
In a previous thread pool post, I mentioned that in Percona Server we used an open source implementation of MariaDB’s thread pool, and enhanced/improved it further. Below I would like to describe some of these improvements for transactional workloads.
When we were evaluating MariaDB’s thread pool implementation, we observed that it improves scalability for AUTOCOMMIT statements. However, it does not scale well with multi-statement transactions. The UPDATE_NO_KEY test which was run as an AUTOCOMMIT statement and inside a transaction gave the following results:
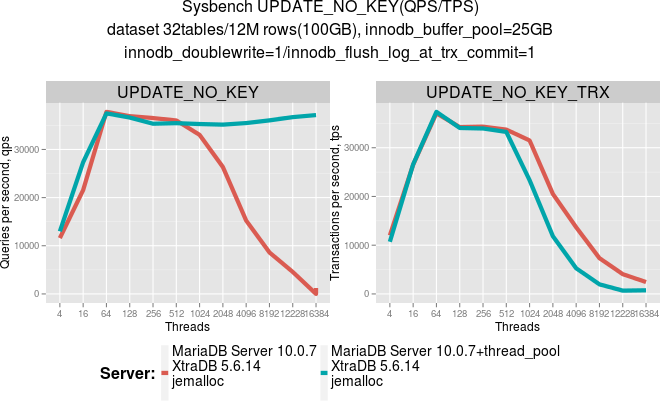
After analysis, we identified the major cause of that inefficiency: High latency between individual statements inside transactions. This looked pretty similar to the case when transactions are executed in parallel without thread pool. Latency there is high as well, though the cause of high latency in these two cases is different.
thread_pool_size groups (or to be more specific into thread_pool_size queues), and latency here comes not from contention as we have much smaller number of parallel threads. It comes from the execution order of individual statements in transactions. Suppose that you have 100 identical transactions (each with 4 statements in it) in the thread group queue. As transactions are processed and executed sequentially, statements of transaction T1 will be placed at the following positions in the thread pool queue: 1…101…201…301…401. So in case of a uniform workload distances between statements in the transaction will be 100. This way transaction T1 may hold server resources during execution of all statements in the thread pool queue between 1 and 401, and that has a negative impact on performance.In an ideal world, the number of concurrent transactions does not matter, as long as we keep the number of concurrent statements sufficiently low. Reality is different though. An open transaction which is not currently executing a statement may still block other connections by holding metadata or row-level locks. On top of that, any MVCC implementation should examine states of all open transactions and thus may perform less efficiently with large numbers of transactions (we blogged about InnoDB-specific problems here and here).
In order to help execute transactions as fast as possible we introduced high and low priority queues for thread pool. Now with default thread pool settings, we check every incoming statement, and if it is from an already started transaction we put it into the the high priority queue, otherwise it will go in the low priority queue.
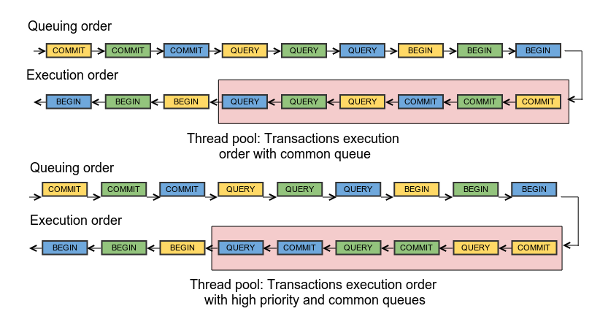
Such reordering allowed to notably reduce latency and resulted in very good scalability up to a very high number of threads. You can find details about this optimization in our documentation.
Now let’s check how these introduced changes will affect the workload we mentioned earlier in this article.
The next graphs show the results for the UPDATE_NO_KEY test that was run as an AUTOCOMMIT statement, and inside a transaction for MariaDB with thread_pool and Percona Server with the thread_pool_high_priority mode=statements – which is very similar to behavior of thread_pool in MariaDB and Percona Server with thread_pool_high_priority mode=transactions – optimization that performs statements reordering of the transactions in the thread pool queue.
