
 High Availability
High AvailabilityHave you ever wondered if your application should be able to work in read-only mode? How important is that question?
MySQL seems to be the most popular database solution for web-based products. Most typical Internet application workloads consist of many reads, with usually few writes. There are exceptions of course – MMO games for instance – but often the number of reads is much bigger then writes. So when your database infrastructure looses its ability to accept writes, either because traditional MySQL replication topology lost its master or Galera cluster lost its quorum, why would you want to the application to declare total downtime? During this scenario, imagine all the users who are just browsing the application (not contributing content): they don’t care if the database cannot accept new data. People also prefer to have access to an application, even if it’s functionality is notably reduced, rather then see the 500 error pages. In some disaster scenarios it is a seriously time-consuming task to perform PITR or recover some valuable data: it is better to at least have the possibility of user read access to a recent backup.
My advice: design your application with the possible read-only partial outage in mind, and test how the application works in that mode during it’s development life cycle. I think it will pay off greatly and increase the perception of availability of your product. As an example, check out some of the big open source projects’ implementation of this concept, like MediaWiki or Drupal (and also some commercial products).
Having said that, I want to highlight a pretty new (and IMHO) important improvement in this regard, introduced in the Galera replication since PXC version 5.6.24. It was already mentioned by my colleague Stéphane in his blog post earlier this year.
As you probably know, one of Galera’s key advantages is their great data consistency care and data-centric approach. No matter where you write in the cluster, all nodes must have the same data. This is important when you realize what happens when a data inconsistency is detected between the nodes. Inconsistent nodes, which cannot apply a writeset due to missing rows or duplicate unique key values for instance, will have to abort and perform an emergency shutdown. This happens in order to remove contaminated members from the cluster, and not spread the data “illness” further. If it does happen that the majority of nodes perform an emergency abort, the remaining minority may loose the cluster quorum and will stop serving further client’s requests. So the price for data consistency protection is availability.
Sometimes a node or node cluster members loose connectivity to others, in a way that >50% of nodes can no longer communicate. Connectivity is lost all of a sudden, without a proper “goodbye” message from the “dissappeared” nodes. These nodes don’t know what the reason was for the lost connection – were the peers killed? or may be networks were split? In that situation, nodes declare a non-Primary cluster state and go into SQL-disabled mode. This is because a member of a cluster without a quorum (majority), hence not acting as Primary Component, is not trusted as it may have inconsistent or old data. Because of this state, it won’t allow the clients to access it.
This is for two reasons. First and unquestionably, we don’t want to allow writes when there is a risk of network split, where the other part of the cluster still forms the Primary Component and keeps operating. We may also want to disallow reads of a stall data, however, when there is a possibility that the other part of the infrastructure already has a lot of newer information.
In the standard MySQL replication process there are no such precautions – if replication is broken in master-master topology both masters can still accept writes, and they can also read anything from the slaves regardless of how much they may be lagging or if they are connected to their masters at all. In Galera though, even if too much lag in the applying queue is detected (similar to replication lag concept), the cluster will pause writes using a Flow Control mechanism. If replication is broken as described above, it will even stop the reads.
This behavior may seem too strict, especially if you just migrated from MySQL replication to PXC, and you just accept that database “slave” nodes can serve the read traffic even if they are separated from the “master.” Or if your application does not rely on writes but mostly on access to existing content. In that case, you can either enable the new wsrep_dirty_reads variable dynamically (per session only if needed), or setup your cluster to run this option by default by placing wsrep_dirty_reads = ON in the my.cnf (global values are acceptable in the config file is available since PXC 5.6.26).
The Galera topology below is something we very often see at customer sites, where WAN locations are configured to communicate via VPN:
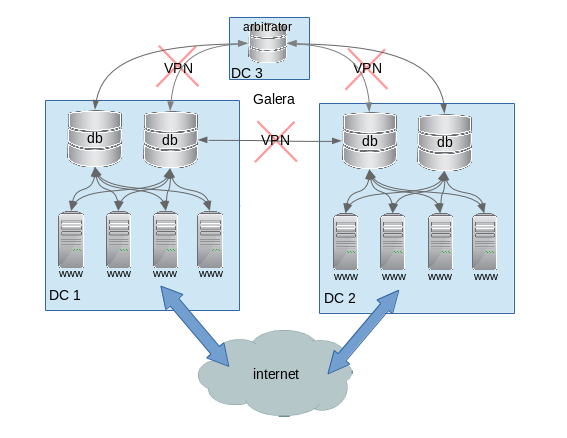 I think this failure scenario is a perfect usage case for wsrep_dirty_reads – where none of the cluster parts are able to work at full functionality alone, but could successfully keep serving read queries to the clients.
