
 As a Solutions Engineer at Percona, one of my responsibilities is to support our customers as they investigate new and emerging technologies. This affords me the opportunity to speak to many current and new customers who partner with Percona.
As a Solutions Engineer at Percona, one of my responsibilities is to support our customers as they investigate new and emerging technologies. This affords me the opportunity to speak to many current and new customers who partner with Percona.
The topic of Kubernetes is becoming more popular as companies are investigating and adopting this technology. The issue most companies are encountering is having a stateful database that doesn’t fall victim to an environment tuned for ephemeral workloads. This obviously introduces a level of complexity as to how to run a stateful database in an inherently stateless world, as databases are not natively designed for that.
To make your life easier, as a part of the Percona Cloud-Native Autonomous Database Initiative, our engineering teams have built a Percona Operator for MySQL based on Percona XtraDB Cluster, which allows for Pods to be destroyed, moved, or created with no impact to the application. So how does all this work?
Books could and have been written on how Kubernetes works, so to keep this as concise as possible we will talk about the major components which are relevant to the Percona Kubernetes Operator. If you need a quick introduction to Kubernetes, this short documentation from The Linux Foundation is a great resource.
The most pertinent information that we need to understand is that Kubernetes provides a mechanism for scheduling containers (via Pods) across a set of heterogeneous Nodes which are all members of a Kubernetes Cluster. Kubernetes can also schedule other resources like networking and storage. Through the use of StatefulSets, a collection of Pods can be bound to a set of unique resources such as Persistent Volumes via Persistent Volume Claims. These features allow a Node to fail and Kubernetes will reschedule your Pod(s) to another Node and for the storage to move with it, which enables us to run a stateful application like a database.
Operators provide full application lifecycle automation and make use of the Kubernetes primitives above to build and manage your application. We’ve created an Operator specifically designed for deploying, scaling, and managing the failover of the Percona XtraDB Cluster (PXC) database for MySQL workloads in Kubernetes.
The Kubernetes Control Plane manages the environments, which consist of Kubernetes Nodes. Pods are deployed on nodes.
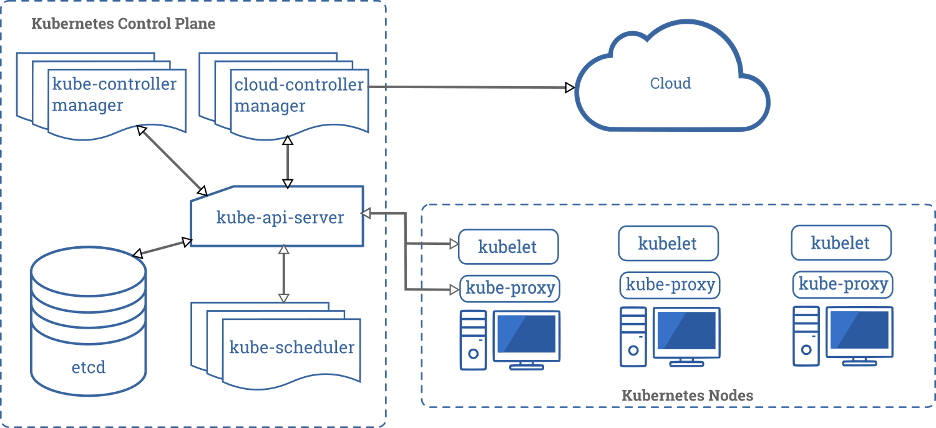
Image Reference: https://kubernetes.io/docs/concepts/overview/components/
Pods can be destroyed and recreated at any time on any node. To provide data storage for stateful applications, Kubernetes uses Persistent Volumes. A PersistentVolumeClaim is used to implement the automatic storage provisioning to pods. If a failure occurs, the Container Storage Interface (CSI) should be able to re-mount storage on a different Node alongside where your Pod was scheduled (Percona Documentation).
