
 When I speak about MySQL performance troubleshooting (or frankly any other database), I tend to speak about four primary resources which typically end up being a bottleneck and limiting system performance: CPU, Memory, Disk, and Network.
When I speak about MySQL performance troubleshooting (or frankly any other database), I tend to speak about four primary resources which typically end up being a bottleneck and limiting system performance: CPU, Memory, Disk, and Network.
It would be great if when seeing what resource is a bottleneck, we could also easily see what queries contribute the most to its usage and optimize or eliminate them. Unfortunately, it is not as easy as it may seem.
First, MySQL does not really provide very good instrumentation in those terms, and it is not easy to get information on how much CPU usage, Disk IO, or Memory a given query caused. Second, direct attribution is not even possible in a lot of cases. For example, disk writes from flushing data from the InnoDB buffer pool in the background aggregates writes from multiple queries, or disk what technically is Disk IO – temporary files, etc. may, in the end, cause major memory load due to caching.
While exact science on this matter is hard to impossible with MySQL, I think we can get close enough for it to be useful… and this is what I’ll try to do as explained in the rest of this blog post.
This is work in progress so your feedback is very much appreciated!
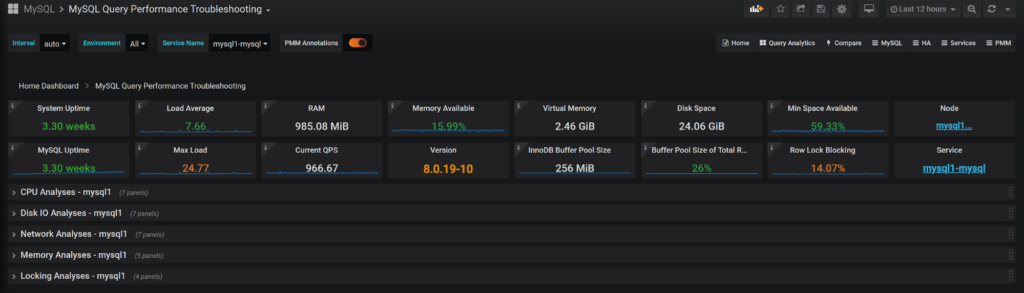
I have created the dashboard for Percona Monitoring and Management (PMM) v2, which combines the System Performance Metrics with MySQL Performance Metrics and Query Execution information to estimate the top queries for each class.
In addition to the top resources mentioned, I also add locking, which while is not really a “physical” resource but still often a cause of database performance problems.
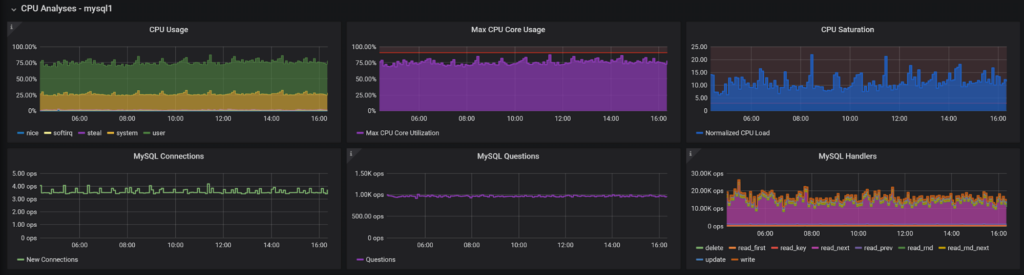
In the first part, we see the performance graphs; the first line is system metrics which show utilization and saturation (as in Brendan Gregg’s USE Method). Additionally, to overall CPU, I also included the information about max core utilization, which is rather important for MySQL where you will often have a bottleneck caused one CPU core saturated with a single thread workload rather than running out of CPU capacity for multi-core CPU.
The second row contains the data which is relevant for high-level CPU usage in MySQL: Connections, Queries, and Handlers. A large number of new connections, especially TLS, can cause significant CPU usage. A large number of queries, even trivial ones, can load up CPU, and finally, there are MySQL “Handlers” which correspond to row-level operations. When there is a lot of data being crunched, CPU usage tends to be high.
The purpose of those graphs is to easily allow you to find a problem spot when resource utilization was high. You can zoom in to it by selecting a given interval on the graph and see query activity for that particular activity.