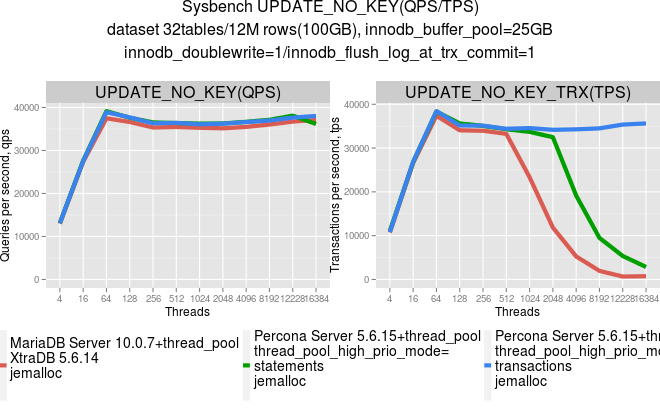
This works even more efficiently on larger transactions like OLTP_RW from sysbench. See the graphs below for the same set of servers:
IO bound: sysbench dataset 32 tables/12M rows each (~100GB), InnoDB buffer pool=25GB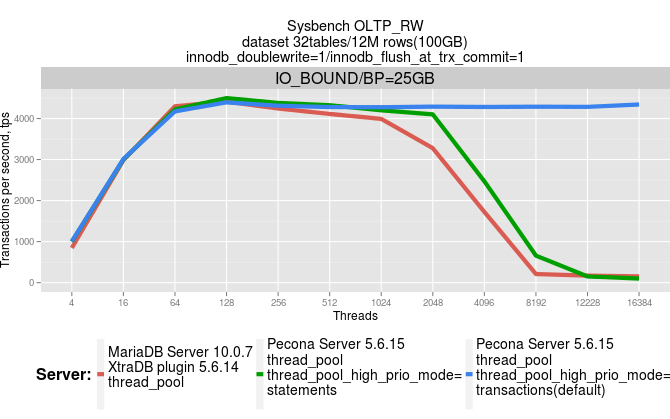
As seen, we get nearly flat throughput with thread_pool_high_prio_mode=transactions even with very high numbers of users connections.





Hi Alexey,
Great Job! Really well written.
Also, it confirmed my fears of drawbacks of thread pool.
‘@shamim: which drawbacks would that be?
In MySQL 5.7.3 –innodb-thread-concurrency does a fairly reasonable job mainly because the CPU bottlenecks around transactions have been addressed. For RO load in fact you shouldn’t need something like a thread pool. For RW loads there are still a few bottlenecks and there –innodb-thread-concurrency seems to work. Crude but effective in practice for most users I would say 🙂
Ran a simple short test up to 7K threads.
@256 threads
LD_PRELOAD=libjemalloc.so.1 sysbench –test=oltp –init-rng=on –oltp-read-only=off –oltp-dist-type=uniform –mysql-socket=/tmp/mysql-sunny.sock –mysql-user=root –max-requests=0 –mysql-table-engine=innodb –max-time=60 –oltp-table-size=10000000 –num-threads=1024 –oltp-table-name=sbtest1 –oltp-test-mode=nontrx –oltp-nontrx-mode=update_nokey –oltp-skip-trx=off run
transactions: 2341523 (38948.73 per sec.)
deadlocks: 0 (0.00 per sec.)
read/write requests: 2341523 (38948.73 per sec.)
other operations: 0 (0.00 per sec.)
@7K threads
LD_PRELOAD=libjemalloc.so.1 sysbench –test=oltp –init-rng=on –oltp-read-only=off –oltp-dist-type=uniform –mysql-socket=/tmp/mysql-sunny.sock –mysql-user=root –max-requests=0 –mysql-table-engine=innodb –max-time=60 –oltp-table-size=10000000 –num-threads=7168 –oltp-table-name=sbtest1 –oltp-test-mode=nontrx –oltp-nontrx-mode=update_nokey –oltp-skip-trx=off run
transactions: 2329971 (38494.97 per sec.)
deadlocks: 0 (0.00 per sec.)
read/write requests: 2329971 (38494.97 per sec.)
other operations: 0 (0.00 per sec.)
Hi Sunny,
Results look very nice indeed. It looks like hunting on the bottlenecks in 5.7 is going quite successful and that’s good. While I agree that innodb-thread-concurrency maybe helpful for large number of client connection we still have waits(various server/innodb locks, IO, networks, etc) that have negative impact on efficiency of the innodb-thread-concurrency. I believe that application aware scheduling is more efficient than uniform one performed by OS scheduler. Besides waits utilization thread pool model allows to implement various scheduling schemes and prioritizations that may be very helpful in many scenarios.
So I would see innodb-thread-concurrency as a simple/quick solution to deal with resource contention while thread pool is much more advanced approach that not only helps to deal with high concurrency but also provides additional flexible ways to manage SQL traffic.
Ranger,
That’s why I clarified that the thread concurrency solution is crude/simple/quick but effective in 5.7.3+ :-). The TP is advanced for sure, no disagreement there, but if you get the same end result up to 7K (haven’t tested more than that) then in practice I don’t really see the need for TP, but to each their own.
As you are aware that I’ve never been a big fan of innodb-thread-concurrency :-), when we worked on the new thread concurrency code together, but it has ended up becoming useful in 5.7. Dimitri actually pointed this out to me after he ran some tests.
Regards,
-sunny
Sunny,
Great results! Thanks for sharing!
Very interesting result, I decide to port this feature and test it!
Hi,Alexey,
May I know your email contact? I am evaluating my memory allocator on mysql and wondering how to reply the experiments you did on it. May you please tell me the configuration of your mysql and how did you control the number of threads for mysql and your tested benchmarks?
Thanks,