
 In this post, the third in a series explaining the internals of InnoDB flushing, we’ll focus on tuning. (Others in the series can be seen at InnoDB Flushing in Action for Percona Server for MySQL and Give Love to Your SSDs – Reduce innodb_io_capacity_max!)
In this post, the third in a series explaining the internals of InnoDB flushing, we’ll focus on tuning. (Others in the series can be seen at InnoDB Flushing in Action for Percona Server for MySQL and Give Love to Your SSDs – Reduce innodb_io_capacity_max!)
Understanding the tuning process is very important since we don’t want to make things worse or burn our SSDs. We proceed with one section per variable or closely-related variables. The variables are also grouped in sections based on the version of MySQL or Percona Server for MySQL where they are valid. A given variable may be present more than once if its meaning changes between versions. There may be other variables affecting the way InnoDB handles a write-intensive workload. Hopefully, the most important ones are covered.
The default value for this variable is 200. If you read our previous post, you know innodb_io_capacity is the number of iops used for idle flushing and tasks like applying the change buffer operations in the background. The adaptive flushing is independent of innodb_io_capacity. There are very few reasons to increase innodb_io_capacity above the default value:
We have a hard time finding any reasons to increase the idle flushing rate. Also, the dirty pages percentage flushing shouldn’t be used (see below). That leaves the changer buffer lag. If you constantly have a large number of entries in the change buffer when you do “show engine innodb statusG”, like here:
|
1 2 3 4 5 6 7 8 |
------------------------------------- INSERT BUFFER AND ADAPTIVE HASH INDEX ------------------------------------- Ibuf: size 1229, free list len 263690, seg size 263692, 40050265 merges merged operations: insert 98911787, delete mark 40026593, delete 4624943 discarded operations: insert 11, delete mark 0, delete 0 |
where there are 1229 unapplied changes, you could consider raising innodb_io_capacity.
The default value for innodb_io_capacity_max is 2000 when innodb_io_capacity is also at its default value. This variable controls how many pages per second InnoDB is allowed to flush. This roughly matches write IOPS generated by InnoDB. Your hardware should be able to perform that many page flushes per second. If you see messages like:
|
1 |
[Note] InnoDB: page_cleaner: 1000ms intended loop took 4460ms. The settings might not be optimal. (flushed=140, during the time.) |
In the MySQL error log, then the hardware is not able to keep up, so you should lower the innodb_io_capacity_max value. The ideal value should allow the checkpoint age to be as high as possible while staying under 75% of the max checkpoint age. The higher the checkpoint age, the less writes the database will need to perform. At the same time, if the checkpoint age is above 75%, you’ll risk stalls. A trade-off is required, write performance vs risk of short stalls. Choose where you stand according to the performance pain points you are facing and the risk of short stalls. If you have deployed Percona Monitoring and Management (PMM), the “InnoDB Checkpoint Age” in the “MySQL InnoDB Details” dashboard is very useful. Here is a simple example produced with the help of sysbench:
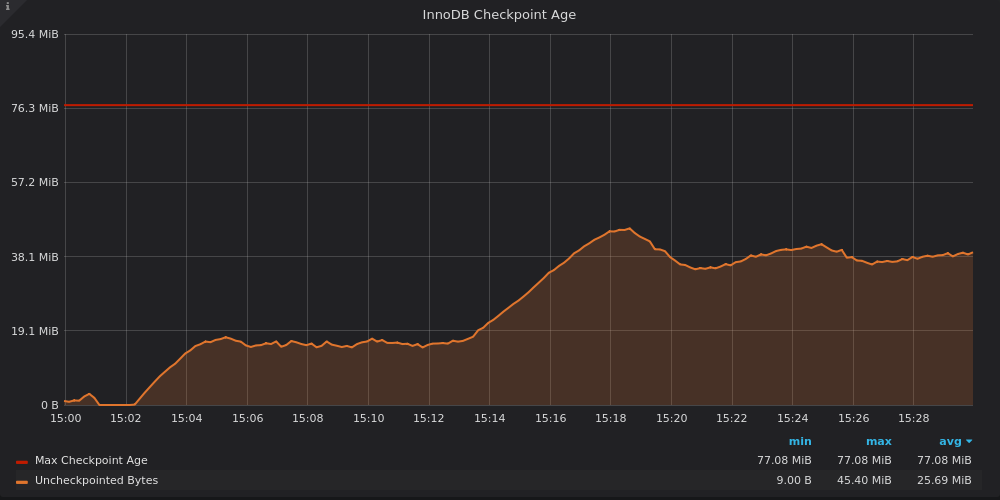
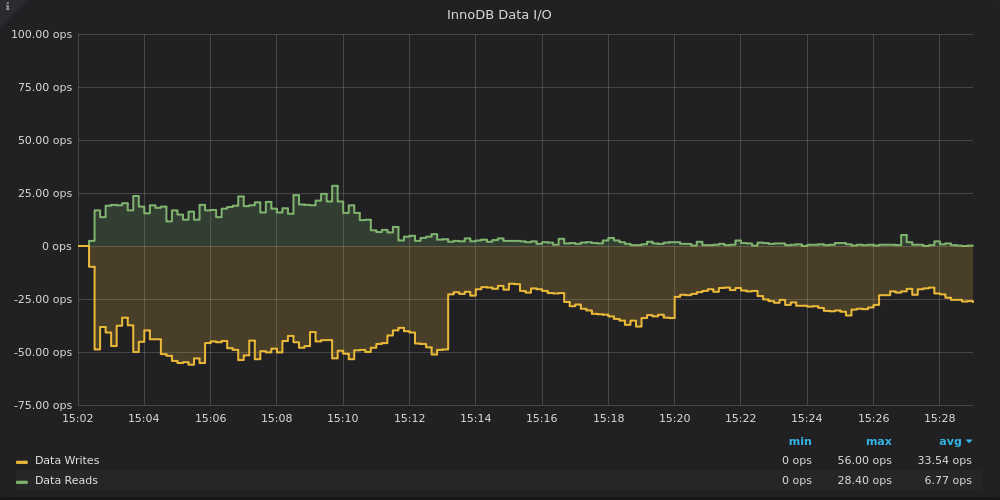
The load starts at 15:02 and the checkpoint age quickly levels around 20%. Then, at 15:13, innodb_io_capacity_max is lowered, the checkpoint age raises to around 50%. This raise caused the flushing rate to fall by about half, as it can be seen in another PMM graph, “InnoDB Data I/O”
Percona Server for MySQL also exposes all the relevant variables:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
mysql> show global status like 'innodb_ch%'; +---------------------------+------------+ | Variable_name | Value | +---------------------------+------------+ | Innodb_checkpoint_age | 400343763 | | Innodb_checkpoint_max_age | 1738750649 | +---------------------------+------------+ 2 rows in set (0.00 sec) mysql> show global variables like 'innodb_adaptive_fl%'; +------------------------------+-------+ | Variable_name | Value | +------------------------------+-------+ | innodb_adaptive_flushing | ON | | innodb_adaptive_flushing_lwm | 10 | +------------------------------+-------+ 2 rows in set (0.00 sec) |
Using the above example, the checkpoint age is roughly 23% of the max age, well above the 10% defined in innodb_adaptive_flushing_lwm. If the checkpoint age value is typical of when the database is under load and it never raises to much higher values, innodb_io_capacity_max could be lowered a bit. On the contrary, if the checkpoint age is often close or even above 75%, the value innodb_io_capacity_max is too small.
These variables control the old MySQL 5.0 era flushing as a function of the percentage of dirty pages in the buffer pool. It should be disabled by setting innodb_max_dirty_pages_pct_lwm to 0. It is the default value in 5.7 but strangely, not in 8.0.
innodb_page_cleaners sets a number of threads dedicated to scan the buffer pool instances for dirty pages and flush them. Furthermore, you cannot have more cleaner threads than buffer pool instances. The default value for this variable is 4.
With 4 cleaner threads, InnoDB is able to flush at a very high rate. Actually, unless you are using Percona Server for MySQL with the parallel doublewrite buffers feature, very likely the doublewrite buffer will bottleneck before the cleaner threads.
innodb_purge_threads defines the number of threads dedicated to purge operations. The purge operations remove deleted rows and clear undo entries from the history list. These threads also handle the truncation of the undo space on disk. The default number of purge threads is 4.
It is difficult to imagine a workload able to saturate 4 purge threads, the default is generous. Most of the work done by the purge threads is in memory. Unless you have a very large buffer pool and a high write load, the default value of 4 is sufficient. If you see high values for the history length in the “show engine innodb status” without any long-running transaction, you can consider increasing the number of purge threads.