I think this failure scenario is a perfect usage case for wsrep_dirty_reads – where none of the cluster parts are able to work at full functionality alone, but could successfully keep serving read queries to the clients.
So let’s quickly see how the cluster member behaves with the wsrep_dirty_reads option disabled and enabled (for the test I blocked network communication on port 4567):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
percona3 mysql> show status like 'wsrep_cluster_status'; +----------------------+-------------+ | Variable_name | Value | +----------------------+-------------+ | wsrep_cluster_status | non-Primary | +----------------------+-------------+ 1 row in set (0.00 sec) percona3 mysql> show variables like '%dirty_reads'; +-------------------+-------+ | Variable_name | Value | +-------------------+-------+ | wsrep_dirty_reads | OFF | +-------------------+-------+ 1 row in set (0.01 sec) percona3 mysql> select * from test.g1; ERROR 1047 (08S01): WSREP has not yet prepared node for application use |
And when enabled:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
percona2 mysql> show status like 'wsrep_cluster_status'; +----------------------+-------------+ | Variable_name | Value | +----------------------+-------------+ | wsrep_cluster_status | non-Primary | +----------------------+-------------+ 1 row in set (0.00 sec) percona2 mysql> show variables like '%dirty_reads'; +-------------------+-------+ | Variable_name | Value | +-------------------+-------+ | wsrep_dirty_reads | ON | +-------------------+-------+ 1 row in set (0.00 sec) percona2 mysql> select * from test.g1; +----+-------+ | id | a | +----+-------+ | 1 | dasda | | 2 | dasda | +----+-------+ 2 rows in set (0.00 sec) percona2 mysql> insert into test.g1 set a="bb"; ERROR 1047 (08S01): WSREP has not yet prepared node for application use |
In traditional replication, you are probably using the slaves for reads anyway. So if the master crashes, and for some reason a failover toolkit like MHA or PRM is not configured or also fails, in order to keep the application working you should direct new connections meant for the master to one of the slaves. If you use a loadbalancer, maybe just have the slaves as backups for the master in the write pool. This may help to achieve a better user experience during the downtime, where everyone can at least use existing information. As noted above, however, the application must be prepared to work that way.
There are caveats to this implementation, as the “read_only” mode that is usually used on slaves is not 100% read-only. This is due to the exception for “super” users. In this case, the new super_read_only variable comes to the rescue (available in Percona Server 5.6) as well as stock MySQL 5.7. With this feature, there is no risk that after pointing database connections to one of the slaves, some special users will change the data.
If a disaster is severe enough, it may be necessary to recover data from a huge SQL dump, and it’s often hard to find enough spare servers to serve the traffic with an old binary snapshot. It’s worth noting that InnoDB has a special read-only mode, meant to be used in a read-only medium, that is lightweight compared to full InnoDB mode.
If you are looking for more information about Galera/PXC availability problems and recovery tips, these earlier blog posts may be interesting:
Percona XtraDB Cluster (PXC): How many nodes do you need?
Percona XtraDB Cluster: Quorum and Availability of the cluster
Galera replication – how to recover a PXC cluster





Hi Przemysław,
Your article is very interessant.
We have a PXC with 5 nodes.
We have 80% reads vs 20% write.
We have a high traffic in our website.
So we need to know if its interressant to enable wsrep_dirty_reads directive when we have a splitbrain in order to keep website in read only.
Thx for your response
Cordialy
Hi.
I’m learning about Percona XtraDB Cluster.I read on perconay docs, see: zero data loss…”, but when I suddently shutdown one node, other can not be create database on rest node….and show “WSREP has not yet prepared node for application use”
please help me..thanks.
Diep, if you take down one node, other(s) in order to continue accepting queries need quorum. This should not happen if you had at least three nodes. Also, “WSREP has not yet prepared node for application use” does not mean you lost any data – PXC is exactly protecting you from loosing/messing the data in case of split brain. But a better place for such questions is our forum board: http://www.percona.com/forums/