

The Percona Operator for PostgreSQL 3.0.0 is here. This is the release that completes the hard fork of the operator from the Crunchy Data PostgreSQL Operator into a fully independent project, with a dedicated upstream.pgv2.percona.com API group for the inherited CRDs, an automatic CRD-rename rollout for existing 2.x installs on upgrade, and a public roadmap that drives what comes next.
This release ships three headline changes that matter for production teams. The CRD renaming under a Percona-owned API group, which finally lets the Crunchy operator and the Percona operator coexist in the same Kubernetes cluster. Proper OLM namespace scoping for OpenShift installations. And the move to the official Percona Distribution image for major PostgreSQL version upgrades, aligning the upgrade path with the same binaries that run in your clusters.
All three land in service of the same goal: making 3.0.0 a clean, durable operational baseline for the operator’s next several years as an independent project. Future releases will be shaped by what the community asks for and contributes back. The public roadmap is the durable signal of that commitment.
In this post, you will learn about:
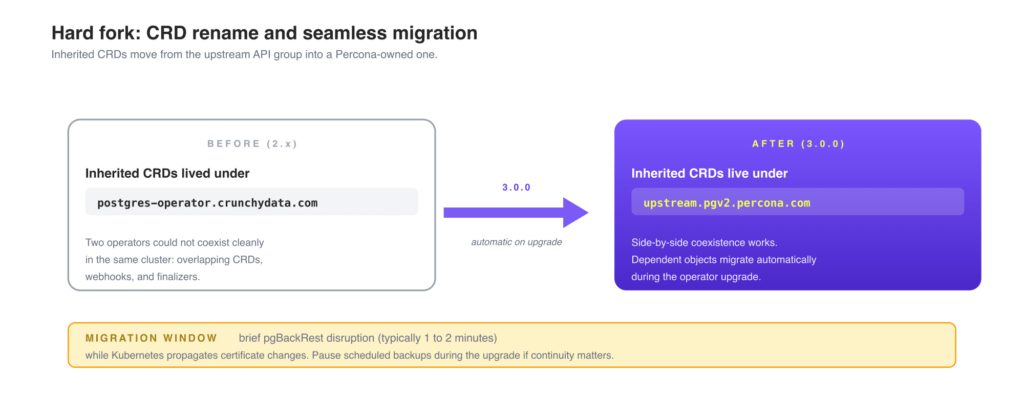
The Percona Operator for PostgreSQL has, until now, been a soft fork. Custom Resources inherited from Crunchy PGO used the upstream postgres-operator.crunchydata.com API group. The two operators shared CRDs, which meant you could only run one of them in a given Kubernetes cluster. Installing both would lead to overlapping CRDs, conflicting webhooks, and finalizer collisions, so platform teams had to pick a side before they had finished evaluating.
Starting with 3.0.0, every inherited CRD is renamed into a new dedicated upstream.pgv2.percona.com API group (K8SPG-1007). Percona’s own native CRDs (such as PerconaPGCluster under pgv2.percona.com/v2) are unchanged. The change applies to the inherited resources: PostgresCluster, PGUpgrade, PGAdmin, and the rest.
The practical effect is that the Crunchy Data PostgreSQL Operator and the Percona Operator for PostgreSQL can now run on the same Kubernetes cluster at the same time, even in the same namespaces, with no CRD or webhook conflict. That unlocks a few real workflows: evaluating both operators on the same staging cluster without spinning up a second cluster, running existing Crunchy-managed clusters in some namespaces while bringing up new Percona-managed clusters in others, or testing a new database version on the Percona side while production stays on Crunchy until you are confident. The choice between the two operators stops being all-or-nothing.
For an existing install, the upgrade to 3.0.0 is mechanically simple. The operator creates the new-API-group CRDs alongside the legacy ones, then runs a one-time migration that updates dependent objects (Secrets, certificates, finalizer references) to point at the new CRD instances. Existing custom resources keep working through the legacy CRDs during the transition, and once migration completes, all reconciliation moves to the new group.
Old PostgresCluster reference:
|
1 2 3 4 |
apiVersion: postgres-operator.crunchydata.com/v1beta1 kind: PostgresCluster metadata: name: cluster1 |
New (after upgrade to 3.0.0):
|
1 2 3 4 |
apiVersion: upstream.pgv2.percona.com/v1beta1 kind: PostgresCluster metadata: name: cluster1 |
Day-to-day, your PerconaPGCluster Custom Resource (the one most teams interact with directly) is unchanged. The rename mostly matters in three situations: when a kubectl filter or a GitOps repository hard-codes the old API group, when a CI pipeline references the legacy CRD by name, and when you run the Percona and Crunchy operators side by side and need them not to collide.