Surprisingly enough, on Linux with asynchronous IO, these threads have little relevance. For example, one of our customers operates a server with 16 read io threads and 16 write io threads. With an uptime of about 35 days, the mysqld process consumed 104 hours of CPU, read 281 TB, and wrote 48 TB to disk. The dataset is composed essentially of compressed InnoDB tables. You could think that for such a server the IO threads would be busy right? Let’s see:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
root@prod:~# ps -To pid,tid,stime,time -p $(pidof mysqld) PID TID STIME TIME 72734 72734 Mar07 00:23:07 72734 72752 Mar07 00:00:00 -> ibuf (unused) 72734 77733 Mar07 00:01:16 72734 77734 Mar07 00:01:51 72734 77735 Mar07 00:05:46 -> read_io 72734 77736 Mar07 00:06:04 -> read_io 72734 77737 Mar07 00:06:06 -> read_io … 11 lines removed 72734 77749 Mar07 00:06:04 -> read_io 72734 77750 Mar07 00:06:04 -> read_io 72734 77751 Mar07 00:35:36 -> write_io 72734 77752 Mar07 00:34:02 -> write_io 72734 77753 Mar07 00:35:14 -> write_io … 11 lines removed 72734 77766 Mar07 00:35:18 -> write_io 72734 77767 Mar07 00:34:15 -> write_io |
We added annotations to help identify the IO thread and a number of lines were removed. The read IO threads have an average CPU time of 6 minutes while the write IO threads have a slightly higher one, at 35 minutes. Those are very small numbers, clearly, 16 is too many in both cases. With the default values of 4, the CPU time would be around 25 minutes for the read IO threads and around 2 hours for the write IO threads. Over the uptime of 34 days, these times represent way less than 1% of the uptime.
innodb_lru_scan_depth is a very poorly named variable. A better name would be innodb_free_page_target_per_buffer_pool. It is a number of pages InnoDB tries to keep free in each buffer pool instance to speed up read and page creation operations. The default value of the variable is 1024.
The danger with this variable is that with high value and many buffer pools instances, you may end up wasting a lot of memory. With 64 buffer pool instances, the default value represents 1GB of memory. The best way to set this variable is to look at the output of “show engine innodb statusG” with a pager grepping for “Free buffers”. Here’s an example.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
mysql> pager grep 'Free buffers' PAGER set to 'grep 'Free buffers'' mysql> show engine innodb statusG Free buffers 8187 Free buffers 1024 Free buffers 1023 Free buffers 1022 Free buffers 1020 Free buffers 1024 Free buffers 1025 Free buffers 1025 Free buffers 1024 1 row in set (0.00 sec) |
The first line is the total for all the buffer pools. As we can see, InnoDB has no difficulty maintaining around 1024 free pages per buffer pool instance. The lowest observed value across all the instances is 1020. As a rule of thumb, you could use the current variable value (here 1024), minus the smallest observed value over a decent number of samples, and then multiply the result by 4. If 1020 was the lowest value, we would have (1024-1020)*4 ~ 16. The smallest allowed value for the variable is 128. We calculated 16, a value smaller than 128, so 128 should be used.
innodb_flush_sync allows InnoDB flushing to ignore the innodb_io_capacity_max value when the checkpoint age is above 94% of its maximal value. Normally this is correct, hence the default value of ‘ON’. The only exception would be a case where the read SLAs are very strict. Allowing InnoDB to use beyond innodb_io_capacity_max IOPs for flushing would compete with the read load and read SLAs would be missed.
The variables innodb_log_file_size and innodb_log_files_in_group determine the size of the redo log ring buffer. This topic was discussed at length in our previous post. Essentially, the redo log is a journal of recent changes. The largest allowed total size is 512GB minus one byte. A larger redo log ring buffer allows for pages to stay dirty for a longer period of time in the buffer pool. If during that time, pages receive more updates, the write load is essentially deflated. Lowering the write load is good for performance, especially if the database is close to IO-bound. A very large redo log ring buffer causes the recovery time after a crash to take more time but this is much less of an issue these days.
As a rule of thumb, the time to fully use the redo log should be around one hour. Watch the evolution of the innodb_os_log_written status variable over time and adjust accordingly. Keep in mind that one hour is a general rule, your workload may need to be different. This is a very easy tunable and it should be among the first knobs you turn.
innodb_adaptive_flushing_lwm defines the low watermark to activate the adaptive flushing. The low watermark value is expressed as a percentage of the checkpoint age over the maximal checkpoint age. When the ratio is under the value defined by the variable, the adaptive flushing is disabled. The default value is 10 and the max allowed value is 70.
The main benefits of a higher watermark are similar to the ones of using a larger value for innodb_log_file_size but it puts the database closer to the edge of max checkpoint age. With a high low watermark value, the write performance will be better on average but there could be short stalls. For a production server, increasing innodb_log_file_size is preferred over increasing innodb_adaptive_flushing_lwm. However, temporarily, it can be useful to raise the value dynamically to speed up a logical dump restore or to allow a slave to catch up with its master.
