
 Percona has been investing in building and releasing Operators for Kubernetes to run traditional databases in a cloud-native fashion. The first two Kubernetes operators were for Percona Server for MongoDB and Percona XtraDB Cluster, chosen because they both feature replication systems that can be made to work effectively in a containerized world.
Percona has been investing in building and releasing Operators for Kubernetes to run traditional databases in a cloud-native fashion. The first two Kubernetes operators were for Percona Server for MongoDB and Percona XtraDB Cluster, chosen because they both feature replication systems that can be made to work effectively in a containerized world.
One of the first questions we wanted to answer about databases in Kubernetes was around performance. Many of our customers using Kubernetes for production application workloads are running their databases on bare metal or VMs outside Kubernetes due to concerns around performance in Kubernetes. Therefore, we worked to dive into the Kubernetes abstraction layers and identify key areas worth testing, and devise useful benchmarks.
We started with networking, as it has an outsized impact on performance due to the need to utilize networked storage in most Kubernetes environments for resilience. Additionally, we know that networking has been a constant area of challenge and improvement in the containerization space. Finally, we see performance generally, but network performance specifically, as a major barrier of adoption for people considering migrating their database workloads into Kubernetes. It is valuable that there exists a bridge for databases into Kubernetes that make it more feasible to run your production workloads there. In the end, we wanted to understand everything necessary to take running databases in Kubernetes — from a “don’t do that” to a “yes, do this” perspective.
This blog post is based directly on the outcome of these efforts, which we also recently shared at KubeCon North America.
To conduct this benchmark we sought to build a methodology that would specifically isolate as many variables as possible to focus exclusively on how networking affects performance. To that end, we ensured that the dataset we used would fit into memory, that we warmed up any caches before executing runs, that we were utilizing local storage in Kubernetes, and that we executed enough benchmarking runs to eliminate variability. We also wanted the data to be a true comparison, so we ensured we were comparing apples to apples via our infrastructure topology.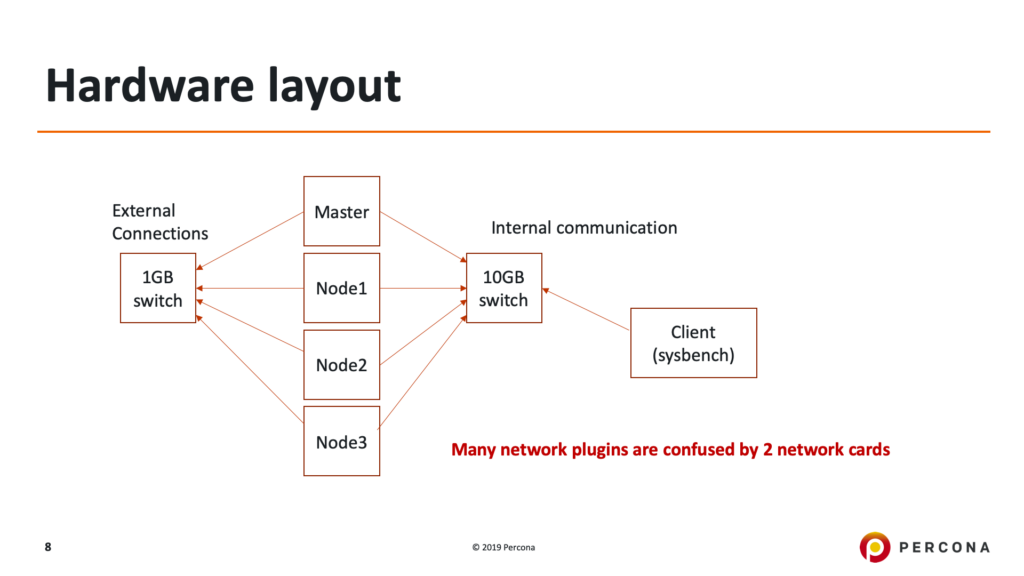
Each of five physical servers in a cabinet within Percona’s test datacenter was connected to a top-of-rack 10GbE and top-of-rack 1GbE switch, comprising two separate physical networks on separate IP subnets. One of the five servers acted as a sysbench client for simulating workloads, and the remaining four comprised the Kubernetes and Database roles. During bare-metal testing, the three servers which were Kubernetes Nodes were run as they were, during Kubernetes testing these three servers were deployed as Nodes to host the database Pods, and the fourth server was set aside to act only as the Kubernetes Master.
