G
To be honest, I’m a bit surprised this solved the problem. “status” type of columns usually don’t have a lot of options, in other words, index cardinality would low and mysql woundnt use it.
The query itself seems to be the problem and should be avoided as it easily could return hundreds of thousands records from 4mil+ table IF status has a few options.