Note: During the CRD migration on upgrade, the release notes report brief disruptions to pgBackRest operations (typically 1 to 2 minutes) while Kubernetes propagates certificate changes. Plan the upgrade during a maintenance window if backup continuity is critical, or pause scheduled backups during the upgrade.
Full details on the API-group change are in the Percona PostgreSQL operator documentation.
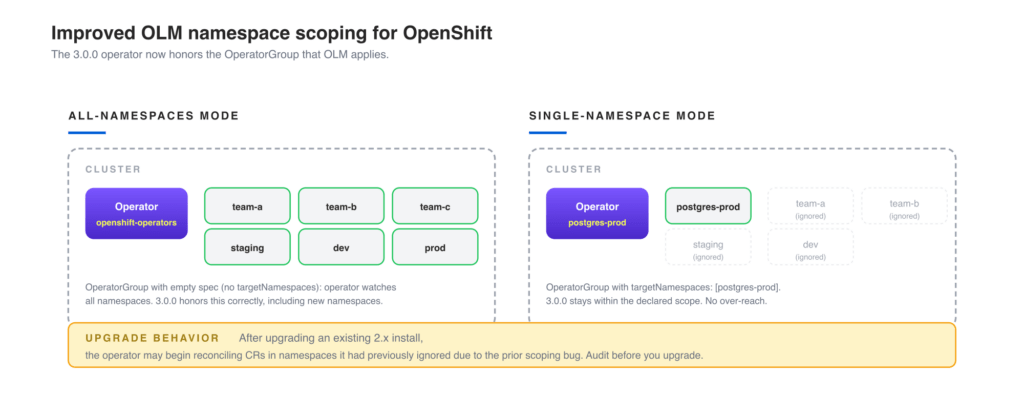
OpenShift users install operators through the OpenShift Lifecycle Manager (OLM), and OLM enforces an OperatorGroup to scope which namespaces an operator watches. In practice, 2.x had quirks: teams that selected “Single namespace” mode would sometimes see the operator reconciling CRs in other namespaces, and teams in “All namespaces” mode would sometimes see incomplete coverage when CRs were created in newly-added namespaces.
3.0.0 fixes this by aligning the operator’s namespace watch list with the OperatorGroup that OLM applies. All-namespaces installs watch all namespaces. Single-namespace installs respect the targetNamespaces set on the OperatorGroup.
For an OpenShift platform team running shared infrastructure, this distinction matters operationally. A typical setup has the database operator installed once in a platform namespace (such as openshift-operators) but expected to serve PerconaPGCluster resources owned by individual application teams in their own namespaces. If the operator over-reaches into namespaces it should not watch, RBAC noise multiplies. If it under-reaches, application teams file tickets about clusters that never reconcile. The 3.0.0 alignment with OperatorGroup semantics removes both failure modes.
For users installing through OLM via the OpenShift web console, the install flow is unchanged. The fix is in how the operator’s reconciler interprets the OLM-supplied namespace scope after install. For users who manage OperatorGroups directly, a single-namespace install looks like this:
|
1 2 3 4 5 6 7 8 |
apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: percona-pg-operator-group namespace: postgres-prod spec: targetNamespaces: - postgres-prod |
And an all-namespaces install:
|
1 2 3 4 5 6 |
apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: percona-pg-operator-group namespace: openshift-operators spec: {} |
The empty spec: {} (or an OperatorGroup with no targetNamespaces) means “watch all namespaces” by OLM convention. The 3.0.0 operator now honors that.
Note: After you upgrade an existing 2.x install to 3.0.0, the operator may begin reconciling PerconaPGCluster resources in namespaces it had previously ignored due to the prior scoping bug. Audit existing CRs across your cluster before upgrading, especially if you have stale test clusters in unintended namespaces. The release notes call this out explicitly.
Note for community vs certified bundle users: Community OLM bundles did not support cluster-wide (all-namespaces) mode in earlier versions, 3.0.0 adds it. Certified bundles already supported cluster-wide mode, but they used a separate stable-cw channel for it with 3.0.0 the channels are unified, so users upgrading from a certified stable-cw install need to switch their subscription channel to stable to receive the upgrade.