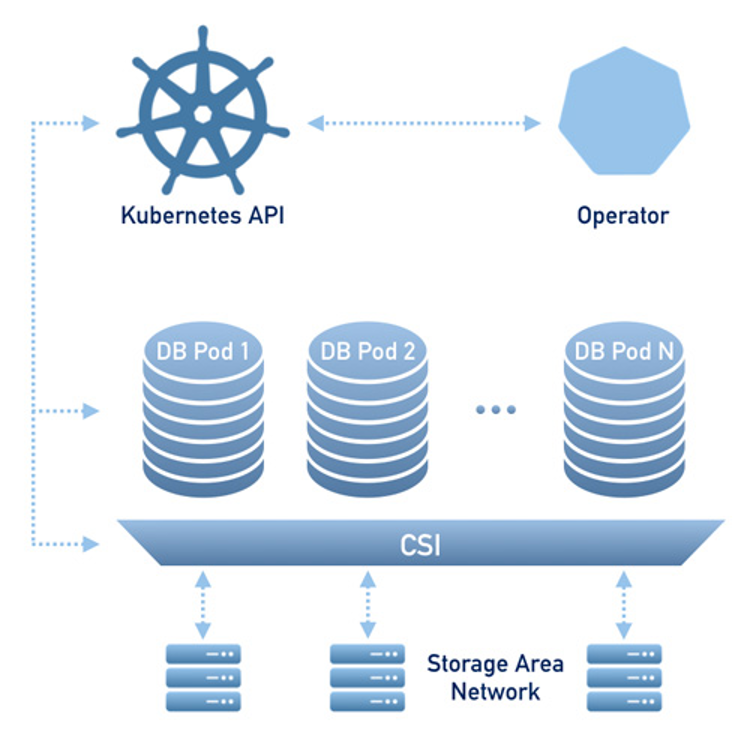
Image Reference: https://www.percona.com/doc/kubernetes-operator-for-pxc/architecture.html
StatefulSets manage Pods that have the same container specs. The Pods that are created are all from the same specs but, they have a unique and persistent identity that is maintained across rescheduling.
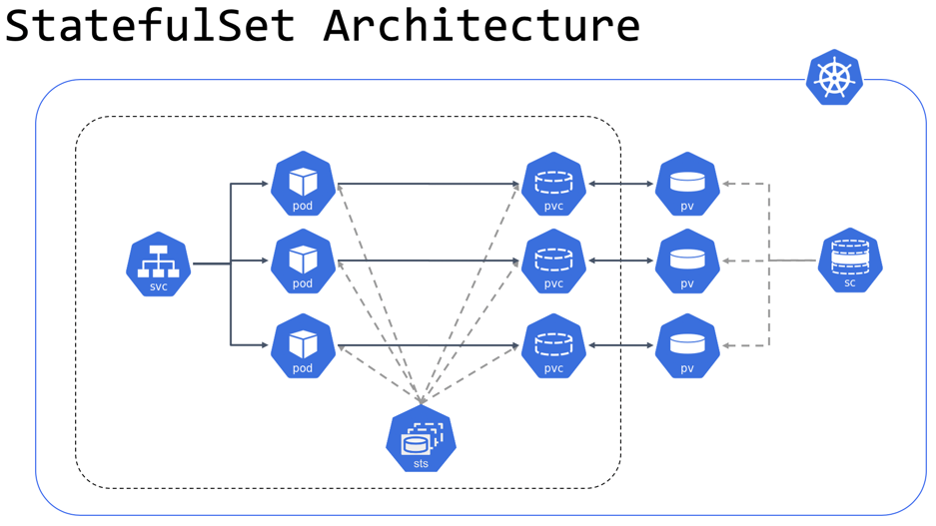
Image Reference: https://github.com/kubernetes/community/tree/master/icons
What’s important to understand is that Stateful Sets are how we maintain a Pod’s state when it is destroyed and re-created; this keeps us up and running.
A custom resource is an extension of the Kubernetes API. It’s customization added on to a Kubernetes installation.
Operators use custom resources to manage applications and their components. The Operator pattern aims to capture the key aim of a human operator who is managing a service or set of services (Kubernetes Documentation).
The Operator functionality extends the Kubernetes API with PerconaXtraDBCluster object, and it is implemented as a golang application. Each PerconaXtraDBCluster object maps to one separate PXC setup. The Operator listens to all events on the created objects. When a new PerconaXtraDBCluster object is created, or an existing one undergoes some changes or deletion, the operator automatically creates/changes/deletes all needed Kubernetes objects with the appropriate settings to provide a properly operating PXC (Percona Documentation).
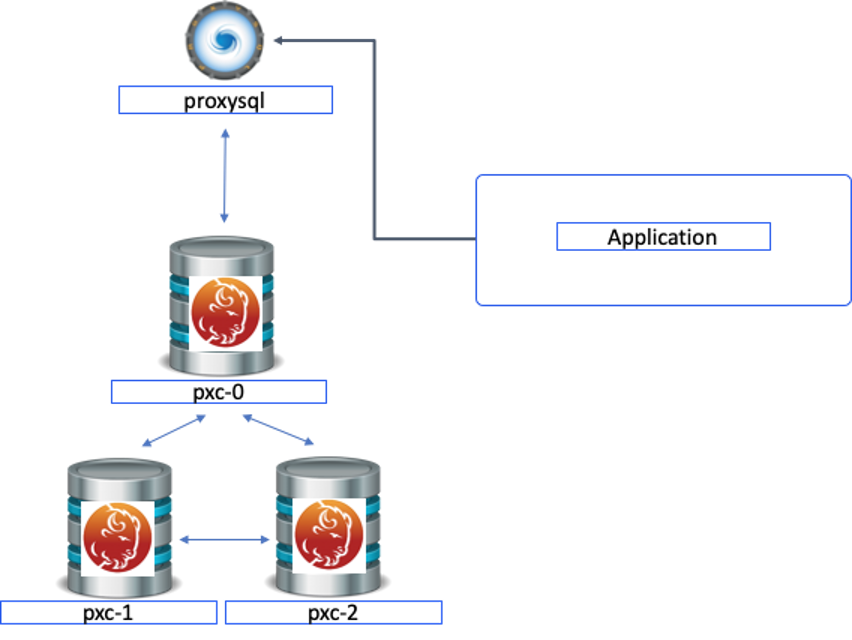
Percona XtraDB Cluster (PXC) is a fully open-source high-availability solution for MySQL. It integrates Percona Server for MySQL and Percona XtraBackup with the Galera library to enable synchronous multi-master replication.
