
In this blog post, I’ll provide some guidance on how to choose the MySQL innodb_log_file_size.
Like many database management systems, MySQL uses logs to achieve data durability (when using the default InnoDB storage engine). This ensures that when a transaction is committed, data is not lost in the event of crash or power loss.
MySQL’s InnoDB storage engine uses a fixed size (circular) Redo log space. The size is controlled by innodb_log_file_size and innodb_log_files_in_group (default 2). You multiply those values and get the Redo log space that available to use. While technically it shouldn’t matter whether you change either the innodb_log_file_size or innodb_log_files_in_group variable to control the Redo space size, most people just work with the innodb_log_file_size and leave innodb_log_files_in_group alone.
Configuring InnoDB’s Redo space size is one of the most important configuration options for write-intensive workloads. However, it comes with trade-offs. The more Redo space you have configured, the better InnoDB can optimize write IO. However, increasing the Redo space also means longer recovery times when the system loses power or crashes for other reasons.
It is not easy or straightforward to predict how much time a system crash recovery takes for a specific innodb_log_file_size value – it depends on the hardware, MySQL version, and workload. It can vary widely (10 times difference or more, depending on the circumstances). However, around five minutes per 1GB of innodb_log_file_size is a decent ballpark number. If this is really important for your environment, I would recommend testing it by a simulating system crash under full load (after the database has completely warmed up).
While recovery time can be a guideline for the limit of the InnoDB Log File size, there are a couple of other ways you can look at this number – especially if you have Percona Monitoring and Management installed.
Check Percona Monitoring and Management’s “MySQL InnoDB Metrics” Dashboard. If you see a graph like this:
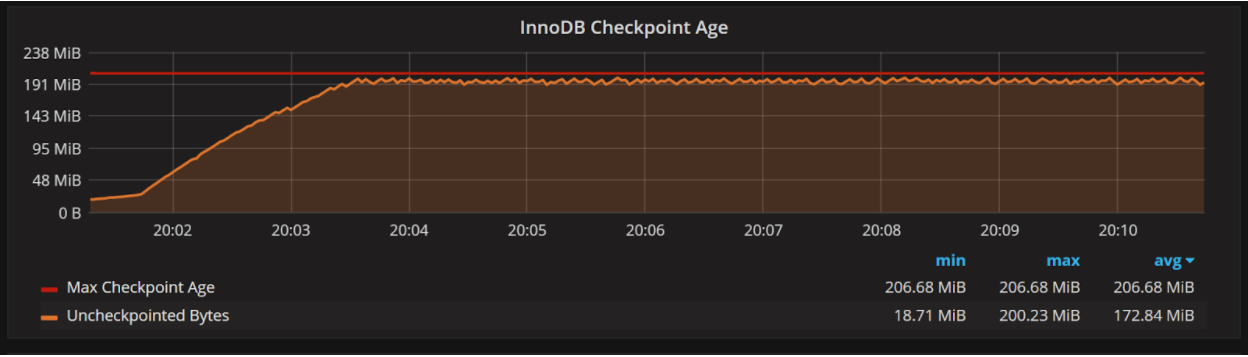
where Uncheckpointed Bytes is pushing very close to the Max Checkpoint Age, you can almost be sure your current innodb_log_file_size is limiting your system’s performance. Increasing it can provide substantial performance improvements.
If you see something like this instead:
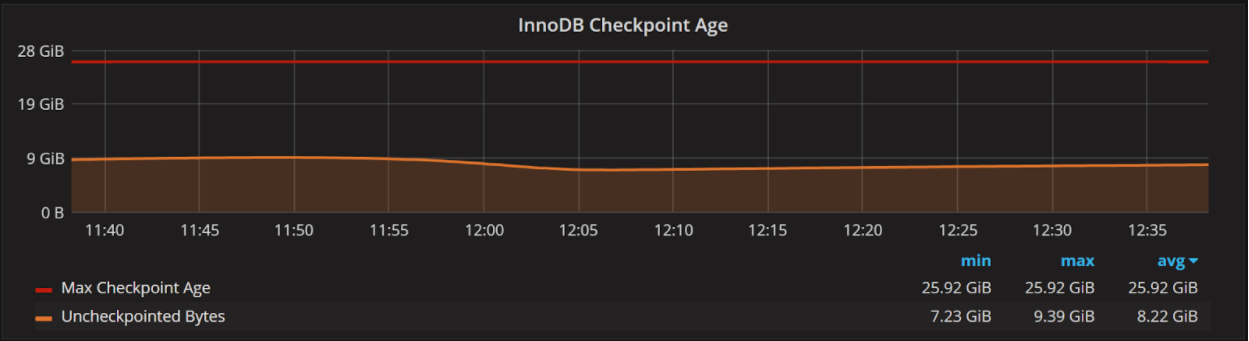
where the number of Uncheckpointed Bytes is well below the Max Checkpoint Age, then increasing the log file size won’t give you a significant improvement.
