
 The innodb_io_capacity and innodb_io_capacity_max are often misunderstood InnoDB parameters. As consultants, we see, at least every month, people setting this variable based on the top IO write specifications of their storage. Is this a correct choice? Is it an optimal value for performance? What about the SSD/Flash wear leveling?
The innodb_io_capacity and innodb_io_capacity_max are often misunderstood InnoDB parameters. As consultants, we see, at least every month, people setting this variable based on the top IO write specifications of their storage. Is this a correct choice? Is it an optimal value for performance? What about the SSD/Flash wear leveling?
Let’s begin with what the manual has to say about innodb_io_capacity:
“The innodb_io_capacity variable defines the number of I/O operations per second (IOPS) available to InnoDB background tasks, such as flushing pages from the buffer pool and merging data from the change buffer.“
What does this mean exactly? Like most database engines, when you update a piece of data inside InnoDB, the update is made in memory and only a short description of the modification is written to the redo log files before the command actually returns. The affected page (or pages) in the buffer pool are marked as dirty. As you write more data, the number of dirty pages will rise, and at some point, they need to be written to disk. This process happens in the background and is called flushing. The innodb_io_capacity defines the rate at which InnoDB will flush pages. To better illustrate, let’s consider the following graph:
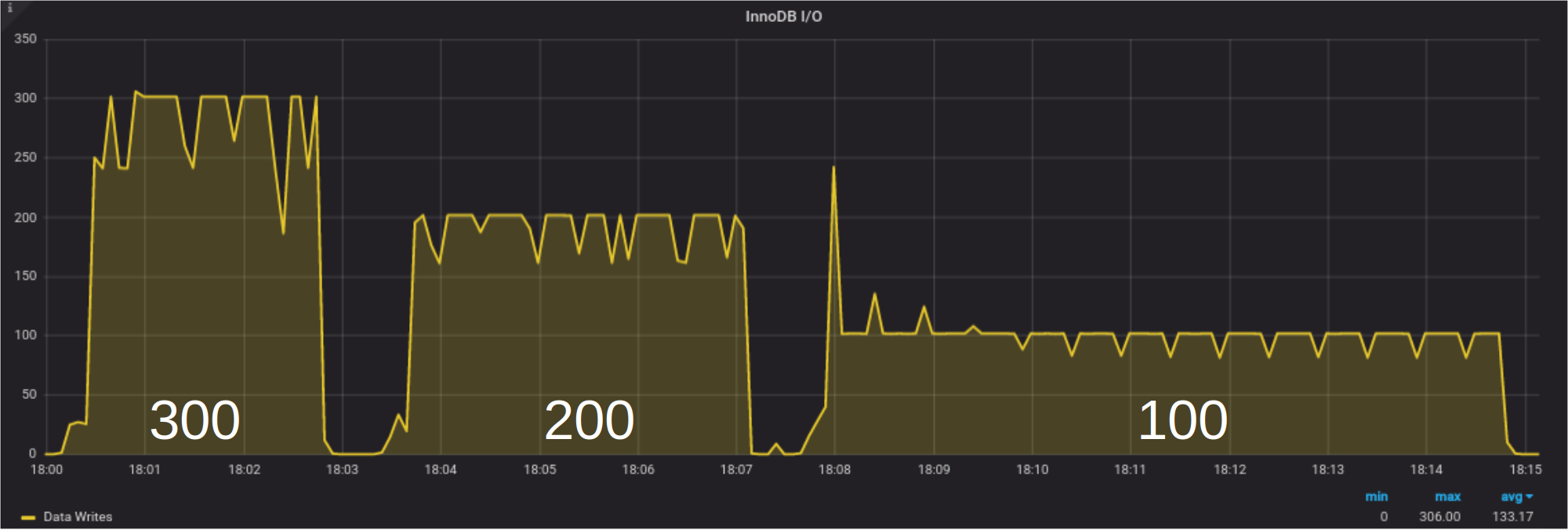
We used the tool sysbench for a few seconds to generate about 45000 dirty pages in the buffer pool and then we let the flushing process run for three values of innodb_io_capacity: 300, 200, and 100. The configuration was adjusted to avoid other sources of writes. As we can see, the number of pages written per second matches the innodb_io_capacity value. This type of flushing is called the idle flushing. The idle flushing happens only when InnoDB is not processing writes. It is the only time the flushing is dominated by innodb_io_capacity. The variable innodb_io_capacity is also used for the adaptive flushing and by the change buffer thread for the background merges of secondary index updates. On a busy server, when the adaptive flushing algorithm is active, the innodb_io_capacity_max variable is much more important. A blog post devoted to the internals of the InnoDB adaptive flushing algorithm is in preparation.
What are the pros and cons of having a large number of dirty pages? Are there good reasons to flush them as fast as possible?
