
A few days ago I wrote about MySQL performance implications of InnoDB isolation modes and I touched briefly upon the bizarre performance regression I found with InnoDB handling a large amount of versions for a single row. Today I wanted to look a bit deeper into the problem, which I also filed as a bug.
First I validated in which conditions the problem happens. It seems to happen only in REPEATABLE-READ isolation mode and only in case there is some hot rows which get many row versions during a benchmark run. For example the problem does NOT happen if I run sysbench with “uniform” distribution.
In terms of concurrent selects it also seems to require some very special conditions – you need to have the connection to let some history accumulate by having read snapshot open and then do it again with high history. The exact queries to do that seems not to be that important.
Contrary to what I expected this problem also does not require multiple connections – I can repeat it with only one read and one write connection, which means it can happen in a lot more workloads.
Here is the simplified case to repeat it:
|
1 |
sysbench --num-threads=1 --report-interval=10 --max-time=0 --max-requests=0 --rand-type=uniform --oltp-table-size=1 --mysql-user=root --mysql-password= --mysql-db=sbinnodb --test=/usr/share/doc/sysbench/tests/db/update_index.lua run |
It is repeatable on the table with just 1 row where this row is very hot!
Select query sequence:
|
1 2 3 4 5 6 7 8 |
begin; select c from sbtest1 limit 1; select sleep(20); commit; begin; select c from sbtest1 limit 1; select sleep(300); commit; |
It is interesting though, in this case it does not look like it is enough to open a consistent snapshot – it is only when I run the query on the same table as the update workload is running (I assume touches the same data) when the issue happens.
Let’s look at some graphs:
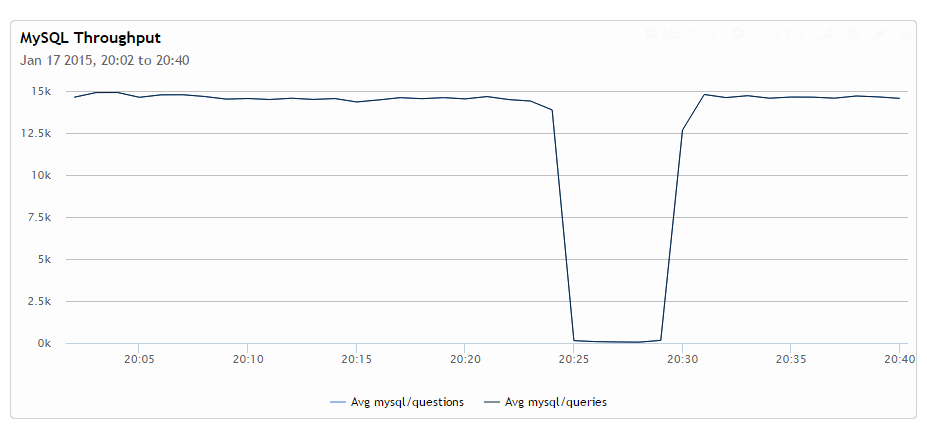
The transaction rate indeed suffers dramatically – in this case going down more than 100x from close to 15K to around 60 in the lowest point.
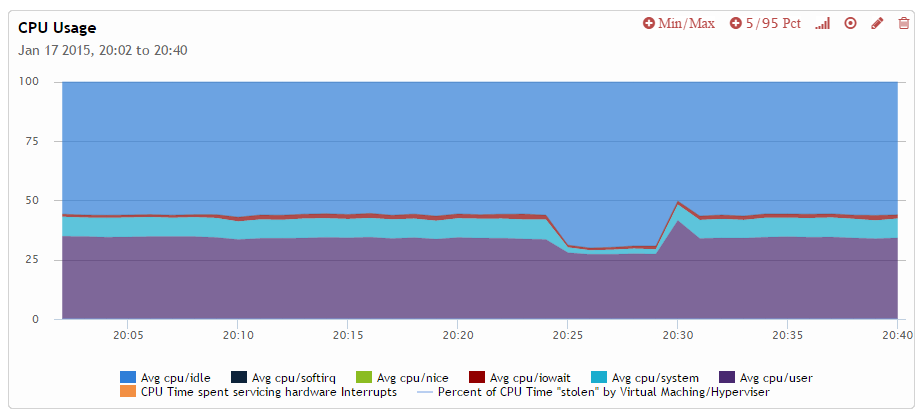
It is interesting that CPU consumption is reduced but not as much as the throughput.
