
In this blog post, we’ll look at some of the MySQL high availability solution options.
In the previous post of this series, we looked at the MySQL high availability (HA) solutions that have been around for a long time. I called these solutions “the elders.” Some of these solutions (like replication) are heavily used today and have been improved from release to release of MySQL.
This post focuses on the MySQL high availability solutions that have appeared over the last five years and gained a fair amount of traction in the community. I chose to include this group only two solutions: Galera and RDS Aurora. I’ll use the term “Galera” generically: it covers Galera Cluster, MariaDB Cluster and Percona XtraDB Cluster. I debated for some time whether or not to include Aurora. I don’t like the fact that they use closed source code. Given the tight integration with the AWS environment, what is the commercial risk of opening the source code? That question evades me, but I am not on the business side of technology. 🙂
When I say “Galera,” it means a replication protocol supported by a library provided by Codeship, a Finnish company. The library needs hooks inside the MySQL source code for the replication protocol to work. In Percona XtraDB cluster, I counted 66 .cc files where the word “wsrep” is present. As you can see, it is not a small task to add support for Galera to MySQL. Not all the implementations are similar. Percona, for example, focused more on stability and usability at the expense of new features.
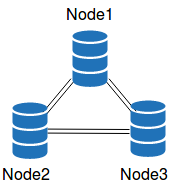
Let’s start with a quick description of a Galera-based cluster. Unless you don’t care about split-brain, a Galera cluster needs at least three nodes. The Galera replication protocol is nearly synchronous, which is a huge gain compared to regular MySQL replication. It performs transactions almost simultaneously on all the nodes, and the protocol ensures the same commit order. The transactions are almost synchronous because there are incoming queues on each node to improve performance. The presence of these incoming queues forces an extra step: the certification. The certification compares an incoming transaction with the ones already queued. If there a conflict, it returns a deadlock error.
For performance reasons, the certification process must be quick so that the incoming queue stays in memory. Since the number of transactions defines the size of the queue, the presence of large transactions uses a lot of memory. There are safeguards against memory overload, so be aware that transactions like:
|
1 |
update ATableWithMillionsRows set colA=1; |
will likely fail. That’s the first important limitation of a Galera-based cluster: the size of the number transactions is limited.
It is also critical to uniquely identify conflicting rows. The best way to achieve an efficient row comparison is to make sure all the tables have a primary key. In a Galera-based cluster, your tables need primary keys otherwise you’ll run into trouble. That’s the second limitation of a Galera based cluster: the need for primary keys. Personally, I think that a table should always have a primary key – but I have seen many oddities…
Another design characteristic is the need for an acknowledgment by all the nodes when a transaction commits. That means the network link with the largest latency between two nodes will set the floor value of the transactional latency. It is an important factor to consider when deploying a Galera-based cluster over a WAN. Similarly, an overloaded node can slow down the cluster if it cannot acknowledge the transaction in a timely manner. In most cases, adding slave threads will allow you to overcome the throughput limitations imposed by the network latency. Each transaction will suffer from latency, but more of them will be able to run at the same time and maintain the throughput.
The exception here is when there are “hot rows.” A hot row is a row that is hammered by updates all the time. The transactions affecting hot rows cannot be executed in parallel and are thus limited by the network latency.
Since Galera-based clusters are very popular, they must also have some good points. The first and most obvious is the full-durability support. Even if the node on which you executed a transaction crashes a fraction of second after the commit statement returned, the data is present on the other nodes incoming queues. In my opinion, it is the main reason for the demise of the share storage solution. Before Galera-based clusters, the shared storage solution was the only other solution guaranteeing no data loss in case of a crash.
While the standby node is unusable with the shared storage solution, all the nodes of a Galera-based cluster are available and are almost in sync. All the nodes can be used for reads without stressing too much about replication lag. If you accept a higher risk of deadlock errors, you can even write on all nodes.
Finally, and not the least, there is an automatic provisioning service for the new nodes called SST. During the SST process, a joiner node asks the cluster for a donor. One of the existing nodes agrees to be the donor and initiate a full backup. The backup is streamed over the network to the joiner and restored there. When the backup completes, the joiner performs an IST to get the recent updates and, once applied, joins the cluster. The most common SST method uses the Percona XtraBackup utility. When using SST for XtraBackup, the cluster is fully available during the SST, although it may degrade performance. This feature really simplifies the operational side of things.
The technology is very popular. Of course, I am a bit biased since I work for Percona and one of our flagship products is Percona XtraDB Cluster – an implementation of the Galera protocol. Other than standard MySQL replication, it is by far the most common HA solution used by the customers I work with.
The second “adult” MySQL high availability solution is RDS Aurora. I hesitated to add Aurora here, mainly because it is not an open-source technology. I must also admit that I haven’t followed the latest developments around Aurora very closely. So, let’s describe Aurora.
There are three major parts in Aurora: at least one database server, the writer node and the storage.
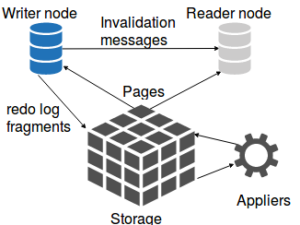
What makes Aurora special is the storage layer has its own processing logic. I don’t know if the processing logic is part of the writer node AWS instance or part of the storage service directly, since the source code is not available. Anyway, I’ll call that layer the appliers. The applier role is to apply redo log fragments that then allow the writer node to write only the redo log fragments (normally written to the InnoDB log files). The appliers read those fragments and modify the pages in the storage. If a node requests a page that has pending redo fragments to be applied, they get applied before returning the page.