If we start with the cons, a large number of dirty pages will increase the MySQL shutdown time since the database will have to flush all those pages before stopping. With some planning, the long shutdown time issue can easily be mitigated. Another negative impact of a large number of dirty pages is the recovery time after a crash, but that is quite exceptional.
If a page stays dirty for a while in the buffer pool, it has the opportunity to receive an additional write before it is flushed to disk. The end result is a deflation of the write load. There are schema and query patterns that are more susceptible to a write load reduction. For example, if you are inserting collected metrics in a table with the following schema:
|
1 2 3 4 5 6 7 8 |
CREATE TABLE `Metrics` ( `deviceId` int(10) unsigned NOT NULL, `metricId` smallint(5) unsigned NOT NULL, `Value` float NOT NULL, `TS` int(10) unsigned NOT NULL, PRIMARY KEY (`deviceId`,`metricId`,`TS`), KEY `idx_ts` (`TS`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1 |
If there are 20k devices each with 8 metrics, you know there are 160k hot pages. Ideally, these pages shouldn’t be written to disk until they are full, actually half-full since they are part of a mid-inserted b-tree.
Another example is a users table where the last activity time is logged. A typical schema could be:
|
1 2 3 4 5 6 7 |
CREATE TABLE `users` ( `user_id` int(10) unsigned NOT NULL AUTO_INCREMENT, `last_login` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP, `last_activity` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP, `user_pref` json NOT NULL, PRIMARY KEY (`user_id`) ) ENGINE=InnoDB AUTO_INCREMENT=6521901 DEFAULT CHARSET=latin1 |
Often, only a small subset of the users is active at a given time so the same pages will be updated multiple times as the users navigate in the application. To illustrate this behavior, we did a little experiment using the above schema and actively updating a random subset of only 30k rows out of about 6.5M. A more realistic example would require a lab more capable than this old laptop. During the experiment the following settings were used:
|
1 2 3 |
innodb_adaptive_flushing_lwm = 0 innodb_io_capacity = 100 Innodb_flush_neighbors = off |
For each run, we varied innodb_io_capacity_max and calculated the ratio of updates over page flushed over a duration of 30 minutes. We never reached a furious flushing situation.
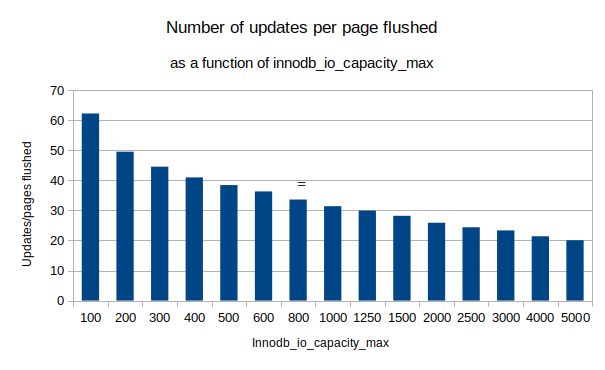
As we can see, when we limit innodb_io_capacity_max to 100, there are about 62 updates per page flushed, while at the other end, with the IO capacity set to 5000, there were only about 20 updates per page flushed. This means, just by tuning innodb_io_capacity_max, we modified the overall write load by a factor of three.
When an InnoDB page is in the process of being flushed to disk, its access is limited and a query needing its content may have to wait until the IO operation completes. An excessive write load also puts pressure on storage and CPU resources. In the above experiment where we varied innodb_io_capacity_max, the update rate went from above 6000 trx/s with innodb_io_capacity_max at 100 to less than 5400 trx/s with innodb_io_capacity_max at 4000. Simply overshooting the values of innodb_io_capacity and innodb_io_capacity_max is not optimal for performance.
But why is the amount of writes so important and what has it to do with flash devices?
Flash devices are good, we know that, but this performance improvement comes with a downside: endurance. Normally SSDs are capable of doing much less write operations in each sector than regular spinning drives. It all boils down to the way bits are stored using NAND gates. The bits are represented by a voltage level across a set of gates and the slightest deterioration of a gate, as it is cycled between values, affects these voltage levels. Over time, a memory element is no longer reaching the proper voltage. Cheaper flash devices store more bits per set of gates, per storage cells, so they are more affected by the deterioration of voltage levels. SSDs also have more or less spare storage cells to fix broken ones.
Let’s look at the endurance of some SSDs. We chose a few models from the Intel web site mostly because estimate prices are provided.
| Model | Type | Size | Endurance (cycle) | Price |
| Optane DC P4800X | Enterprise | 1.5 TB | 112,000 | $ 4,975 |
| DC P4610 | Enterprise | 1.6 TB | 7,840 | $ 467 |
| 545S | Consumer | 512 GB | 576 | $ 120 |
The endurance is expressed in full write cycles, the number of times the device can be completely overwritten. The endurance is one of the main variables affecting the price. The enterprise-grade SSDs have a higher endurance than the consumer-grade ones. The Optane series is at the high end of the enterprise offering.