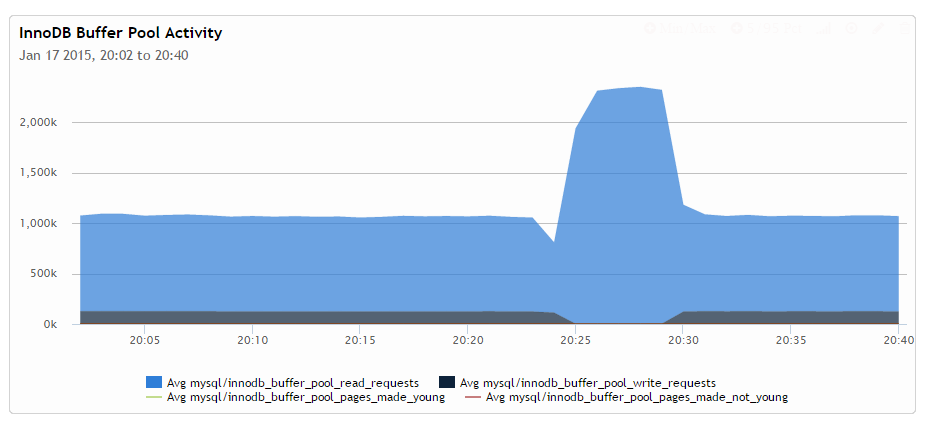
This is something I find the most enlightening about what seems to happen. The number of buffer pool read requests increases dramatically where the number of transactions goes down. If we do the math we have 940K buffer pool reads per 14.5K updates in the normal case giving us 65 buffer reads per update, which goes up to 37000 per update when we have regression happening. Which is a dramatic change and it points to something that goes badly wrong.
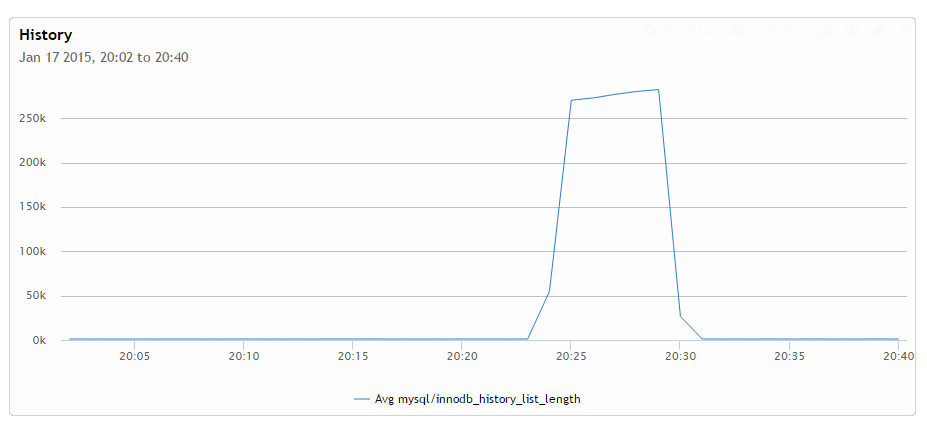
History size is of interest. We can see it grows quickly first – this is when we have the first transaction and sleep(20) and when it grows very slowly when the second transaction is open as update rate is low. Finally it goes to zero very quickly once the transaction is committed. What is worth noting is the history length here peaks at just 280K which is really quite trivial size.
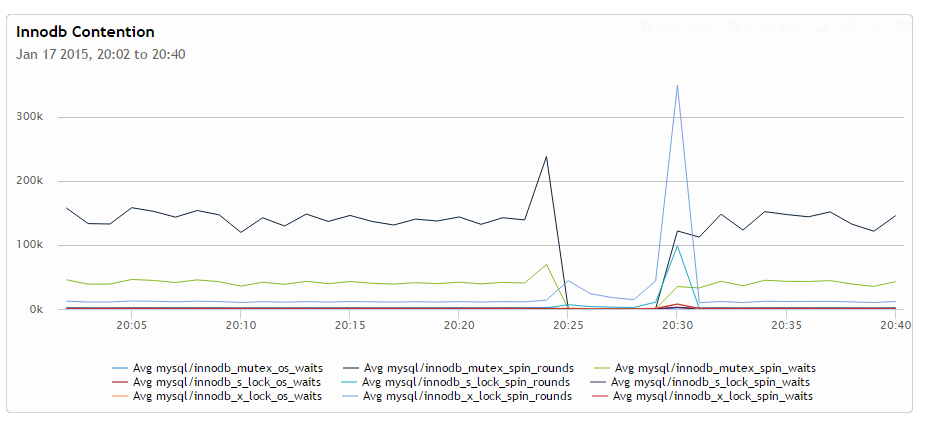
The InnoDB contention graph is interesting from 2 view points. First it shows that the contention picture changes at the time when the transaction is held open and also right afterward when history is being worked out.