This variable controls the reactivity of the adaptive flushing algorithm, it damps its reaction. It affects the calculation of the average rate of consumption of the redo log. By default, InnoDB calculates the average every 30 seconds and the resulting value is further averaged with the previous one. That means if there is a sudden transaction surge, the adaptive flushing algorithm will react slowly, only the checkpoint age-related part will react immediately. It is difficult to identify a valid use case where someone would need to modify this variable.
Prior to MySQL 8.0.19, when InnoDB needed to flush furiously at the sync point, it proceeded in large batches of pages. The issue with this approach is that the flushing order may not be optimal, too many pages could come from the same buffer pool instances.
Since MySQL 8.0.19, the furious flushing is done in chunks of innodb_io_capacity size. There is no wait time between the chunks so there is no relationship with the IO capacity. This way helps better balance the flushing order and lowers the potential stall time.
With MySQL 8.0.19, the idle flushing rate is no longer directly set by innodb_io_capacity, it is multiplied by the percentage represented by innodb_idle_flush_pct. InnoDB uses the remaining IO capacity for the insert buffer thread. When a database becomes idle, meaning the LSN value does not move, InnoDB normally flushes the dirty pages first and then applies the pending secondary indexes changes stored in the change buffer. If this is not the behavior you want, lower the value to give some IO to the change buffer.
Percona Server for MySQL has a different default adaptive flushing algorithm, high_checkpoint, which essentially allows more dirty pages. This behavior is controlled by the variable innodb_cleaner_lsn_age_factor. You can restore the default MySQL algorithm by setting the variable to legacy. Since you should aim to have as many dirty pages as possible without running into flush storms and stalls, the high_checkpoint algorithm will help you. If you have extreme bursts of checkpoint age, maybe the legacy algorithm would fare better. For more information on this topic, see our previous post.
This variable controls the behavior of InnoDB when it struggles at finding free pages in a buffer pool instance. It has two possible values: legacy and backoff. It is only meaningful if you often have “Free buffers" close to 0 in “show engine innodb statusG”. In such a case, the LRU manager thread may hammer the free list mutex and cause contention with other threads. When set to backoff, the thread will sleep for some time after a failure to find free pages to lower the contention. The default is backoff and normally it should be fine in most cases.
There are other variables impacting InnoDB writes, but these are among the most important ones. As a general rule, don’t over-tune your database server and try to change one setting at a time.
This is our understanding of the InnoDB variables affecting the flushing. The findings are backed by the pretty unique exposure we have at Percona to a wide variety of use cases. We also spend many hours reading the code to understand the inner moving parts of InnoDB. As usual, we are open to comments but if possible, try to back any argument against our views with either a reference to the code or a reproducible use case.





I was confused after reading the official docs for these parameters. I remain confused after reading this. What started my confusion was the statement that innodb_io_capacity doesn’t need to be changed. I assume this implies that innodb_io_capacity_max should still be set and I would be less confused had you added that.
Regardless, InnoDB has way too many tuning options in this space. It is starting to make MyRocks & RocksDB look easy to tune.
Exactly, innodb_io_capacity_max is more important than innodb_io_capacity. I recently worked with MyRocks, may I suggest your ease of tuning goes with your familiarity with then engine. It ended up working great but let’s say, I had an opportunity to experiment with column families… There are still a few things I don’t understand enough with MyRocks. I may blog about that in the near future.
The problem with RocksDB is too many options that can be set. The problem isn’t too many options that should be set. It would be great if there were simple way to partition the option name space into “can set” vs “should set” to reduce confusion. An old post from me on this is http://smalldatum.blogspot.com/2018/09/5-things-to-set-when-configuring.html
From the above it isn’t clear to me whether most of these options are “can set” or “should set”. Perhaps that is content for the next blog post by you. Which options should I set?
Hi Yves, Francisco,
You wrote that with 4 cleaner threads, InnoDB is able to flush at a very high rate but without parallel doublewrite buffers , the doublewrite buffer will bottleneck before the cleaner threads.
Have you tested with MySQL 8.0.20 (https://dev.mysql.com/doc/refman/8.0/en/innodb-parameters.html#sysvar_innodb_doublewrite_files).
Now if you think that the default of 2 should be 4, like the numbers of innodb_page_cleaners, please let us know 😉
Cheers,
Hi Fred, 8.0.20 was released after this post, at first glance, the new doublewrite buffer seems to be rather similar to the Percona server parallel doublewrite buffer. I’ll check in more detail when I have a minute.