
The RED Method (Rate, Errors, Duration) is one of the more popular performance monitoring approaches. It is often applied to Monitoring Microservices though there is nothing that prevents it from being applied to databases like MySQL.
In Percona Monitoring and Management (PMM) v2 we have all the required information stored in the ClickHouse database, and with the built-in ClickHouse datasource it is a matter of creating a dashboard to visualize the data.
While I was editing the dashboard, I added a few other panels, beyond what RED Method requires, in order to show some of the cool things you can do with Grafana + ClickHouse data source and information we store about MySQL query performance.
Let’s explore this dashboard in more detail.
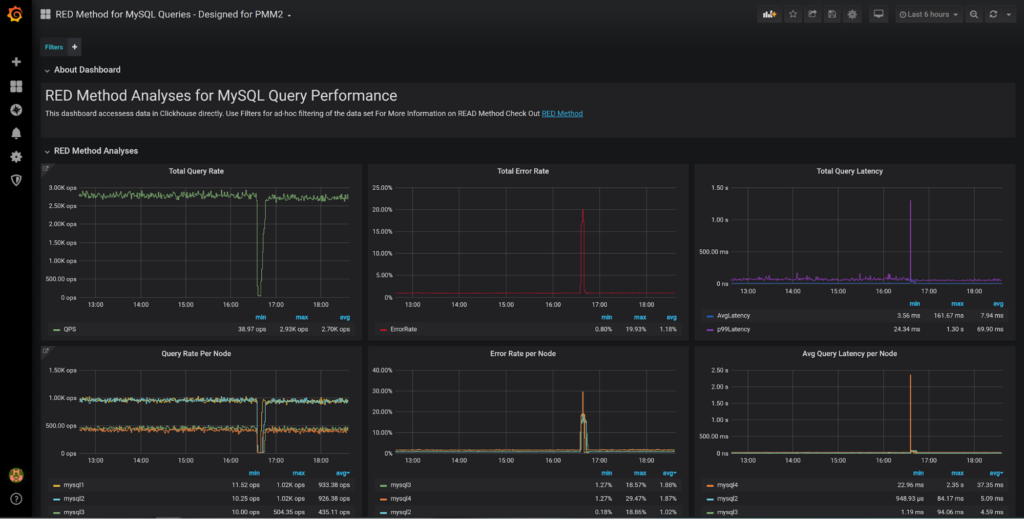
We can see the RED Method Classical panels showing Query Rate, Error Rate, as well as query latency (average and 99 percentile) for all the nodes in the system. The panel below shows the breakdown for different nodes which is very helpful to compare performance between the nodes. If one of the hosts starts to perform differently from the rest of similar hosts in the fleet, it will warrant investigation.
You do not have to look at the whole of your data through the “Filters” functionality at the top of the dashboard to apply any filters you want. For example, I can choose to only look at the queries which hit “sbtest” schema for hosts located in region “datacenter4”:
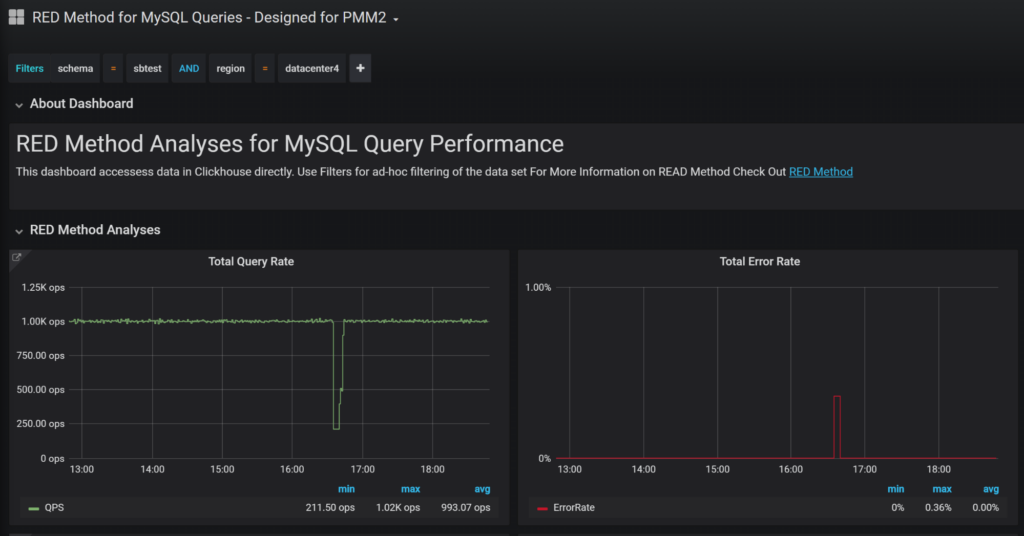
This Ad-Hoc Filtering is really powerful. You can also match queries you want to look at by regular expression, look at particular QueryID, Queries from particular Client Hosts, etc. You can check out all columns available in ClickHouse and their meaning in the blog post Advanced Query Analysis in Percona Monitoring and Management with Direct ClickHouse Access.
