
In this blog post, we’ll look at some of the available PMP profiling tools.
While debugging or analyzing issues with Percona Server for MySQL, we often need a quick understanding of what’s happening on the server. Percona experts frequently use the pt-pmp tool from Percona Toolkit (inspired by http://poormansprofiler.org).
The pt-pmp tool collects application stack traces GDB and then post-processes them. From this you get a condensed, ordered list of the stack traces. The list helps you understand where the application spent most of the time: either running something or waiting for something.
Getting a profile with pt-pmp is handy, but it has a cost: it’s quite intrusive. In order to get stack traces, GDB has to attach to each thread of your application, which results in interruptions. Under high loads, these stops can be quite significant (up to 15-30-60 secs). This means that the pt-pmp approach is not really usable in production.
Below I’ll describe how to reduce GDB overhead, and also what other tools can be used instead of GDB to get stack traces.
|
1 2 3 4 5 6 |
# to check if index already exists: readelf -S | grep gdb_index # to generate index: gdb -batch mysqld -ex "save gdb-index /tmp" -ex "quit" # to embed index: objcopy --add-section .gdb_index=tmp/mysqld.gdb-index --set-section-flags .gdb_index=readonly mysqld mysqld |
Now let’s compare all the above profilers. We will measure the amount of time it needs to take all the stack traces from Percona Server for MySQL under a high load (sysbench OLTP_RW with 512 threads).
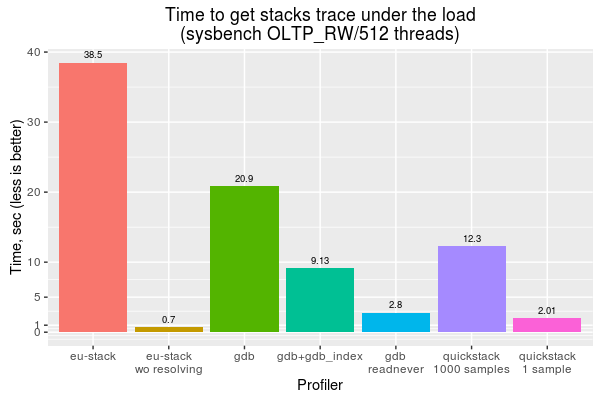
The results show that eu-stack (without resolving) got all stack traces in less than a second, and that Quickstack and GDB (with the readnever patch) got very close results. For other profilers, the time was around two to five times higher. This is quite unacceptable for profiling (especially in production).
There is one more note regarding the pt-pmp tool. The current version only supports GDB as the profiler. However, there is a development version of this tool that supports GDB, Quickstack, eu-stack and eu-stack with offline symbol resolving. It also allows you to look at stack traces for specific threads (tids). So for instance, in the case of Percona Server for MySQL, we can analyze just the purge, cleaner or IO threads.
Below are the command lines used in testing:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
# gdb & gdb+gdb_index time gdb -ex "set pagination 0" -ex "thread apply all bt" -batch -p `pidof mysqld` > /dev/null # gdb+readnever time gdb --readnever -ex "set pagination 0" -ex "thread apply all bt" -batch -p `pidof mysqld` > /dev/null # eu-stack time eu-stack -s -m -p `pidof mysqld` > /dev/null # eu-stack without resolving time eu-stack -q -p `pidof mysqld` > /dev/null # quickstack - 1 sample time quickstack -c 1 -p `pidof mysqld` > /dev/null # quickstack - 1000 samples time quickstack -c 1000 -p `pidof mysqld` > /dev/null |
Resources
RELATED POSTS





Very interesting Alexey, thanks! Since you ran the tests while using sysbench, can you show the results of how tps was affected while pmp ran?
Just a shout out for https://github.com/knielsen/knielsen-pmp which uses libunwind and is fast
https://jira.mariadb.org/browse/MDEV-163
https://www.percona.com/blog/2011/12/02/three-ways-that-the-poor-mans-profiler-can-hurt-mysql/#comment-850534
Peter,
We know about https://github.com/knielsen/knielsen-pmp , but it was not updated for 5 years, it is very hard to get it compiled in modern environments, that’s why we do not put it into recommended list.
Thanks for the explanation Vadim,
I just use get_stacktrace from knielsen-pmp, and on RHEL6 and RHEL7 it compiles with:
> make get_stacktrace
g++ -g -O3 -fomit-frame-pointer -o get_stacktrace get_stacktrace.cc -Llib -lunwind-ptrace -lunwind-generic -lrt
For quickstack, with cmake > 3.1 or higher, it builds on RHEL7 but on RHEL6 the default gcc is 4.4.7 which does not support nullptr, using a workaround from http://stackoverflow.com/a/2419885/2766246 , and then 3 casts for “overloaded ‘to_string(const int&)’ is ambiguous” errors do get it to build on EL6.
So for me (on RHEL 6 and 7), knielsen-pmp was easier to compile than quickstack.
Alexey,
I wonder if time it takes to take stack traces is the most important measure of the overhead. I would assume the “stall” – the maximum time the MySQL (or other process) get blocked from serving traffic would be more critical ?