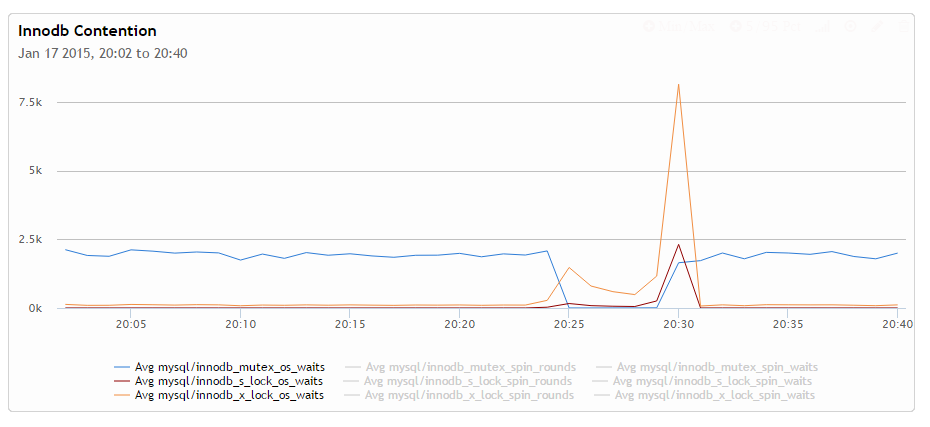
If you look at this graph focused only on the os_wait metrics we can see that mutex_os_waits goes down during the problem while x-locks os waits increases significantly. This means there are some very long exclusive lock os-waits happening which is indicative of the long waits. We can’t actually lock times from status variables – we would need to get data from performance schema for that which unfortunately does not cover key mutexes, and which I unfortunately can’t graph easily yet.
Lets look at some more data.
From the great processlist from sys-schema we can get:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
*************************** 4. row *************************** thd_id: 536 conn_id: 516 user: root@localhost db: sbinnodb command: Query state: updating time: 0 current_statement: UPDATE sbtest1 SET k=k+1 WHERE id=1 lock_latency: 36.00 us rows_examined: 1 rows_sent: 0 rows_affected: 0 tmp_tables: 0 tmp_disk_tables: 0 full_scan: NO last_statement: NULL last_statement_latency: NULL last_wait: wait/io/table/sql/handler last_wait_latency: Still Waiting source: handler.cc:7692 |
Which is unfortunately not very helpful as it does not show the actual lock which is being waited on – just saying that it is waiting somewhere inside storage engine call which is obvious.
We can get some good summary information in the other table:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 |
mysql> select * from waits_global_by_latency; +------------------------------------------------------+-----------+---------------+-------------+-------------+ | events | total | total_latency | avg_latency | max_latency | +------------------------------------------------------+-----------+---------------+-------------+-------------+ | wait/synch/cond/sql/Item_func_sleep::cond | 384 | 00:31:27.18 | 4.91 s | 5.00 s | | wait/synch/rwlock/innodb/index_tree_rw_lock | 239460870 | 00:12:13.82 | 3.06 us | 495.27 ms | | wait/synch/mutex/sql/THD::LOCK_thd_data | 601160083 | 36.48 s | 60.41 ns | 643.18 us | | wait/io/table/sql/handler | 1838 | 29.12 s | 15.84 ms | 211.21 ms | | wait/synch/mutex/mysys/THR_LOCK::mutex | 240456674 | 16.57 s | 68.86 ns | 655.16 us | | wait/synch/cond/sql/MDL_context::COND_wait_status | 15 | 14.11 s | 940.37 ms | 999.36 ms | | wait/synch/mutex/innodb/trx_mutex | 360685304 | 10.52 s | 29.11 ns | 4.01 ms | | wait/synch/mutex/innodb/trx_undo_mutex | 120228229 | 3.87 s | 31.93 ns | 426.16 us | | wait/io/file/innodb/innodb_data_file | 399 | 1.46 s | 3.66 ms | 11.21 ms | | wait/synch/mutex/innodb/buf_pool_flush_state_mutex | 32317 | 587.10 ms | 18.17 us | 11.27 ms | | wait/synch/rwlock/innodb/fil_space_latch | 4154178 | 386.96 ms | 92.96 ns | 74.57 us | | wait/io/file/innodb/innodb_log_file | 987 | 271.76 ms | 275.34 us | 14.23 ms | | wait/synch/rwlock/innodb/hash_table_locks | 8509138 | 255.76 ms | 30.05 ns | 53.41 us | | wait/synch/mutex/innodb/srv_threads_mutex | 11938747 | 249.49 ms | 20.66 ns | 15.06 us | | wait/synch/rwlock/innodb/trx_purge_latch | 8488041 | 181.01 ms | 21.28 ns | 23.51 us | | wait/synch/rwlock/innodb/dict_operation_lock | 232 | 100.48 ms | 433.09 us | 61.88 ms | | wait/synch/rwlock/innodb/checkpoint_lock | 10 | 32.34 ms | 3.23 ms | 8.38 ms | | wait/io/socket/sql/client_connection | 2171 | 30.87 ms | 14.22 us | 3.95 ms | | wait/synch/mutex/innodb/log_sys_mutex | 260485 | 6.57 ms | 25.04 ns | 52.00 us | | wait/synch/rwlock/innodb/btr_search_latch | 4982 | 1.71 ms | 343.05 ns | 17.83 us | | wait/io/file/myisam/kfile | 647 | 1.70 ms | 2.63 us | 39.28 us | | wait/synch/rwlock/innodb/dict_table_stats | 46323 | 1.63 ms | 35.06 ns | 6.55 us | | wait/synch/mutex/innodb/os_mutex | 11410 | 904.63 us | 79.19 ns | 26.67 us | | wait/lock/table/sql/handler | 1838 | 794.21 us | 431.94 ns | 9.70 us | | wait/synch/rwlock/sql/MDL_lock::rwlock | 7056 | 672.34 us | 95.15 ns | 53.29 us | | wait/io/file/myisam/dfile | 139 | 518.50 us | 3.73 us | 31.61 us | | wait/synch/mutex/sql/LOCK_global_system_variables | 11692 | 462.58 us | 39.44 ns | 363.39 ns | | wait/synch/mutex/innodb/rseg_mutex | 7238 | 348.25 us | 47.89 ns | 10.38 us | | wait/synch/mutex/innodb/lock_mutex | 5747 | 222.13 us | 38.50 ns | 9.84 us | | wait/synch/mutex/innodb/trx_sys_mutex | 4601 | 187.43 us | 40.69 ns | 326.15 ns | | wait/synch/mutex/sql/LOCK_table_cache | 2173 | 185.14 us | 85.14 ns | 10.02 us | | wait/synch/mutex/innodb/fil_system_mutex | 3481 | 144.60 us | 41.32 ns | 375.91 ns | | wait/synch/rwlock/sql/LOCK_grant | 1217 | 121.86 us | 99.85 ns | 12.07 us | | wait/synch/mutex/innodb/flush_list_mutex | 3191 | 108.82 us | 33.80 ns | 8.81 us | | wait/synch/mutex/innodb/purge_sys_bh_mutex | 3600 | 83.52 us | 23.16 ns | 123.95 ns | | wait/synch/mutex/sql/MDL_map::mutex | 1456 | 75.02 us | 51.33 ns | 8.78 us | | wait/synch/mutex/myisam/MYISAM_SHARE::intern_lock | 1357 | 55.55 us | 40.69 ns | 320.51 ns | | wait/synch/mutex/innodb/log_flush_order_mutex | 204 | 40.84 us | 200.01 ns | 9.42 us | | wait/io/file/sql/FRM | 16 | 31.16 us | 1.95 us | 16.40 us | | wait/synch/mutex/mysys/BITMAP::mutex | 378 | 30.52 us | 80.44 ns | 9.16 us | | wait/synch/mutex/innodb/dict_sys_mutex | 463 | 24.15 us | 51.96 ns | 146.17 ns | | wait/synch/mutex/innodb/buf_pool_LRU_list_mutex | 293 | 23.37 us | 79.50 ns | 313.94 ns | | wait/synch/mutex/innodb/buf_dblwr_mutex | 398 | 22.60 us | 56.65 ns | 380.61 ns | | wait/synch/rwlock/myisam/MYISAM_SHARE::key_root_lock | 388 | 14.86 us | 38.19 ns | 254.16 ns | | wait/synch/mutex/sql/LOCK_plugin | 250 | 14.30 us | 56.97 ns | 137.41 ns | | wait/io/socket/sql/server_unix_socket | 2 | 9.35 us | 4.67 us | 4.72 us | | wait/synch/mutex/sql/THD::LOCK_temporary_tables | 216 | 8.97 us | 41.32 ns | 465.74 ns | | wait/synch/mutex/sql/hash_filo::lock | 151 | 8.35 us | 55.09 ns | 150.87 ns | | wait/synch/mutex/mysys/THR_LOCK_open | 196 | 7.84 us | 39.75 ns | 110.80 ns | | wait/synch/mutex/sql/TABLE_SHARE::LOCK_ha_data | 159 | 6.23 us | 39.13 ns | 108.92 ns | | wait/synch/mutex/innodb/lock_wait_mutex | 29 | 5.38 us | 185.30 ns | 240.38 ns | | wait/synch/mutex/innodb/ibuf_mutex | 29 | 5.26 us | 181.23 ns | 249.46 ns | | wait/synch/mutex/sql/LOCK_status | 62 | 4.12 us | 66.36 ns | 127.39 ns | | wait/synch/mutex/sql/LOCK_open | 109 | 4.05 us | 36.93 ns | 105.79 ns | | wait/io/file/sql/dbopt | 3 | 3.34 us | 1.11 us | 1.99 us | | wait/synch/mutex/innodb/buf_pool_free_list_mutex | 30 | 1.58 us | 52.58 ns | 106.73 ns | | wait/synch/mutex/innodb/srv_innodb_monitor_mutex | 31 | 1.38 us | 44.45 ns | 89.52 ns | | wait/synch/mutex/sql/LOCK_thread_count | 33 | 1.10 us | 33.18 ns | 50.71 ns | | wait/synch/mutex/sql/LOCK_prepared_stmt_count | 32 | 1.10 us | 34.12 ns | 67.92 ns | | wait/synch/mutex/innodb/srv_sys_mutex | 42 | 1.07 us | 25.35 ns | 49.14 ns | | wait/synch/mutex/mysys/KEY_CACHE::cache_lock | 24 | 1.02 us | 42.26 ns | 103.60 ns | | wait/synch/mutex/sql/MDL_wait::LOCK_wait_status | 18 | 544.62 ns | 30.05 ns | 42.57 ns | | wait/synch/rwlock/sql/CRYPTO_dynlock_value::lock | 2 | 509.25 ns | 254.47 ns | 287.02 ns | | wait/synch/rwlock/sql/LOCK_dboptions | 6 | 262.92 ns | 43.82 ns | 84.82 ns | | wait/synch/rwlock/sql/MDL_context::LOCK_waiting_for | 4 | 262.92 ns | 65.73 ns | 103.60 ns | | wait/synch/mutex/sql/LOCK_connection_count | 4 | 238.51 ns | 59.47 ns | 123.01 ns | | wait/synch/mutex/sql/LOCK_sql_rand | 2 | 172.15 ns | 86.08 ns | 94.84 ns | | wait/synch/rwlock/sql/LOCK_system_variables_hash | 2 | 141.16 ns | 70.43 ns | 78.25 ns | | wait/synch/rwlock/sql/gtid_commit_rollback | 2 | 95.47 ns | 47.58 ns | 51.65 ns | | wait/synch/mutex/innodb/autoinc_mutex | 2 | 90.14 ns | 45.07 ns | 45.07 ns | | wait/synch/mutex/sql/LOCK_thd_remove | 2 | 85.14 ns | 42.57 ns | 52.58 ns | | wait/synch/mutex/innodb/ibuf_bitmap_mutex | 1 | 76.37 ns | 76.37 ns | 76.37 ns | | wait/synch/mutex/sql/LOCK_xid_cache | 2 | 62.91 ns | 31.30 ns | 34.43 ns | +------------------------------------------------------+-----------+---------------+-------------+-------------+ 73 rows in set (0.00 sec) |
Which shows a couple of hotspots – the well-known index_tree_rw_lock hotspot which should be gone in MySQL 5.7 as well as trx_mutex and trx_undo_mutexes. It is especially worth noting the almost 500ms which this index tree lw_lock was waited at max (this is the data for a couple of minutes only, so it it is unlikely to be a very rare outlier). This hints to me that in the case of many versions our index_tree_rw_lock might be held for a prolonged period of time.
