
In this blog post, I’ll walk through some of the improvements to the Percona Monitoring and Management (PMM) MySQL dashboard in release 1.4.0.
As the part of Percona Monitoring and Management development, we’re constantly looking for better ways to visualize information and help you to spot and resolve problems faster. We’ve made some updates to the MySQL dashboard in the 1.4.0 release. You can see those improvements in action in our Percona Monitoring and Management Demo Site: check out the MySQL Overview and MySQL InnoDB Metrics dashboards.
MySQL Client Thread Activity
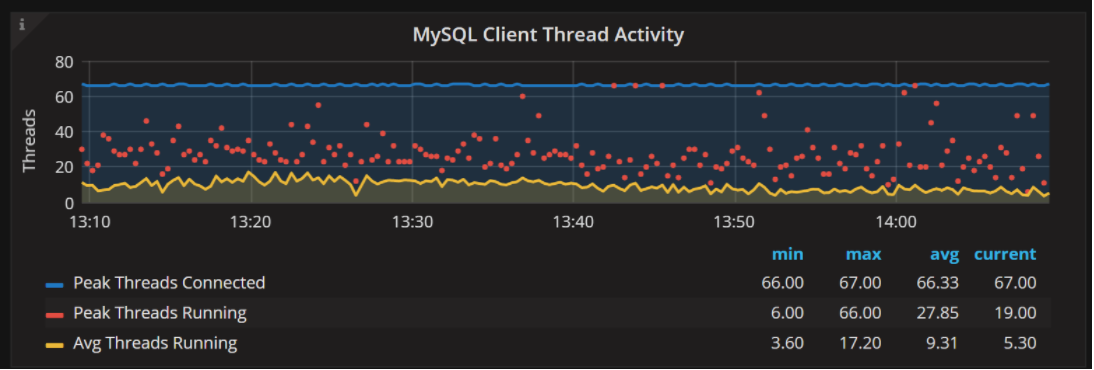
One of the best ways to characterize a MySQL workload is to look at the number of MySQL server-client connections (Threads Connected). You should compare this number to how many of those threads are actually doing something on the server side (Threads Running), rather than just sitting idle waiting for a client to send the next request.
MySQL can handle thousands of connected threads quite well. However, many threads (hundred) running concurrently often increases query latency. Increased internal contention can make the situation much worse.
The problem with those metrics is that they are extremely volatile – one second you might have a lot of threads connected and running, and then none. This is especially true when some stalls on the MySQL level (or higher) causes pile-ups.
To provide better insight, we now show Peak Threads Connected and Peak Threads Running to help easily spot such potential pile-ups, as well as Avg Threads Running. These stats allow you look at a high number of threads connected and running to see if it there are just minor spikes (which tend to happen in many systems on a regular basis), or something more prolonged that warrants deeper investigation.
To simplify it even further: Threads Running spiking for a few seconds is OK, but spikes persisting for 5-10 seconds or more are often signs of problems that are impacting users (or problems about to happen).
InnoDB Logging Performance
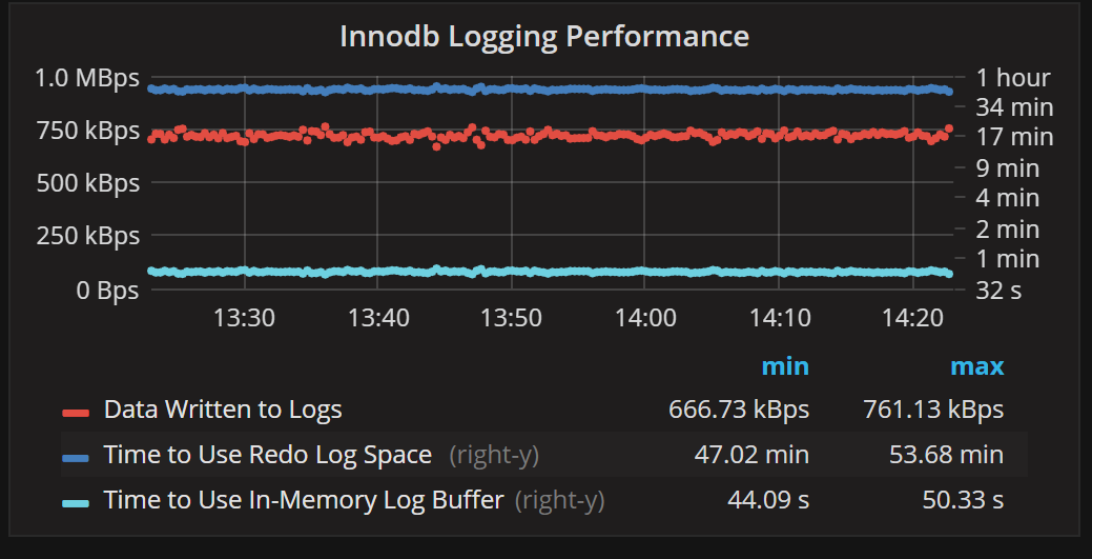
Since I wrote a blog post about Choosing MySQL InnoDB Log File Size, I thought it would be great to check out how long the log file space would last (instead of just looking at how much log space is written per hour). Knowing how long the innodb_log_buffer_size lasts is also helpful for tuning this variable, in general.