The next section includes the mentioned CPU Intensive Queries:
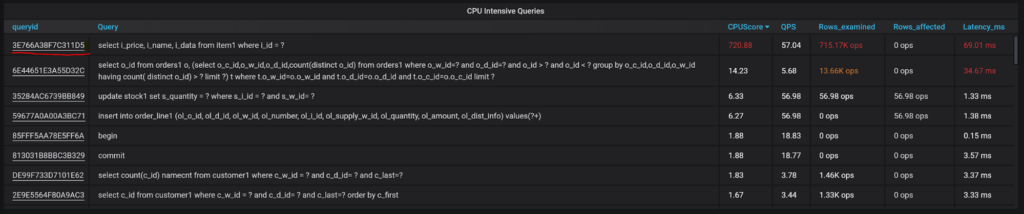
You can see queries are sorted by CPU Score – the metric computed based on the number of rows a query examines and changes (there is no direct CPU usage data easily available). We also have additional columns that typically are of interest for CPU intensive queries: number of rows this query kind crunches per second, the number of such queries, query avg latency, etc.
If you click on QueryID, Query Analytics will open with a focus on this particular query and let you see more details:
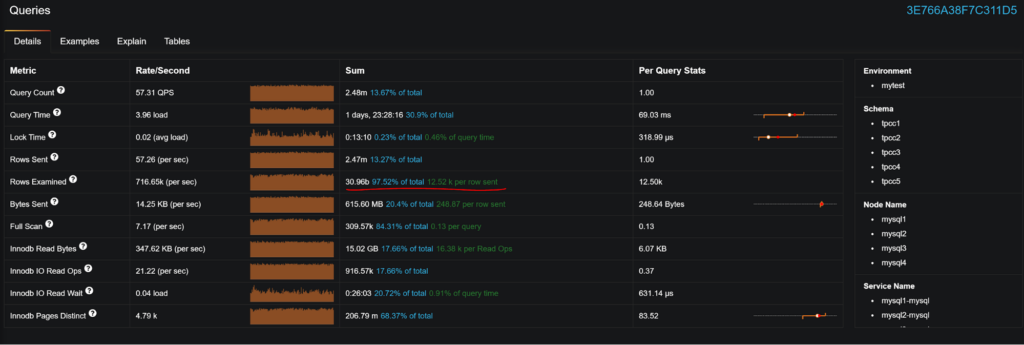
This particular query examines 12K rows for each row send; not particularly healthy. If we check out EXPLAIN, we can see it is using FULL table scan because index is missing.

For Disk IO, we’re also looking at Disk Utilization and Saturation as Disk IO errors would simply cause a database crash.
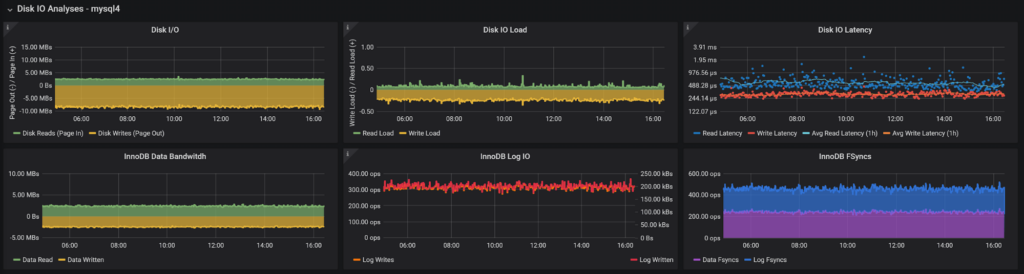
We’re looking at both system-level Disk IO Bandwidth as well as “Load” – how many IO requests, on average, are in flight, as well as Disk IO Latency, which is compared to the medium-term average. If something is wrong with storage, or if it is overloaded, latency tends to spike compared to the norm.
We’re also looking at the most important disk consumers on MySQL Level – InnoDB Data IO, Log IO, and Fsyncs. As you pick the period you’re looking to analyze, you can look at the queries scored by IOScore.
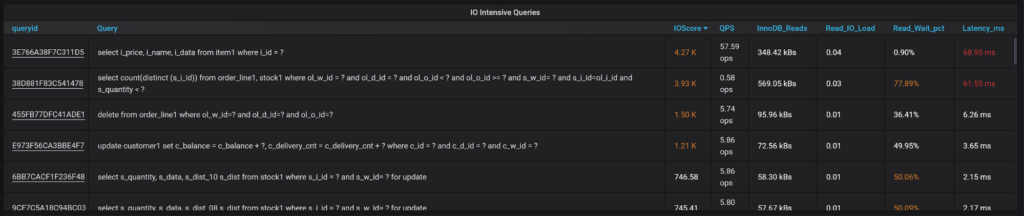
You can also see the columns most relevant for IO intensive queries – how many reads from the disk query are required, how much load is generated, as well what portion of response time was waiting for disk IO versus total query execution time.