To deploy the Kubernetes environment we used kubeadm and tried to stay with basic defaults as much as possible to ensure we weren’t creating confounders in our testing. We used Kubernetes 1.16. The Percona XtraDB Cluster was deployed using the 1.2.0 release of Percona Kubernetes Operator for Percona XtraDB Cluster, based on Percona XtraDB Cluster 5.7.27-31.39. To deploy the bare metal environment, the installation was performed manually using Percona shipping packages from our public repository for Percona XtraDB Cluster 5.7.27-31.39. In both cases, we disabled ProxySQL and exposed the Percona XtraDB Cluster cluster members directly to the network and configured our sysbench client so that all traffic was directed to only a single member of the Percona XtraDB Cluster cluster. For both bare-metal testing and Kubernetes based testing the host operating system was Ubuntu 16.04 LTS running kernel version 4.15.0-66-generic as shipped with Ubuntu 16.04 LTS.
The hardware contained in the servers is enumerated below:
For environment setup, we installed each CNI plugin within a fresh deployment of Kubernetes following the provided instructions to ensure that it sent traffic across the 10GbE network. We ran database benchmarking utilizing sysbench and the oltp-read-write workload. Additionally, we captured network throughput data using iPerf3. In order to ensure that the database itself was not the bottleneck, we utilized a well-tuned MySQL configuration which was provided as a ConfigMap to the Kubernetes Operator. Finally, for local storage, we utilized the HostPath method in Kubernetes to ensure that we could provision volumes for the database without crossing a network boundary so that only transactional and replication workloads would be touching the network.
Our tuned my.cnf is below:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
[mysqld] table_open_cache = 200000 table_open_cache_instances=64 back_log=3500 max_connections=4000 innodb_file_per_table innodb_log_file_size=10G innodb_log_files_in_group=2 innodb_open_files=4000 innodb_buffer_pool_size=100G innodb_buffer_pool_instances=8 innodb_log_buffer_size=64M innodb_flush_log_at_trx_commit = 1 innodb_doublewrite=1 innodb_flush_method = O_DIRECT innodb_file_per_table = 1 innodb_autoinc_lock_mode=2 innodb_io_capacity=2000 innodb_io_capacity_max=4000 wsrep_slave_threads=16 wsrep_provider_options="gcs.fc_limit=16;evs.send_window=4;evs.user_send_window=2" |
Our tuned settings for resources in Kubernetes is below:
|
1 2 3 4 5 6 7 |
resources: requests: memory: 150G cpu: "55" limits: memory: 150G cpu: "55" |
We do this because of the Pod resource Quality of Service (QoS) in Kubernetes. Kubernetes provides different levels of QoS to Pods depending on what their requests and limits are set to. In typical scenarios, where you specify only a requests block but not limits, Kubernetes utilized “Best Effort QoS”, but when requests and limits are set for all resources across all containers and they are equal, Kubernetes will instead utilize “Guaranteed QoS”. This can have a significant impact on performance variability.