This graph shows you how much data is written to the InnoDB Log Files, which helps to understand your disk bandwidth consumption. It also tells you how long it will take to go through your combined Redo Log Space and InnoDB Log Buffer Size (at this rate).
As I wrote in the blog post, there are a lot of considerations for choosing the InnoDB log file size, but having enough log space to accommodate all the changes for an hour is a good rule of thumb. As we can see, this system is close to full at around 50 minutes.
When it comes to innodb_log_buffer_size, even if InnoDB is not configured to flush the log at every transaction commit, it is going to be flushed every second by default. This means 10-15 seconds is usually good enough to accommodate the spikes. This system has it set at about 40 seconds (which is more than enough).
InnoDB Read-Ahead
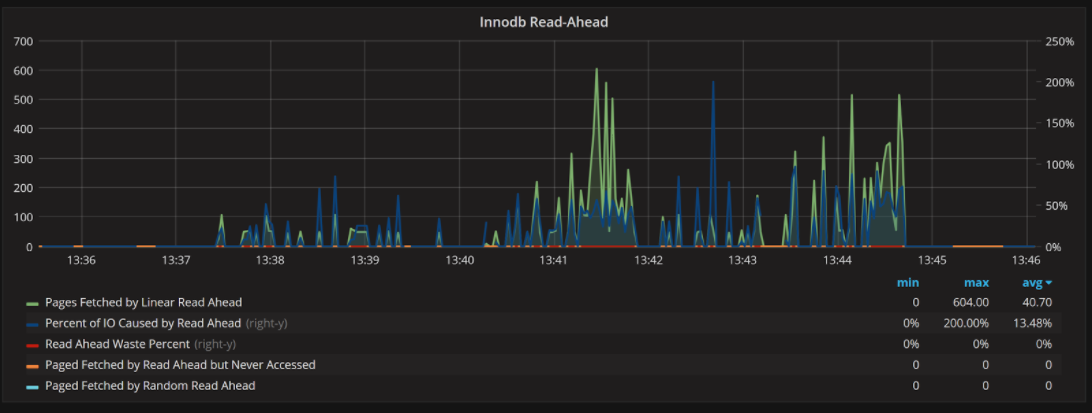
This graph helps you understand how InnoDB Read-Ahead is working out, and is a pretty advanced graph.
In general, Innodb Read-Ahead is not very well understood. I think in most cases it is hard to tell if it is helping or hurting the current workload in its current configuration.
The for Read-Ahead in any system (not just InnoDB) is to pre-fetch data before it is really needed (in order to reduce latency and improve performance). The risk, however, is pre-fetching data that isn’t needed. This is wasteful.
InnoDB has two Read-Ahead options: Linear Read-Ahead (designed to speed up workloads that have physically sequential data access) and Random Read-Ahead (designed to help workloads that tend to access the data in the same vicinity but not in a linear order).
Due to potential overhead, only Linear Read-Ahead is enabled by default. You need to enable Random Read-Ahead separately if you want to determine its impact on your workload
Back to the graph in question: we show a number of pages pre-fetched by Linear and Random Read-Aheads to confirm if these are even in use with your workload. We show Number of Pages Fetched but Never Accessed (evicted without access) – shown as both the number of pages and as a percent of pages. If Fetched but Never Accessed is more than 30% or so, Read-Ahead might be producing more waste instead of helping your workload. It might need tuning.
We also show the portion of IO requests that InnoDB Read-Ahead served, which can help you understand the portion of resources spent on InnoDB Read-Ahead
Due to the timing of how InnoDB increments counters, the percentages of IO used for Read-Ahead and pages evicted without access shows up better on larger scale graphs.
Conclusion
I hope you find these graphs helpful. We’ll continue making Percona Monitoring and Management more helpful for troubleshooting database systems and getting better performance!





Great job!