What is interesting is that the reliable “SHOW ENGINE INNODB STATUS” remains quite handy:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
---------- SEMAPHORES ---------- OS WAIT ARRAY INFO: reservation count 58847289 --Thread 140386357991168 has waited at btr0cur.cc line 304 for 0.0000 seconds the semaphore: X-lock on RW-latch at 0x7fb0bea2ca40 '&block->lock' a writer (thread id 140386454755072) has reserved it in mode exclusive number of readers 0, waiters flag 1, lock_word: 0 Last time read locked in file buf0flu.cc line 1082 Last time write locked in file /mnt/workspace/percona-server-5.6-debian-binary/label_exp/ubuntu-trusty-64bit/percona-server-5.6-5.6.21-70.1/storage/innobase/row /row0row.cc line 815 --Thread 140386374776576 has waited at btr0cur.cc line 577 for 0.0000 seconds the semaphore: X-lock on RW-latch at 0x7fade8077f98 '&new_index->lock' a writer (thread id 140386357991168) has reserved it in mode exclusive number of readers 0, waiters flag 1, lock_word: 0 Last time read locked in file btr0cur.cc line 586 Last time write locked in file /mnt/workspace/percona-server-5.6-debian-binary/label_exp/ubuntu-trusty-64bit/percona-server-5.6-5.6.21-70.1/storage/innobase/btr /btr0cur.cc line 577 --Thread 140386324420352 has waited at btr0cur.cc line 577 for 0.0000 seconds the semaphore: X-lock on RW-latch at 0x7fade8077f98 '&new_index->lock' a writer (thread id 140386357991168) has reserved it in mode exclusive number of readers 0, waiters flag 1, lock_word: 0 Last time read locked in file btr0cur.cc line 586 Last time write locked in file /mnt/workspace/percona-server-5.6-debian-binary/label_exp/ubuntu-trusty-64bit/percona-server-5.6-5.6.21-70.1/storage/innobase/btr /btr0cur.cc line 577 --Thread 140386332813056 has waited at btr0cur.cc line 577 for 0.0000 seconds the semaphore: X-lock on RW-latch at 0x7fade8077f98 '&new_index->lock' a writer (thread id 140386357991168) has reserved it in mode exclusive number of readers 0, waiters flag 1, lock_word: 0 Last time read locked in file btr0cur.cc line 586 Last time write locked in file /mnt/workspace/percona-server-5.6-debian-binary/label_exp/ubuntu-trusty-64bit/percona-server-5.6-5.6.21-70.1/storage/innobase/btr /btr0cur.cc line 577 --Thread 140386445960960 has waited at btr0cur.cc line 586 for 0.0000 seconds the semaphore: S-lock on RW-latch at 0x7fade8077f98 '&new_index->lock' a writer (thread id 140386357991168) has reserved it in mode exclusive number of readers 0, waiters flag 1, lock_word: 0 Last time read locked in file btr0cur.cc line 586 Last time write locked in file /mnt/workspace/percona-server-5.6-debian-binary/label_exp/ubuntu-trusty-64bit/percona-server-5.6-5.6.21-70.1/storage/innobase/btr /btr0cur.cc line 577 --Thread 140386366383872 has waited at btr0cur.cc line 577 for 0.0000 seconds the semaphore: X-lock on RW-latch at 0x7fade8077f98 '&new_index->lock' a writer (thread id 140386357991168) has reserved it in mode exclusive number of readers 0, waiters flag 1, lock_word: 0 Last time read locked in file btr0cur.cc line 586 Last time write locked in file /mnt/workspace/percona-server-5.6-debian-binary/label_exp/ubuntu-trusty-64bit/percona-server-5.6-5.6.21-70.1/storage/innobase/btr /btr0cur.cc line 577 --Thread 140386341205760 has waited at btr0cur.cc line 577 for 0.0000 seconds the semaphore: X-lock on RW-latch at 0x7fade8077f98 '&new_index->lock' a writer (thread id 140386357991168) has reserved it in mode exclusive number of readers 0, waiters flag 1, lock_word: 0 Last time read locked in file btr0cur.cc line 586 Last time write locked in file /mnt/workspace/percona-server-5.6-debian-binary/label_exp/ubuntu-trusty-64bit/percona-server-5.6-5.6.21-70.1/storage/innobase/btr /btr0cur.cc line 577 --Thread 140386349598464 has waited at btr0cur.cc line 577 for 0.0000 seconds the semaphore: X-lock on RW-latch at 0x7fade8077f98 '&new_index->lock' a writer (thread id 140386357991168) has reserved it in mode exclusive number of readers 0, waiters flag 1, lock_word: 0 Last time read locked in file btr0cur.cc line 586 Last time write locked in file /mnt/workspace/percona-server-5.6-debian-binary/label_exp/ubuntu-trusty-64bit/percona-server-5.6-5.6.21-70.1/storage/innobase/btr /btr0cur.cc line 577 |
Another sample….