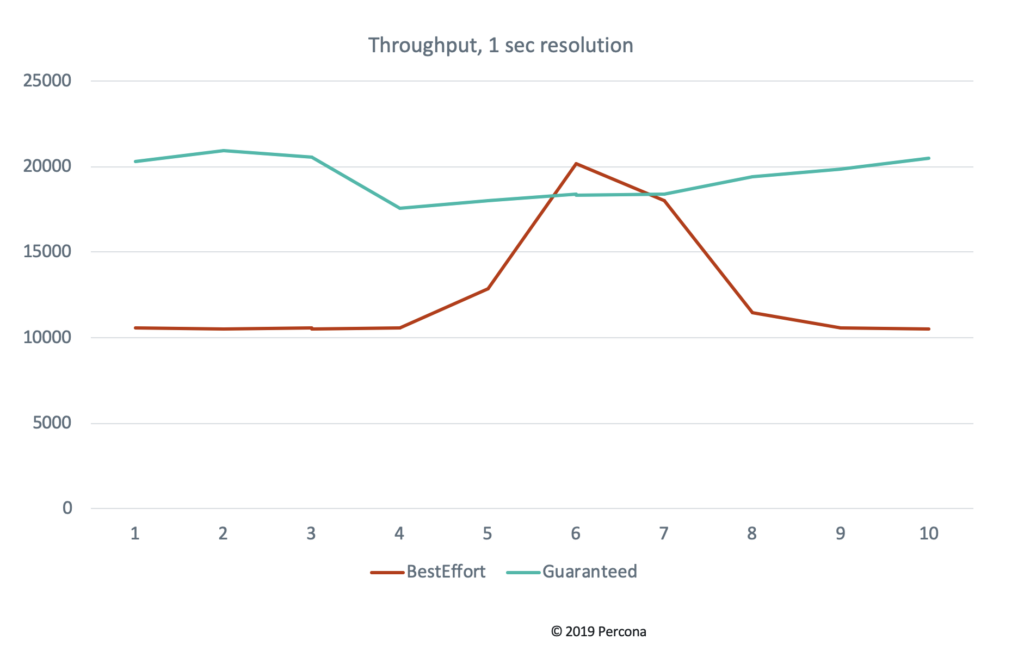
Additionally, you need to know the sysbench command line we used to run the test, below:
|
1 |
./sysbench --test=tests/db/oltp.lua --oltp_tables_count=10 -- oltp_table_size=10000000 --num-threads=64 --mysql-host=172.16.0.4 -- mysql-port=30444 --mysql-user=root --mysql-password=root_password --mysql-db=sbtest10t --oltp-read-only=off --max-time=1800 --max- requests=0 --report-interval=1 --rand-type=pareto --rand-init=on run |
We selected the CNI plugins to test based on what we’ve encountered with our customers and partners, as well as a few entrants which are specifically interesting for performance reasons. There’s no particular order to this list and our goal was not to conclude with any specific recommendations of which plugin to use. All the CNI plugins differ in their project goals which leads them to make different design and engineering trade-offs which may have a performance impact, but depending on your environment those tradeoffs may be reasonable.
Project Calico is a popular option for many enterprises doing on-premise deployment due to the simplicity with which it allows you to assign routable IPs to Pods and integrate it with your existing top of rack networking equipment. In this vein, we tested Calico with IP-in-IP enabled (default) and disabled.
Flannel is a network fabric with Kubernetes that supports pluggable backends. The default backend is UDP based, but it also supports vxlan and a host-gw backend. We were unable to get host-gw working, but we were able to test with UDP and vxlan. We encountered interesting stall conditions with vxlan, even though the overall performance was good. We think these stalls may be a kernel issue due to our much older kernel, but we did not have an opportunity yet to pursue this by testing against multiple kernel versions.
Cilium is API-aware networking and security using BPF and XDP. It’s primarily focused on the network security policy use case. It had a very straightforward installation, but during our available time for benchmarking, we were unable to get it to route across the 10GbE network, which obviously impacted performance results. The tests otherwise succeeded, but keep in mind, we are still reporting these results.
Weave is a tightly integrated and simple to deploy multi-host container networking system. Despite showing that Pods were assigned IPs within our 10GbE netblock, traffic was being routed across the 1GbE network. We spent considerable amounts of time troubleshooting this and were unable to resolve it in our available time. We are still reporting these results.