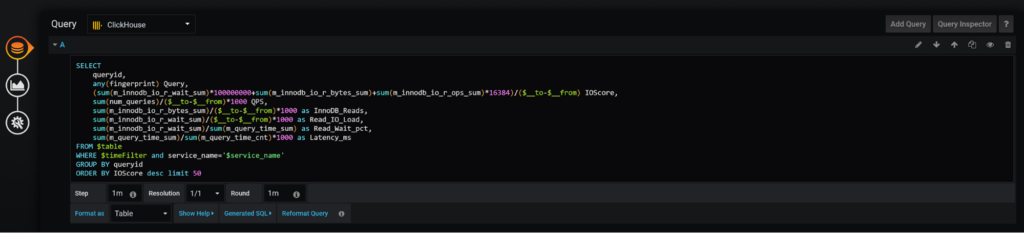
The IO Score (same as all scores) is not super scientific; I just came up with something which looked like it works reasonably well, but the great thing is you can easily customize the scoring to be more meaningful for your environment:
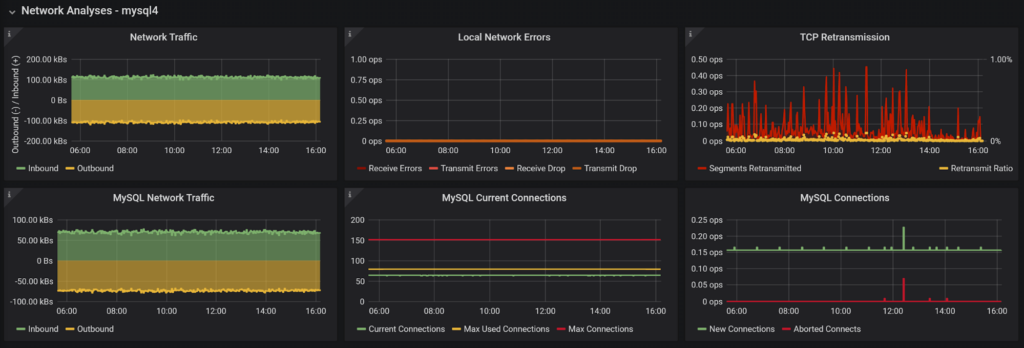
You now get the drill; we see the network usage on the system, the most common errors which can cause the problem, as well as MySQL network-level data traffic, number of concurrent connections, and new connections created (or failed connection attempts).
And queries with network-specific information:
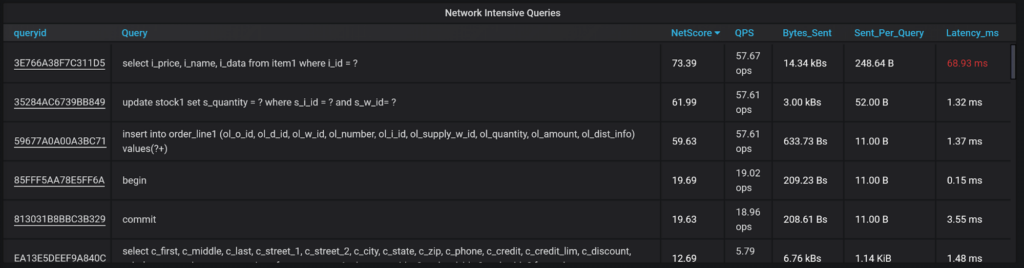
This query generates network bandwidth utilization, how large the average query result set is, etc.