For the full install workflow on OpenShift, see the OpenShift installation documentation.

Major-version upgrades (for example, PostgreSQL 17 to 18) require running pg_upgrade, which needs binaries for both the source and target versions in the same environment. The operator has supported major-version upgrades since 2.x, but it shipped its own dedicated upgrade image to do so. That worked, but it meant a Percona-specific image lived in the upgrade path, separate from the same Percona Distribution for PostgreSQL build that runs in your clusters.
In 3.0.0, the operator switches to using the official Percona Distribution for PostgreSQL image for major-version upgrades: percona/percona-distribution-postgresql-upgrade (current tag: 18.4-17.10-16.14-15.18-14.23-1, which encodes the bundled major versions). The benefit is alignment: the binaries that run pg_upgrade are the same binaries that ship in the corresponding percona-distribution-postgresql image you already run in production, built from the same source, signed the same way, and patched on the same schedule. The operator orchestrates the upgrade through the PerconaPGUpgrade Custom Resource that names the source and target versions, the upgrade image, and the target component images (PostgreSQL, pgBouncer, pgBackRest).
A PostgreSQL 17 to 18 upgrade looks like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
apiVersion: pgv2.percona.com/v2 kind: PerconaPGUpgrade metadata: name: cluster1-17-to-18 spec: postgresClusterName: cluster1 image: docker.io/percona/percona-distribution-postgresql-upgrade:18.4-17.10-16.14-15.18-14.23-1 fromPostgresVersion: 17 toPostgresVersion: 18 toPostgresImage: docker.io/percona/percona-distribution-postgresql:18.4-1 toPgBouncerImage: docker.io/percona/percona-pgbouncer:1.25.2-1 toPgBackRestImage: docker.io/percona/percona-pgbackrest:2.58.0-2 |
Apply it with kubectl apply -f upgrade.yaml -n <namespace>. The operator reconciles the upgrade as a controlled, observable process: it brings the cluster down for the upgrade window, runs pg_upgrade from the bundled image, brings the cluster back up on the target version, and updates pgBouncer and pgBackRest images in the same step.
Operationally, this matters for teams running on PostgreSQL’s annual major-version cadence. Every September brings a new major release; staying on a supported version means executing one major upgrade per cluster per year. Pulling the upgrade image from the same percona-distribution-postgresql registry path as the runtime image means image-signature verification, mirror-to-private-registry rules, and CVE-scanning policies you already have in place apply to the upgrade flow without any per-image exception.
Note: The pgaudit extension is not upgraded automatically. After the operator completes the major version upgrade, drop and recreate pgaudit manually in each database that uses it: DROP EXTENSION pgaudit; followed by CREATE EXTENSION pgaudit;. The release notes call this out as a required step (K8SPG-1022). Also worth scanning for collation-dependent indexes after the upgrade and refreshing collation metadata with ALTER DATABASE <name> REFRESH COLLATION VERSION; per the upstream PostgreSQL 18 release notes.
Full procedure, prerequisites, and rollback notes are in the major version upgrade documentation.
Operational polish landed alongside the headline changes:
The release also defaults the cluster-upgrade documentation to PostgreSQL 18 across all examples and tutorials.
The Percona Operator for PostgreSQL 3.0.0 is developed and tested on:
Support for Custom Resource Definitions from operator version 2.7.0 has been removed. If you are still on 2.7.0, upgrade to 2.8.x or 2.9.x first, then upgrade to 3.0.0. The CRD migration described above only handles 2.8.x and 2.9.x to 3.0.0 transitions cleanly.
3.0.0 is the release where the Percona Operator for PostgreSQL becomes a fully independent project. The CRD rename removes the last upstream coupling that mattered operationally. The OLM scoping fix removes a long-standing OpenShift quirk. The official major-version upgrade image removes one of the more painful operational gaps in earlier versions.
Beyond the technical work, 3.0.0 is also where Percona’s commitment to community-driven development moves from intent to mechanism. The public roadmap is open. The issue tracker is open. The images are freely redistributable. Future releases will be shaped by what the community asks for, files, and contributes back. If there is a feature you want to see in 3.1.0 or 3.2.0, open an issue or a PR, that is where the work happens now.
Resources
RELATED POSTS