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
---------- SEMAPHORES ---------- OS WAIT ARRAY INFO: reservation count 61753307 --Thread 140386332813056 has waited at row0row.cc line 815 for 0.0000 seconds the semaphore: X-lock on RW-latch at 0x7fb0bea2cd40 '&block->lock' a writer (thread id 140386454755072) has reserved it in mode exclusive number of readers 0, waiters flag 1, lock_word: 0 Last time read locked in file buf0flu.cc line 1082 Last time write locked in file /mnt/workspace/percona-server-5.6-debian-binary/label_exp/ubuntu-trusty-64bit/percona-server-5.6-5.6.21-70.1/storage/innobase/row/row0row.cc line 815 --Thread 140386366383872 has waited at row0row.cc line 815 for 0.0000 seconds the semaphore: X-lock on RW-latch at 0x7fb0bea2cd40 '&block->lock' a writer (thread id 140386454755072) has reserved it in mode exclusive number of readers 0, waiters flag 1, lock_word: 0 Last time read locked in file buf0flu.cc line 1082 Last time write locked in file /mnt/workspace/percona-server-5.6-debian-binary/label_exp/ubuntu-trusty-64bit/percona-server-5.6-5.6.21-70.1/storage/innobase/row/row0row.cc line 815 --Thread 140386341205760 has waited at row0row.cc line 815 for 0.0000 seconds the semaphore: X-lock on RW-latch at 0x7fb0bea2cd40 '&block->lock' a writer (thread id 140386454755072) has reserved it in mode exclusive number of readers 0, waiters flag 1, lock_word: 0 Last time read locked in file buf0flu.cc line 1082 Last time write locked in file /mnt/workspace/percona-server-5.6-debian-binary/label_exp/ubuntu-trusty-64bit/percona-server-5.6-5.6.21-70.1/storage/innobase/row/row0row.cc line 815 --Thread 140386374776576 has waited at row0row.cc line 815 for 0.0000 seconds the semaphore: X-lock on RW-latch at 0x7fb0bea2cd40 '&block->lock' a writer (thread id 140386454755072) has reserved it in mode exclusive number of readers 0, waiters flag 1, lock_word: 0 Last time read locked in file buf0flu.cc line 1082 Last time write locked in file /mnt/workspace/percona-server-5.6-debian-binary/label_exp/ubuntu-trusty-64bit/percona-server-5.6-5.6.21-70.1/storage/innobase/row/row0row.cc line 815 --Thread 140386445960960 has waited at btr0cur.cc line 257 for 0.0000 seconds the semaphore: X-lock (wait_ex) on RW-latch at 0x7fb0bea2f2c0 '&block->lock' a writer (thread id 140386445960960) has reserved it in mode wait exclusive number of readers 1, waiters flag 0, lock_word: ffffffffffffffff Last time read locked in file btr0cur.cc line 257 Last time write locked in file /mnt/workspace/percona-server-5.6-debian-binary/label_exp/ubuntu-trusty-64bit/percona-server-5.6-5.6.21-70.1/storage/innobase/btr/btr0cur.cc line 257 OS WAIT ARRAY INFO: signal count 45260762 Mutex spin waits 1524575466, rounds 5092199292, OS waits 43431355 RW-shared spins 14500456, rounds 258217222, OS waits 3721069 RW-excl spins 37764438, rounds 730059390, OS waits 12592324 Spin rounds per wait: 3.34 mutex, 17.81 RW-shared, 19.33 RW-excl |
The first one shows mostly index lock contention which we have already seen. The second, though, shows a lot of contention on the block lock, which is something that is not covered by performance schema instrumentation in MySQL 5.6.
Now to tell the truth in this 2nd thread test case it is not your typical case of contention – unlike the case with 64 threads we do not see that drastic CPU drop and it still stays above 25%, the single thread fully saturated should show on this system. This is however where DBA level profiling gets tough with MySQL – as I mentioned the only indication of excessive activity going on is a high number of buffer pool requests – there is no instrumentation which I’m aware of that tells us anything around scanning many old row versions in undo space. Perhaps some more metrics around this syssystem need to be added to INNODB_METRICS?
