
Over the past few months I’ve written a couple of posts about dangerous debt of InnoDB Transactional History and about the fact MVCC can be the cause of severe MySQL performance issues. In this post I will cover a related topic – InnoDB Transaction Isolation Modes, their relationship with MVCC (multi-version concurrency control) and how they impact MySQL performance.
The MySQL Manual provides a decent description of transaction isolation modes supported by MySQL – I will not repeat it here but rather focus on performance implications.
SERIALIZABLE – This is the strongest isolation mode to the point it essentially defeats Multi-Versioning making all SELECTs locking causing significant overhead both in terms of lock management (setting locks is expensive) and the concurrency you can get. This mode is only used in very special circumstances among MySQL Applications.
REPEATABLE READ – This is default isolation level and generally it is quite nice and convenient for the application. It sees all the data at the time of the first read (assuming using standard non-locking reads). This however comes at high cost – InnoDB needs to maintain transaction history up to the point of transaction start, which can be very expensive. The worse-case scenario being applications with a high level of updates and hot rows – you really do not want InnoDB to deal with rows which have hundreds of thousands of versions.
In terms of performance impact, both reads and writes can be impacted. For select queries traversing multiple row versions is very expensive but so it is also for updates, especially as version control seems to cause severe contention issues in MySQL 5.6
Here is example: I ran sysbench for a completely in-memory data set and when start transaction and run full table scan query couple of times while keeping transaction open:
|
1 |
sysbench --num-threads=64 --report-interval=10 --max-time=0 --max-requests=0 --rand-type=pareto --oltp-table-size=80000000 --mysql-user=root --mysql-password= --mysql-db=sbinnodb --test=/usr/share/doc/sysbench/tests/db/update_index.lua run |
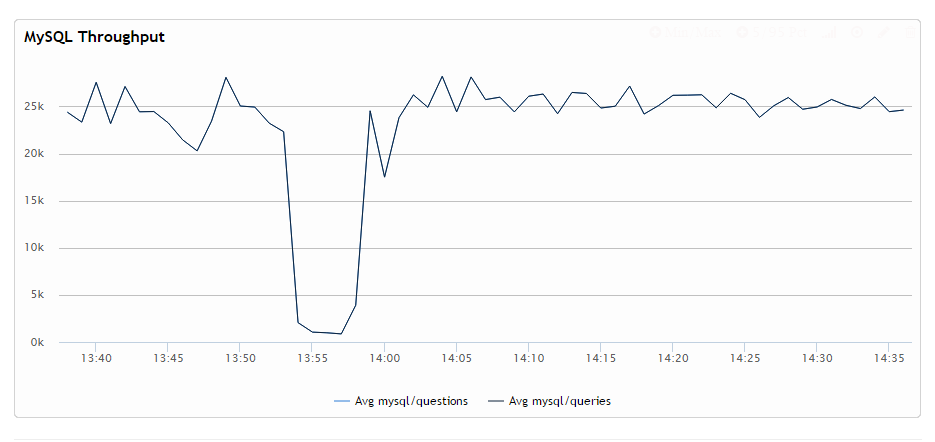
As you can see the write throughput drops drastically and stays low at all times when transaction is open, and not only when the query is running. This is perhaps the worse-case scenario I could find which happens when you have select outside of transaction followed by a long transaction in repeatable-read isolation mode. Though you can see regression in other cases, too.
Here is the set of queries I used if someone wants to repeat the test:
|
1 2 3 4 5 |
select avg(length(c)) from sbtest1; begin; select avg(length(c)) from sbtest1; select sleep(300); commit; |
Not only is Repeatable Read the default isolation level, it is also used for logical backups with InnoDB – think mydumper or mysqldump –single-transaction
These results show such backup methods not only can’t be used with large data sets due to long recovery time but also can’t be used with some high write environments due to their performance impact.
READ COMMITTED mode is similar to REPEATABLE READ with the essential difference being what versions are not kept to the start of first read in transaction, but instead to the start of the current statement. As such using this mode allows InnoDB to maintain a lot less versions, especially if you do not have very long running statements. If you have some long running selects – such as reporting queries performance impact can be still severe.
