
In this blog, we’ll look at different MySQL high availability options.
The dynamic MySQL ecosystem is rapidly evolving many technologies built around MySQL. This is especially true for the technologies involved with the high availability (HA) aspects of MySQL. When I joined Percona back in 2009, some of these HA technologies were very popular – but have since been almost forgotten. During the same interval, new technologies have emerged. In order to give some perspective to the reader, and hopefully help to make better choices, I’ll review the MySQL HA landscape as it is in 2017. This review will be in three parts. The first part (this post) will cover the technologies that have been around for a long time: the elders. The second part will focus on the technologies that are very popular today: the adults. Finally, the last part will try to extrapolate which technologies could become popular in the upcoming years: the babies.
Quick disclaimer, I am reporting on the technologies I see the most. There are likely many other solutions not covered here, but I can’t talk about technologies I have barely or never used. Apart from the RDS-related technologies, all the technologies covered are open-source. The target audience for this post are people relatively new to MySQL.
Let’s define the technologies in the elders group. These are technologies that anyone involved with MySQL for last ten years is sure to be aware of. I could have called this group the “classics”. I include the following technologies in this group:
Let’s review these technologies in the following sections.
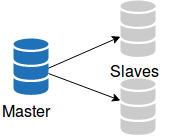
MySQL replication is very well known. It is one of the main features behind the wide adoption of MySQL. Replication gets used almost everywhere. The reasons for that are numerous:
Of course, replication also has some issues:
Although an old technology, a lot of work has been done on replication. It is miles away from the replication implementation of 5.0.x. Here’s a list, likely incomplete, of the evolution of replication:
Managing replication is a tedious job. The community has written many tools to manage replication:
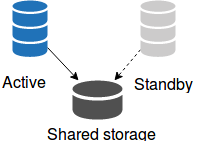
Back when I was working for MySQL ten years ago, shared storage HA setups were very common. A shared storage HA cluster uses one copy of the database files between one of two servers. One server is active, the other one is passive. In order to be shared, the database files reside on a device that can be mounted by both servers. The device can be physical (like a SAN), or logical (like a Linux DRBD device). On top of that, you need a cluster manager (like Pacemaker) to handle the resources and failovers. This solution is very popular because it allows for failover without losing any transactions.
The main drawback of this setup is the need for an idle standby server. The standby server cannot have any other assigned duties since it must always be ready to take over the MySQL server. A shared storage solution is also obviously not resilient to file-level corruption (but that situation is exceptional). Finally, it doesn’t play well with a cloud-based environment.
Today, newly-deployed shared storage HA setups are rare. The only ones I encountered over the last year were either old implementations needing support, or new setups that deployed because of existing corporate technology stacks. That should tell you about the technology’s loss of popularity.
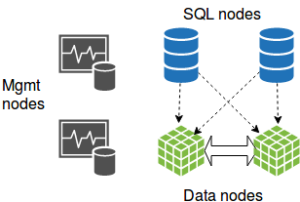
An NDB Cluster is a distributed clustering solution that has been around for a long time. I personally started working with this technology back in 2008. An NDB Cluster has three types of nodes: SQL, management and data. A full HA cluster requires a minimum of four nodes.
An NDB Cluster is not a general purpose database due to its distributed nature. For suitable workloads, it is extraordinary good. For unsuitable workloads, it is miserable. A suitable workload for an NDB Cluster contains high concurrency, with a high rate of small primary key oriented transactions. Reaching one million trx/s on an NDB Cluster is nothing exceptional.
At the other end of the spectrum, a poor workload for an NDB Cluster is a single-threaded report query on a star-like schema. I have seen some extreme cases where just the network time of a reporting query amounted to more than 20 minutes.
Although NDB Clusters have improved, and are still improving, their usage has been pushed toward niche-type applications. Overall, the technology is losing ground and is now mostly used for Telcos and online gaming applications.





Can you a Post with what is the current best alternative to each old Solution?
what about babies and adults?
looking forward to read about “adults” and “babies” 🙂
Hi Yves,
Look forward to reading your adult/baby blogs in this subject. Any ETA please ? 🙂
BTW, do you count Galera cluster PAUSE (Flow Control occurred) as available
James