A cluster consists of nodes, where each node contains the same set of data synchronized across nodes. The recommended configuration is to have at least 3 nodes. Each node is a regular Percona Server for MySQL instance. PXC implements ProxySQL in front of the cluster in order to assist with several functions such as splitting read and write traffic among nodes, as needed.
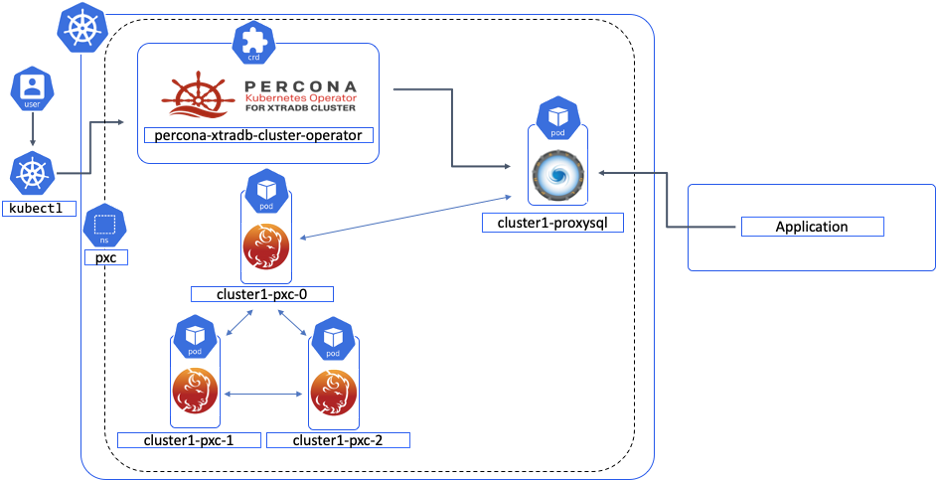
Ok, so finally we have come to how Percona XtraDB Cluster is deployed in Kubernetes. The different components of Percona XtraDB Cluster are run on pods: ProxySQL (one Pod per node if run in a cluster) and each node of the cluster, which is an instance of Percona Server for MySQL with synchronous Galera replication. Simple enough.
We utilize an Operator to automate the specific task of Percona XtraDB Cluster (scaling, backups, and more) and deploy the cluster in a StatefulSet with a Persistent Volume, which allows us to maintain a consistent identity for each Pod in the cluster and our data to be maintained, no matter which Nodes the Pods are deployed to, or when they choose to move around from one Node to another.
So how do we maintain a functioning cluster as Pods move around between nodes? Percona XtraDB Cluster has automated failover, so if one node goes down, the cluster operates without interruption as long as there’s a quorum of nodes available (majority). In such scenarios read and write traffic is directed accordingly automatically, transparently for your applications. Once the Pod(s) is recreated on a new node, then the Pod re-joins the cluster and the synchronization of the cluster is handled automatically. The nature of how Percona XtraDB Cluster functions meshes well with the volatile nature of Pods.
In order to adjust settings such as the size of the cluster, storage type, or where your backups or stored you can adjust the Custom Resource options in the deploy/cr.yaml.
I hope this blog has shed some light into a new world for some and for others, who may be Kubernetes gurus by now, you may want to take a look at some deeper level technical articles on Percona in the Kubernetes space:
How Container Networking Affects Database Performance
How to Measure MySQL Performance in Kubernetes with Sysbench
Deploying the Percona Operator for MySQL based on Percona XtraDB Cluster in Amazon (AWS)
Introducing the GA Release of Percona XtraDB Cluster 8.0
We understand that choosing open source software for your business can be a potential minefield. You need to select the best available options, which fully support and adapt to your changing needs. In this white paper, we discuss the key features that make open source software attractive, and why Percona’s software might be the best option for your business.
Resources
RELATED POSTS





Hi, im trying to understand something about the operator , in the documentation the deployment creates 1 pod with 1 container each for avery component in the cluster, but when i run this scripts in a real environment i get 3 containers per pod consuming 3 times resources as is intended, is there a way to change this behavior?