In general I think good practice is to use READ COMITTED isolation mode as default and change to REPEATABLE READ for those applications or transactions which require it.
READ UNCOMMITTED – I think this is the least understood isolation mode (not a surprise as it only has 2 lines of documentation about it) which only describe it from the logical point of view. If you’re using this isolation mode you will see all the changes done in the database as they happen, even those by transactions which have not been yet committed. One nice use case for this isolation mode is what you can “watch” as some large scale UPDATE statements are happening with dirty reads showing which rows have already been changes and which have not.
So this statement shows changes that have not been committed yet and might not ever be committed if the transaction doing them runs into some errors so – this mode should be used with extreme care. There are a number of cases though when we do not need 100% accurate data and in this case this mode becomes very handy.
So how does READ UNCOMMITTED behave from a performance point of view? In theory InnoDB could purge row versions even if they have been created after the start of the statement in READ UNCOMMITTED mode. In practice, due to a bug or some intricate implementation detail it does not do that – row versions still will be kept to the start of the statement. So if you run very long running SELECT in READ UNCOMMITTED statements you will get a large amount of row versions created, just as if you would use READ COMMITTED. No win here.
There is an important win from SELECT side – READ UNCOMMITTED isolation mode means InnoDB never needs to go and examine the older row versions – the last row version is always the correct one which can cause dramatic performance improvement especially if the undo space had spilled over to the disk so finding old row versions can cause a lot of IO.
Perhaps the best illustration I discovered with query select avg(k) from sbtest1; ran in parallel with the same update heavy workload stated above. In READ COMMITTED isolation mode it never completes – I assume because new index entries are inserted faster than they are scanned, in case of READ UNCOMMITTED isolation mode it completes in a minute or so.
Final Thoughts: Using InnoDB Isolation modes correctly can help your application to get the best possible performance. Your mileage may vary and in some cases you will see no difference; in others it will be absolutely dramatic. There also seems to be a lot of work to be done in relationship to InnoDB performance with long version history. I hope it will be tackled in the future MySQL version.





So, what’s your conclusion?
Which is better? REPEATABLE READ or READ COMMITED?
Fernando,
Quoting the article:
“In general I think good practice is to use READ COMITTED isolation mode as default and change to REPEATABLE READ for those applications or transactions which require it”
Given that quote, do you think it is a good idea for MySQL to change the default?
(Small plug: http://www.tocker.ca/2015/01/05/what-defaults-would-you-like-to-see-changed-in-mysql-5-7.html )
Morgan,
I think READ-COMMITTED is better default yet it can break some applications. Though so changing to default storage engine from MyISAM to Innodb did.
One idea could be to provide MySQL 5.6-compat configuration file which has all the application impacting changes back at their 5.6 defaults to ease migration
I like that idea. I now have MySQL 5.6-compat configuration files here:
https://github.com/morgo/mysql-compatibility-config
Morgan,
Great!
may be the deadlock bug reported here is also related to repeatable read.
http://bugs.mysql.com/bug.php?id=1866
The suggestion of “using READ COMITTED isolation mode as default” seems correct. But most of the DBA’s I talk to are not ready to change because they are not sure about the data integrity.
Postgresql is doing this out of the box and it is still ACID compliant database. Right?
The Read Committed isolation level is not safe for replication on Statement based Replication.
(may be not safe for Mixed),So I will not change the default.
Hi Peter Zaitsev, i was always wondering what will be the best method in an scenary that i dont care what is the current data (i dont want wait or lock in any case)
i just want to read what is there at the moment of adquiryng that record (some record will be old, some new)
Thank in Advanced
Luke, the problem is not about the isolation level, the problem is just that statement based replication is not safe.
Hello there.
How about in applications using XA transactions?
We are starting to look into that and MySQL documentation says that to maintain ACID we must use SERIALIZABLE.
In our limited test, having autocommit off, we cannot do a select * on a table in one session and update/insert on another session because we see locks.
Why does it need to be SERIALIZABLE ?
Thanks