Devices like the DC P4610 are fairly common. The specs of the drive in the above table show a total write endurance of 12.25 PB (7,840 full device writes) and the ability to perform 640k read IOPS and about 200k write IOPS. If we assume a server life of five years, this means the average write bandwidth has to be less than:
12.25 PB * 1024^3 MB/PB / (5y * 365 d/y * 24 h/d * 3600 s/h) ~ 83 MB/sec.
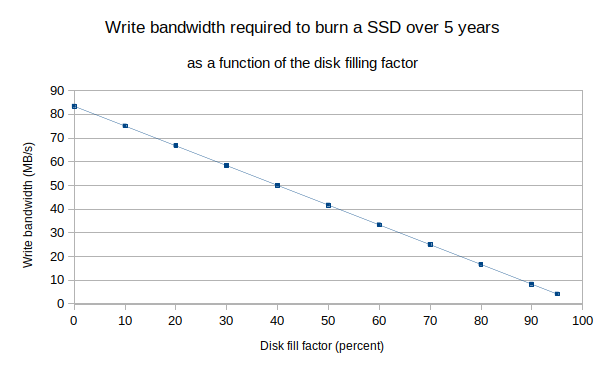
So, in theory, you could write at 83MB/sec for five years. This is very high but… it implies an empty device. If there is a static dataset, like old data nobody wants to prune, filling 75% of the SSD, the situation is very different. Now, only 25% of the drive is getting all the writes and those storage cells are cycled much faster. We are down to an average of about 21 MB/sec over five years. That is still a decent bandwidth but it falls into more realistic use cases.
The following figure shows the average write bandwidth needed to reach the SSD endurance specification as a function of the filling factor. With SSDs, if the disks are rather full, it is a good idea to regularly, maybe yearly or every 6 months, wipe out the data and reload it. This process reshuffles the data and helps spread the strain to all the storage cells. If you are using Percona XtraDB Cluster, that amounts at triggering a full SST after deleting the dataset and maybe run fstrim if the filesystem is not mounted with the discard option.
Now, in terms of InnoDB write load, because of things like the doublewrite buffer, the redo log, the undo log, and the binary log, when InnoDB writes a 16KB page to disk, the actual amount of data written is higher, between 32KB and 48KB. This estimate is highly dependent on the schema and workload but as a rough estimate, we can estimate 36KB written per page flushed.
We often see very high values for both innodb_io_capacity and innodb_io_capacity_max, as people look at the specs of their SSDs and set a very high number. Values of many tens of thousands are common; we have even seen more than 100k a few times. Such high values lead to an aggressive InnoDB flushing – way more than needed. There are very few dirty pages in the buffer pool and performance is degraded. The InnoDB checkpoint age value is likely very close to innodb_adaptive_flushing_lwm times the max checkpoint age value.
On a moderately busy server, sustained InnoDB flushing rates of 2000 pages per second can easily be reached. Given our estimate of 36KB written per page flushed, such a flushing rate produces a write bandwidth of 70 MB/s. Looking at the previous figure, if the SSD used has similar specs and is more than 75% filled, it will not last 5 years; rather, likely less than one and a half years.
This post is trying to shed some light on a common problem we are observing much more frequently than we would like. Actually, we are surprised to see a lot of people recommending increasing the IO capacity settings practically out of the box instead of paying attention to some other settings.
So, be nice, keep io_capacity settings as low as you need them – your SSDs will thank you! 🙂





Hi Yves and Francisco, great post.
The very first graph in the post is interesting. With your configuration flushed pages are constant, with down-spikes. They are:
* Irregular with innodb_io_capacity=300
* The height becomes regular with 200
* The interval between spikes also becomes regular with 300
Do you know the reason?
Hi Federico, either it is because my PMM setup has non-standard scrape intervals or this is caused by the innodb_flushing_avg_loops (30s)
Before I read this post, I always set the innodb_io_capacity=10000 and innodb_io_capacity_max=20000 when the disk is ssd。 Now ,what can I do to mesure the value of innodb_io_capacity and the value of innodb_io_capacity_max?
weike.meng yeap, that’s exactly the reason that motivated this (and upcoming) post. There are more posts coming with extra details on flushing and how to calculate things properly. For now, I’d strongly recommend to decrease those values and start from defaults (which actually works pretty pretty well in most of cases)
Hi Francisco Bordenave,thanks for your sharing.Look forward to your new posts!
The MySQL I/O tuning docs mention keeping this (innodb_io_capacity) low depending on whether throughput is bottlenecked by flushing https://dev.mysql.com/doc/refman/5.7/en/optimizing-innodb-diskio.html .
This is a great post because the docs don’t make reference to innodb_io_capacity_max, or tying the increased (unnecessary) iops to reduced SSD lifecycle.
Thanks Derek, indeed, a lot of code reading (credits on Yves here) was done to understand better some internals. In any case increasing io_cap_max with no reason may actually cause more problems than solutions, even performance problems.