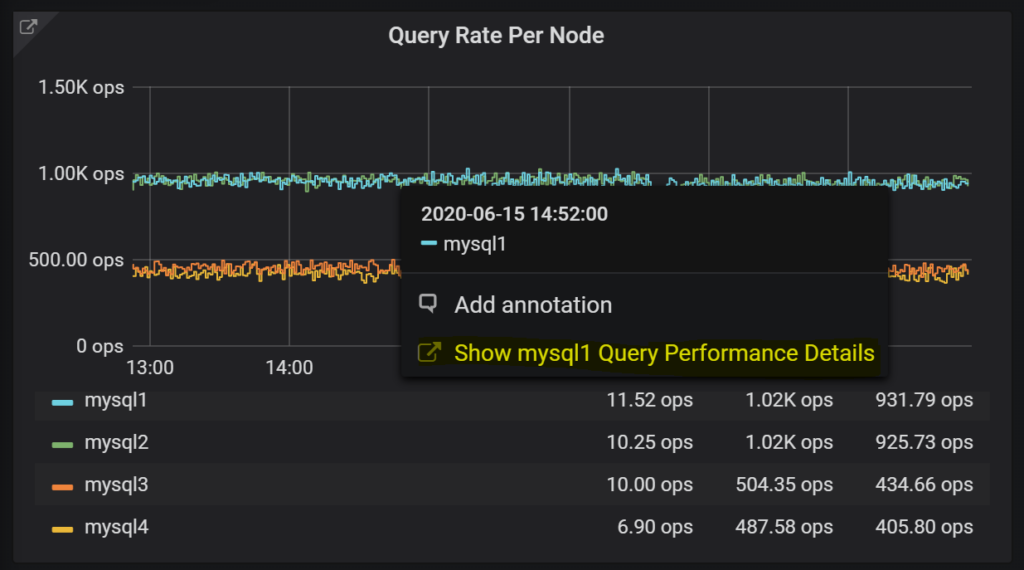
From most of the panels you can quickly jump to Query Analytics to see more details of query performance or if you notice one of the hosts having unusual performance you can use the “Data Links” functionality to see queries for this host only – click on the line on the graph and follow the highlighted link:
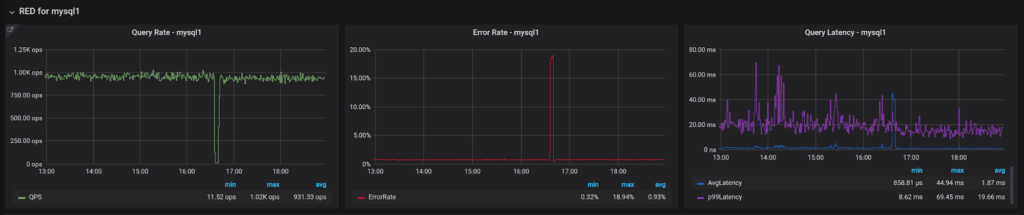
You can also see the same RED Metrics you show for the whole system for each of the systems separately. I would keep those rows collapsed by default, especially if you have many hosts under monitoring.
Now we’re done with RED Method Panels, so let’s see what additional panels this dashboard provides and how to use them.
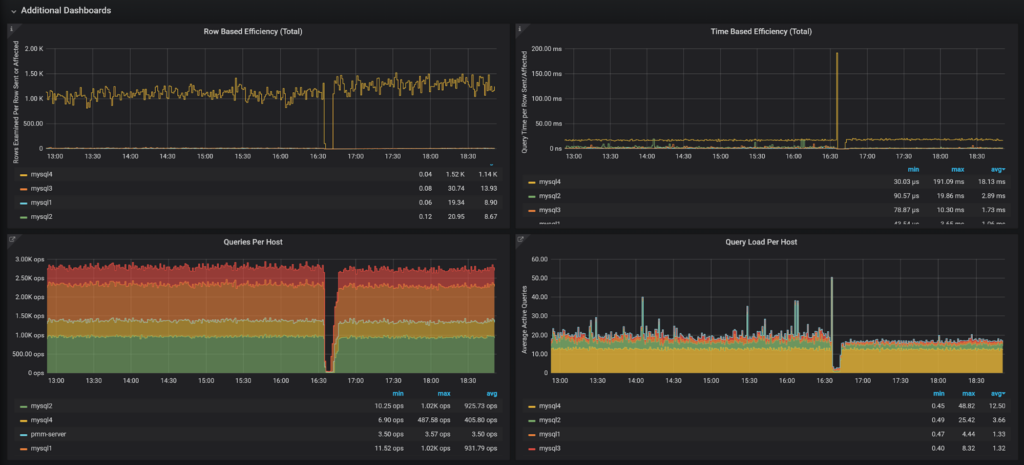
Row Based Efficiency dashboard shows how many rows are traversed for every row which is sent or changed. Values higher than 100 tend to mean you either have poor indexes or run some very complicated queries which crunch through a lot of data to send or modify a few. Both such cases are prime examples of queries to review.