Note: many MySQL settings are interconnected. While a specific log file size might be good enough for smaller innodb_buffer_pool_size, larger InnoDB Buffer Pool values might warrant larger log files for optimal performance.
Another thing to keep in mind: the recovery time we spoke about early really depends on the Uncheckpointed Bytes rather than total log file size. If you do not see recovery time increasing with a larger innodb_log_file_size, check out InnoDB Checkpoint Age graph – it might be you just can’t fully utilize large log files with your workload and configuration.
Another way to look at the log file size is in the context of log space usage:
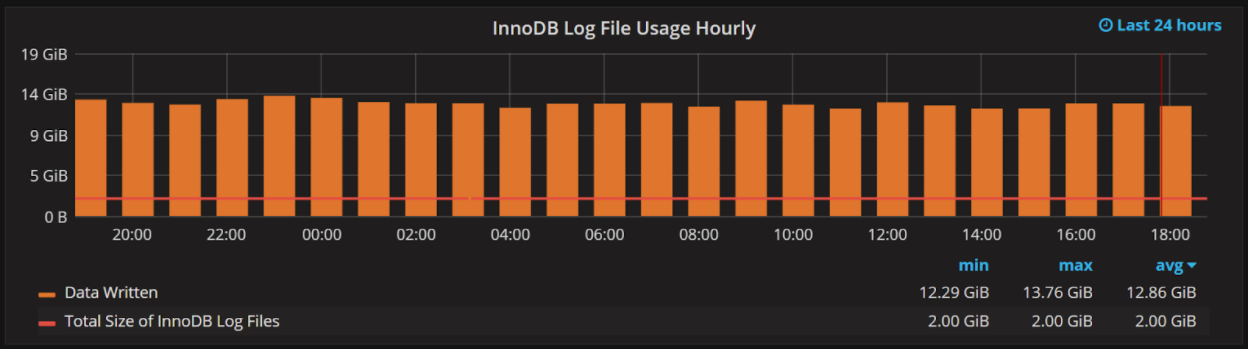
This graph shows the amount of Data Written to the InnoDB log files per hour, as well as the total size of the InnoDB log files. In the graph above, we have 2GB of log space and some 12GB written to the Log files per hour. This means we cycle through logs every ten minutes.
InnoDB has to flush every dirty page in the buffer pool at least once per log file cycle time.
InnoDB gets better performance when it does that less frequently, and there is less wear and tear on SSD devices. I like to see this number at no less than 15 minutes. One hour is even better.
Getting the innodb_log_file_file size is important to achieve the balance between reasonably fast crash recovery time and good system performance. Remember, your recovery time objective is not as trivial as you might imagine. I hope the techniques described in this post help you to find the optimal value for your situation!
Resources
RELATED POSTS





‘@Peter: Thanks for this great article.
Just adding how to calculate per hour write In case of innodb engine by below command-
USER=’root’;PASS=’mypass’ #put root password here-
a=`mysql -u$USER -p$PASS -e”show engine innodb statusG” | grep “Log sequence number” | awk ‘{print $4}’`;mysql -u$USER -p$PASS -e”select sleep(60);”;b=`mysql -u$USER -p$PASS -e”show engine innodb statusG” | grep “Log sequence number” | awk ‘{print $4}’`;mysql -u$USER -p$PASS -e”SELECT ($b – $a)*60/1024/1024 AS MB_per_hour;”
Note: Please share if there is any way to calculate for myisam also.
On a 20 core server with 64 GB of RAM an an SSD drive, it takes exactly 1 minute/1 GB (it takes 4 minutes for the full restart of MySQL, and the total size of the log files is 4 GB)
Clean Restart or Restart with crash recovery ?
Recovery time is governed by the log file size at all, it is governed by the amount of data “in flight”, that is, the amount of log file in use. The amount of log file in use is limited by the total size of the log (upper limit), but could be zero (lower limit) on an idle server.
So it is important to fill up the log file with heavy write load (or at least, typical write log for this server) and then crash the server. That being said, on our servers we are more likely to see your timing that Peter’s timing, but it varies widely. Modern MySQL has gotten quite efficient at Redo Log recovery.