From the writer node perspective, there are much fewer writes. There is also no direct upper bound in terms of a number of fragments to be queued, so it is a bit like having innodb_log_file_size set to an extremely large value. Also, since Aurora doesn’t need to flush pages, if the write node needs to read from the storage, and there are no free pages in the buffer pool, it can just discard one even if it is “dirty.” Actually, there are no dirty pages in the buffer pool.
So far, that seems to be very good for high write loads with spikes. What about the reader nodes? These reader nodes receive the updates from the writer nodes. If the update concerns a page they have in their buffer pool, they can modify it in place or discard it and read again from the storage. Again, without the source code, it is hard to tell the implementation. The point is, the readers have the same data as the master, they just can’t lag behind.
Apart from the impossibility of any reader lag, the other good point of Aurora is the storage. InnoDB pages are saved as objects in an object store, not like in a regular file on a file system. That means you don’t need to over-provision your storage ahead of time. You pay for what you are using – actually the maximum you ever use. InnoDB tablespaces do not shrink, even with Aurora.
Furthermore, if you have a 5TB dataset and your workload is such that you would need ten servers (one writer and nine readers), you still need only 5TB of storage if you are not replicating to other AZ. If we compare with regular MySQL and replication, you would have one master and nine slaves, each with 5TB of storage, for a total of 50TB. On top of that, you’ll have at least ten times the write IOPS.
So, storage wise, we have something that could be very interesting for applications with large datasets and highly concurrent read heavy workloads. You ensure high availability with the ability to promote a reader to writer automatically. You access the primary or the readers through endpoints that automatically connect to the correct instances. Finally, you can replicate the storage to multiple availability zones for DR.
Of course, such an architecture comes with a trade-off. If you experiment with Aurora, you’ll quickly discover that the smallest instance types underperform while the largest ones perform in a more expected manner. It is also quite easy to overload the appliers. Just perform the following queries:
|
1 2 |
update ATableWithMillionsRows set colA=1; select count(*) from ATableWithMillionsRows where colA=1; |
given that the table ATableWithMillionsRows is larger than the buffer pool. The select will hang for a long time because the appliers are overloaded by the number of pages to update.
In term of adoption, we have some customers at Percona using Aurora, but not that many. It could be that users of Aurora do not naturally go to Percona for services and support. I also wonder about the decision to keep the source code closed. It is certainly not a positive marketing factor in a community like the MySQL community. Since the Aurora technology seems extremely bounded to their ecosystem, is there really a risk for the technology to be reused by a competitor? With a better understanding of the technology through open access to the source, Amazon could have received valuable contributions. It would also be much easier to understand, tune and recommend Aurora.
Further reading:
Resources
RELATED POSTS





Hi Yves,
Thanks for the blog.
Couple of questions:
1. When the cluster is in Flow Control (FC) state, do you still think/count it as available please?
2. My experience told that heavy read/select (table is larger than buffer pool) initiated FC. It is not UPDATE which lock the cluster. What is your advice please?
Thanks
A cluster should never stay in FC for a long time, the pauses are short. Yes, it is considered online when doing FC.
The FC is triggered by the state of the incoming queue which contains only write events. As such, a 100% read load cannot trigger FC. You need some writes to have FC. Let’s suppose the load is 99% very IO intensive reads hitting a single node, then yes, the 1% writes maybe sufficient to trigger FC because the read load starves the write load of its IO.
Hello, thanks a lot! Extremely helpful information.
One, perhaps two questions, if you please: 😉
Is it possible to get stale reads in Galera? I mean, SQL select on data that is going to change by transaction(s) already certified but not yet applied.
If so, is there any plan to hold these reads until certified transactions are applied?
Sorry Ives, should have done some research berfore asking. I apologize.
https://www.percona.com/blog/2013/03/03/investigating-replication-latency-in-percona-xtradb-cluster/
-> wsrep_causal_reads
-> wsrep_sync_wait
New question though: do you have any recommended reading about wsrep_sync_wait , apart from the usual documentation ? 🙂
Another great article, thanks!
On your question regarding open sourcing the Aurora source code, my suspicion would be that they class it as their ‘secret sauce’ and wouldn’t want to give away that i.p. to competitors such as the Azure, Google and Oracle cloud platforms.
Hi Yves,
I think the links to Marco’s performance benchmarks are wrong, the first link is to the second performance page, the second link is to the Xtrabackup page. 🙂
Thanks Dave, should be fixed now.
‘@Edmar: Keep in mind that the lag is pretty small and linked to the size of the incoming queue. Also, if you write and then read from the same host, that’s fine. When that could be a problem is when you write to host A and then, right after, read from B expecting the write to be there. There is a cost to wsrep_sync_wait. If set to 1, all “Selects” will wait for the incoming queue to be fully processed before starting, even though it might not be related at all. The best would be to set the variable only at the session level for the cases that requires it. Value “2” (a bit of a bitmap) does the same for “Updates” and “Deletes”, value “4” for “Inserts” and “Replaces”. Using “7” forces nearly all queries to wait.
Hello,
I’m glad to read a wonderful information about HA.
I have translated your post to Japanese. If there are any problem, please tell me !
Best regard,