Time-Based Efficiency does the same math but looks at the query execution time rather than the number of scanned rows. This allows us to float problems caused by slow disk or query contention. Generally, for a high-performance system, you should expect it to spend fractions of a millisecond to send a row to the client or modify it. Queries that send a lot of rows or modify a lot of rows will have a lower value.
Queries Per Host is pretty self-explanatory and it is very helpful to see alongside the Query Load Per Host panel which shows which hosts have the highest amount of queries active at the same time. We can see here while MySQL4 does not have the highest query rate in the mix, it has the highest load or highest number of average active queries.
As I was thinking about what other metrics might be helpful, I also added these additional panels:
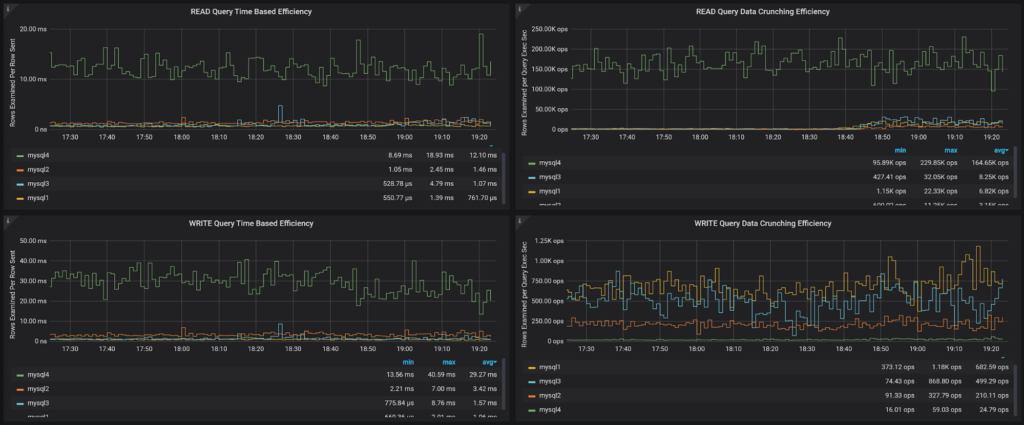
These panels break down the Query Processing efficiency to READ queries (those which send rows) and WRITE queries (which has row_affected).
QueryTime Based Efficiency is the same as the panel described before, just with a focus on particular kinds of queries.
Data Crunching Efficiency is a bit different spin on the same data; it looks at how many rows are examined by those queries vs query execution time. This, on one extent, shows system processing power; system with many cores having all data in memory may be able to crunch millions of rows per second and do a lot of work. But it does not mean all this work has value. In fact, systems that crunch a lot of data quickly are often doing many full table scans.
Finally, there are few Query Lists on the same page.
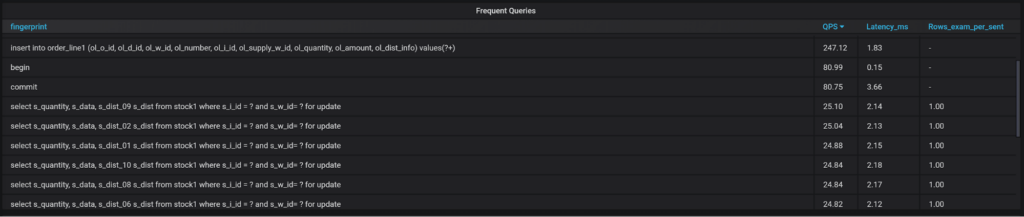
Frequent queries, queries which are the slowest on average, queries which cause the most load, and queries which terminated with an error or warning. You can get these in Query Analytics as well, but I wanted to show those as examples.
Interested? You can install the Dashboard to your Percona Monitoring and Management (PMM) v2 from Grafana.com. Check it out, and let us know what you think!
Resources
RELATED POSTS





its spelled analysis not analyses!
Refering to the email about this post.