Multus is a CNI plugin that enables attaching multiple network interfaces to a Pod. This is required because the SR-IOV CNI plugin cannot be your sole Pod network, it is an add-on interface in addition to the default Pod network. We utilized Kube-Router for the default Pod network and assigned a second interface with SR-IOV over the 10GbE network for this test. SR-IOV has a complex setup process, but allows for much of the networking to be offloaded to the hardware and assigns effectively a virtual NIC in hardware (VF) to each Pod on the host as a network device. In theory, it should have near line-rate performance, so it was worth the complexity to try it out.
Kube-Router is a simple turn-key solution for Kubernetes networking. It also is the default plugin deployed by kubeadm, so it is incredibly simple to deploy, The minimal feature set incurs very little overhead, which you will see reflected in the results.
As a baseline, we first performed testing on bare metal and showed that our benchmarks were limited by network performance alone. In these tests, we achieved 2700 tps over 1GbE and 7302 tps over 10GbE.
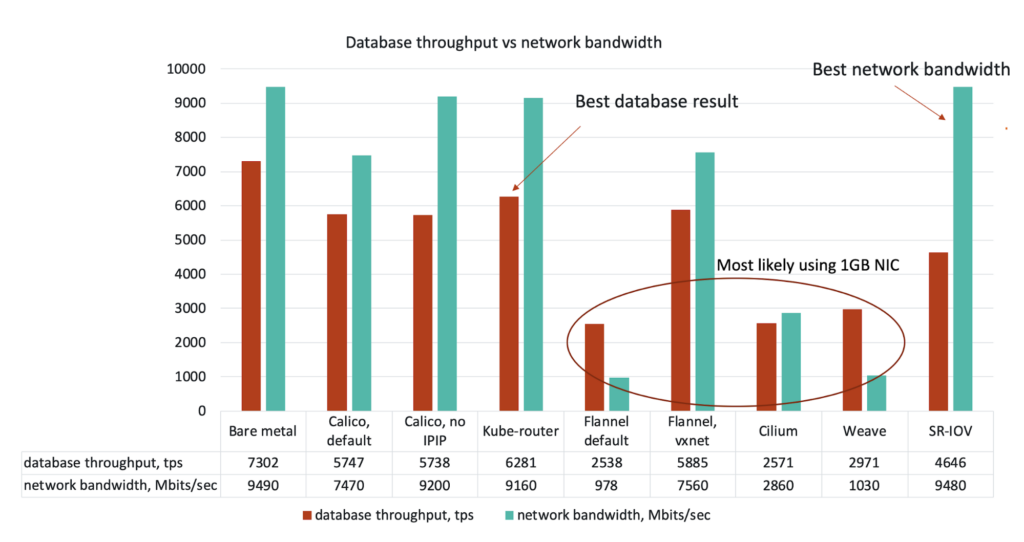
One very interesting result was how strong the correlation was between network throughput, as measured by iPerf3, and database throughput, as measured by sysbench. This correlation was significantly broken by SR-IOV, which we expected to be the best performer. It had near bare-metal network throughput but about half the expected database throughput. We suspect this result has to do with transaction sizing due to latency incurred inside the hardware virtualization layer inherent to SR-IOV and we plan to validate this suspicion in future benchmarks.
Another key thing we found was that even in the best-case with Kube-Router we see an approximate 13% decrease in database performance comparing bare metal to running within Kubernetes. This illustrates that there are still improvements to be made to the performance of container networking in Kubernetes.
Don’t let common database problems cost you your performance – Read our eBook for solutions today!
As a follow-up, there are a few additional things we’d like to do:
As a result of this work, we’ve been grateful to get more involved in the Kubernetes community. Percona is now actively involved with SIG Storage helping define the proper methodologies for benchmarking database and storage workloads, and in SIG Scalability — and helping to form a working group for application performance testing and improvement. Through these activities and others, we hope to increase the performance of all applications within the Kubernetes landscape, especially in databases like MySQL, MongoDB, and PostgreSQL on Kubernetes.
Enjoy the full recording of Tyler Duzan and Vadim Tkachenko from KubeCon North America, “How Container Networking Affects Database Performance“:
Resources
RELATED POSTS





have you enabled jumbo frames? weave net performance is depending on mtu