
This post is the third of a series focusing on the MySQL high availability solutions available in 2017.
The first post looked at the elders, the technologies that have been around for more than ten years. The second post talked about the adults, the more recent and mature technologies. In this post, we will look at the emerging MySQL high availability solutions. The “baby” MySQL high availability solutions I chose for the blog are group replication, proxies and distributed storage.
Group replication is the Oracle response to Galera. The term “InnoDB cluster” means a cluster using group replication. The goal is offering similar functionalities, especially the almost synchronous feature.
At first glance, the group replication implementation appears to be rather elegant. The basis is the GTID replication mode. The nodes of an InnoDB cluster share a single UUID sequence. To control the replication lag, Oracle added a flow control layer. While Galera requires unanimity, group replication only requires a majority. The majority protocol in use is derived from Paxos. A majority protocol makes the cluster more resilient to a slow node.
Like Galera, when you add flow control you needs queues. Group replication has two queues. There is one queue for the certification process and one queue for the appliers. What is interesting in the Oracle approach is the presence of a throttling mechanism. When flow control is requested by a node, instead of halting the processing of new transactions like Galera, the rate of transactions is throttled. That can help to meet strict timing SLAs.
Because the group replication logic is fairly similar to Galera, they suffer from the same limitations: large transactions, latency and hot rows. Group replication is recent. The first GA version is 5.7.17, from December 2016. It is natural then that it has a number of sharp edges. I won’t extend too much here, but if you are interested read here, here. I am confident over time group replication will get more polished. Some automation, like the Galera SST process, would also be welcome.
Given the fact the technology is recent, I know no Percona customer using group replication in production.
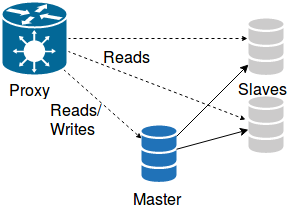
Intelligent proxies can be viewed as another type of upcoming MySQL high availability solution. It is not strictly MySQL. In fact, this solution is more of a mix of other solutions.
The principle is simple: you connect to a proxy, and the proxy directs you to a valid MySQL server. The proxy has to monitor the states of the back-end servers, and maybe even perform actions on them. Of course, the proxy layer must not become a single point of failure. There should be more than one proxy host for basic HA. If more that one proxy is used at the same time, they’ll have to agree on the state of the back-end servers. For example, on a cluster using MySQL async replication, if the proxies are not sending the write traffic to the same host, things will quickly become messy.
There are few ways of achieving this. The simplest solution is an active-passive setup where only one proxy is active at a given time. You’ll need some kind of logic to determine if the proxy host is available or not. Typical choices will use tools like keepalived or Pacemaker.
A second option is to have the proxies agree to a deterministic way of identifying a writer node. For example, with a Galera-based cluster, the sane back-end node with the lowest wsrep_local_index could be the writer node.
Finally, the proxies could talk to each other and coordinate. Such an approach is promising. It could allow a single proxy to perform the monitoring and inform its peers of the results. It would allow also coordinated actions on the cluster when a failure is detected.
Currently, there are a few options in terms of proxies:
To these open source proxies, there are two well-known commercial proxy-like solutions, Tungsten and ScaleArc. Both of these technologies are mature and are not “babies” in terms of age and traction. On top of these, there are also numerous hardware-based load balancer solutions.
The importance of proxies in MySQL high availability has led Percona to include ProxySQL in the latest releases of Percona XtraDB Cluster. In collaboration with the ProxySQL maintainer, René Cannaò, features have been added to make ProxySQL aware of the Percona XtraDB Cluster state.
Proxies are already often deployed in MySQL high availability solutions. Often proxies are only doing load balancing type work. We start to see deployment using proxies for more advanced things, like read/write splitting and sharding.
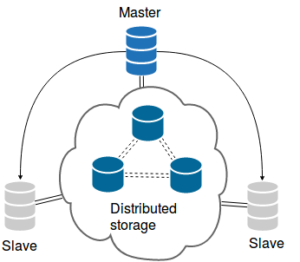
This MySQL high availability solution is a project I am interested in. It is fair to say it is more a “fetus” than a real “baby,” since I know nobody using it in production. You can see this solution as a shared storage approach on steroids.
The simplest solution requires a three-node Ceph cluster. The nodes also run MySQL and the datadir is a Ceph RBD block device. Data in Ceph is automatically replicated to multiple hosts. This built-in data replication is an important component of the solution. Also, Ceph RBD supports snapshots and clones. A clone is a copy of the whole data set that consumes only the data that changed (delta) in terms of storage. Our three MySQL servers will thus not use three full copies of the dataset, but only one full copy and two deltas. As time passes, the deltas grow. When they are too large, we can simply generate new snapshots and clones and be back to day one. The generation of a new snapshot and clone takes a few seconds, and doesn’t require stopping MySQL.
The obvious use case for the distributed storage approach is a read-intensive workload on a very large dataset. The setup can handle a lot of writes. The higher the write load, the more frequently there will be a snapshot refresh. Keep in mind that refreshing a snapshot of a 10 TB data set takes barely more time than for a 1 GB data set.
For that purpose, I wrote an SST script for Percona XtraDB Cluster that works with Ceph. I blogged about it here. I also wrote a Ceph snapshot/clone backup script that can provision a slave from a master snapshot. I’ll blog about how to use this Ceph backup script in the near future.
Going further with distributed storage, multiple MySQL instances could use the same data pages. Ceph would be use as a distributed object store for InnoDB pages. This would allow to build an open-source Aurora like database. Coupled with Galera or Group replication, you could have a highly-available MySQL cluster sharing a single copy of the dataset.
I started to modify MySQL, actually Percona Server for MySQL 5.7, to add support for Ceph/Rados. Rados is the object store protocol of Ceph. There is still a lot of effort needed to make it work. My primary job is not development, so progress is slow. My work can be found (here). The source compiles well but MySQL doesn’t fully start. I need to debug where things are going wrong.
Adding a feature to MySQL like that is an awesome way to learn the internals of MySQL. I would really appreciate any help if you are interested in this project.
Over the three articles in this series, we have covered the 2017 landscape of MySQL high availability solutions. The first focused on the old timers, “the elders”, composed of: replication, shared storage and NDB. The second articles dealt with the solutions that are more recent and have a good traction: Galera and RDS Aurora. The conclusion of the series is the current article, which looked at what could be possibly coming in term of MySQL high availability solutions.
The main goal of this series is to help planning the deployment of MySQL in a highly-available way. I hope it can be used for hints and pointers to get better and more efficient solutions.





(The “adults” link is broken.)
I am surprised you didn’t mention Vitess under the list of proxies.
One might argue that the Amazon RDS MultiAZ feature is sort of a distributed storage solution as well, similar to ceph although the performance of snapshots is a lot slower than with RBD.
‘@Rick fixed, thanks for reporting it
@jon, I could have mention Vitess but I have very little knowledge of it. It is on my todo list of thechnologies to look at, I may write a post about vitess in the future.
@Nils Indeed, EBS snapshot performance is really poor. The time to take a snapshot is not too bad but upon restore, although the volume is available quickly, its performance is degraded for a long time.