At the system level, Physical Memory and Virtual Memory are resources you need to be tracking as well as swap activity, as serious swapping is a performance killer. For MySQL, I currently only show the most important memory buffers as configured; it would be much better to integrate with memory instrumentation in MySQL 5.7 Performance Schema, which I have not done yet…
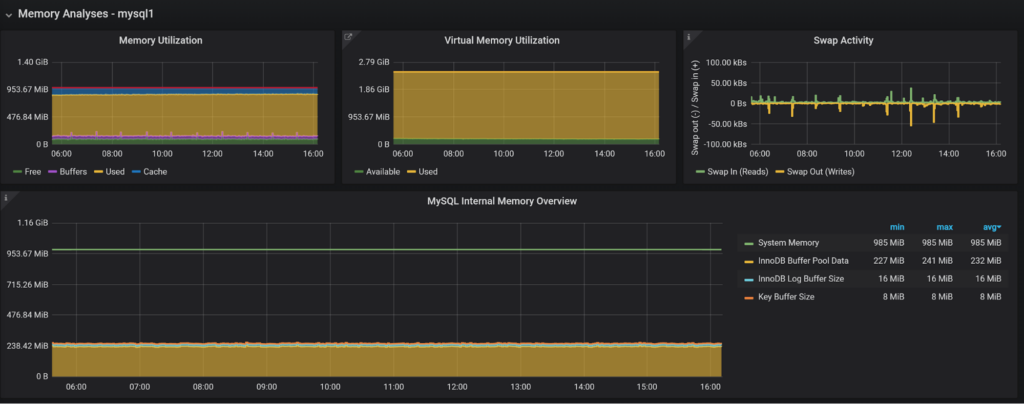
And when we can get queries showing which are heavy memory users:
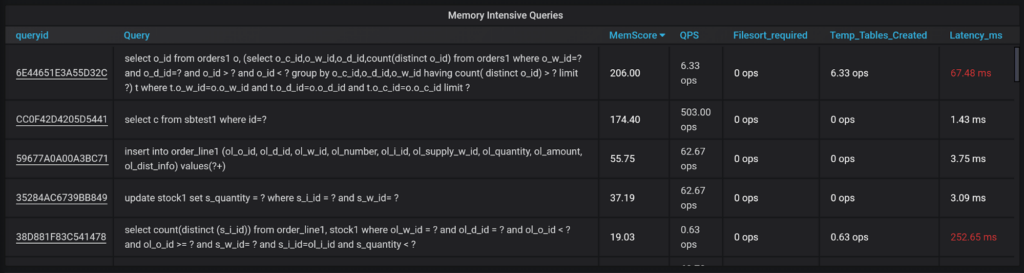
I’m using indirect measures here such as the use of temporary tables and filesort to guesstimate memory-intensive queries.
Locking is a database phenomenon so it does not show on the system level in some very particular way. It may show itself as an increased number of context switches, which is why I include the graph here. The other two graphs show us the Load (or the number of average active sessions which were blocked waiting for row-level locks), as well as what portion of the total running session it is, basically to show how much of overall response time is due to locks rather than Disk IO, CPU, etc.

And here we have the queries:
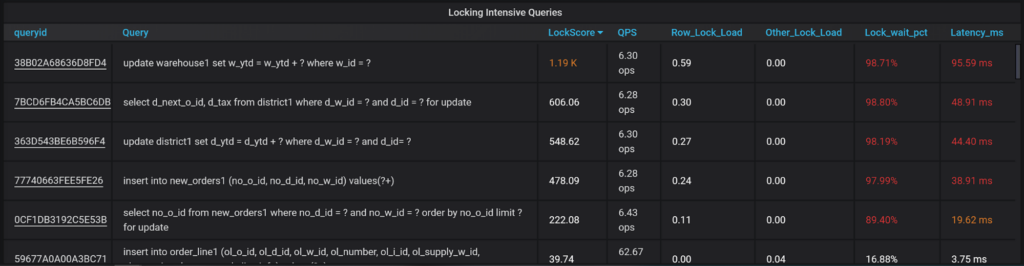
When it comes to locking in MySQL, you typically have to take care of two kinds of locks. There are InnoDB row locks, and there are other locks – Tables locks, DML locks, etc. which I show here as Row locks and other locks, highlighting how much load each of these generates.
We can also see what percent of the particular query response time was taken by waiting on lock, which can give a lot of ideas for optimization.
Note: Queries that spent a lot of time waiting on locks may be blocked by other instances of the same queries… or might be blocked by entirely different types of queries, which is much harder to catch. Still, this view will be helpful to troubleshoot many simple locking cases.
Like what you see? Install Percona Monitoring and Management v2 (if you have not done it already) and add the MySQL Query Performance Troubleshooting dashboard from the Grafana Dashboards library!
Looking for more cool extension dashboards for Percona Monitoring and Management v2? Check out my blog post on using RED Method with MySQL.
Our solution brief “Get Up and Running with Percona Server for MySQL” outlines setting up a MySQL® database on-premises using Percona Server for MySQL. It includes failover and basic business continuity components.
Resources
RELATED POSTS