A good tool to see CPU consumption which both developers and DBAs can use is oprofile, which is of low enough overhead to use in production. Note that to get any meaningful information about the CPU usage inside the program you need to have debug systems installed. For Percona Server 5.6 On Ubuntu you can do apt-get install percona-server-5.6-dbg
To profile just the MySQL Process you can do:
|
1 2 3 4 5 |
root@ts140i:~# operf --pid 8970 operf: Press Ctl-c or 'kill -SIGINT 9113' to stop profiling operf: Profiler started ^C Profiling done. |
To get top symbols (functions) called in mysqld I can do:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
root@ts140i:~# opreport -l | more Using /root/oprofile_data/samples/ for samples directory. warning: /no-vmlinux could not be found. warning: [vdso] (tgid:8970 range:0x7fffba5fe000-0x7fffba5fffff) could not be found. CPU: Intel Haswell microarchitecture, speed 3.201e+06 MHz (estimated) Counted CPU_CLK_UNHALTED events (Clock cycles when not halted) with a unit mask of 0x00 (No unit mask) count 100000 samples % image name symbol name 212162 12.4324 mysqld buf_page_get_gen(unsigned long, unsigned long, unsigned long, unsigned long, buf_block_t*, unsigned long, char const*, unsigned long, mtr_t*) 204230 11.9676 mysqld dict_table_copy_types(dtuple_t*, dict_table_t const*) 179783 10.5351 no-vmlinux /no-vmlinux 144335 8.4579 mysqld trx_undo_update_rec_get_update(unsigned char*, dict_index_t*, unsigned long, unsigned long, unsigned long, unsigned long, trx_t*, mem_block_info_t*, upd_t **) 95984 5.6245 mysqld trx_undo_prev_version_build(unsigned char const*, mtr_t*, unsigned char const*, dict_index_t*, unsigned long*, mem_block_info_t*, unsigned char**) 78785 4.6167 mysqld row_build(unsigned long, dict_index_t const*, unsigned char const*, unsigned long const*, dict_table_t const*, dtuple_t const*, unsigned long const*, row_ ext_t**, mem_block_info_t*) 76656 4.4919 libc-2.19.so _int_free 63040 3.6941 mysqld rec_get_offsets_func(unsigned char const*, dict_index_t const*, unsigned long*, unsigned long, mem_block_info_t**) 52794 3.0937 mysqld mtr_commit(mtr_t*) |
Which points to some hot functions – quite as expected we see some functions working with undo space here. In some cases it is also helpful to look at the call graph to understand where functions are being called if it is not clear.
Now in many cases looking at oprofile report it is hard to figure out what is “wrong” without having the baseline. In this case we can look at the oprofile run for sysbench alone:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
root@ts140i:~# opreport -l | more Using /root/oprofile_data/samples/ for samples directory. warning: /no-vmlinux could not be found. warning: [vdso] (tgid:8970 range:0x7fffba5fe000-0x7fffba5fffff) could not be found. CPU: Intel Haswell microarchitecture, speed 3.201e+06 MHz (estimated) Counted CPU_CLK_UNHALTED events (Clock cycles when not halted) with a unit mask of 0x00 (No unit mask) count 100000 samples % image name symbol name 1331386 28.4544 no-vmlinux /no-vmlinux 603873 12.9060 mysqld ut_delay(unsigned long) 158428 3.3859 mysqld buf_page_get_gen(unsigned long, unsigned long, unsigned long, unsigned long, buf_block_t*, unsigned long, char const*, unsigned long, mtr_t*) 88172 1.8844 mysqld my_timer_cycles 75948 1.6232 mysqld srv_worker_thread 74350 1.5890 mysqld MYSQLparse(THD*) 68075 1.4549 mysqld mutex_spin_wait(void*, bool, char const*, unsigned long) 59321 1.2678 mysqld que_run_threads(que_thr_t*) 59152 1.2642 mysqld start_mutex_wait_v1 57495 1.2288 mysqld rw_lock_x_lock_func(rw_lock_t*, unsigned long, char const*, unsigned long, bool, bool) 53133 1.1356 mysqld mtr_commit(mtr_t*) 44404 0.9490 mysqld end_mutex_wait_v1 40226 0.8597 libpthread-2.19.so pthread_mutex_lock 38889 0.8311 mysqld log_block_calc_checksum_innodb(unsigned char const*) |
As you see this report is very different in terms of top functions.
Final thoughts: I had 2 purposes with this blog post. First, I hope it will contain some helpful information for developers so this bug can be fixed at least in MySQL 5.7. It is quite a nasty one as it can come out of nowhere if the application unexpectedly develops hot rows. Second, I hope it will show some of the methods you can use to capture and analyze data about MySQL performance.
Resources
RELATED POSTS





Glad the feature is mostly useless.