
For this blog post, I’ve decided to try ClickHouse: an open source column-oriented database management system developed by Yandex (it currently powers Yandex.Metrica, the world’s second-largest web analytics platform).
In my previous set of posts, I tested Apache Spark for big data analysis and used Wikipedia page statistics as a data source. I’ve used the same data as in the Apache Spark blog post: Wikipedia Page Counts. This allows me to compare ClickHouse’s performance to Spark’s.

I’ve spent some time testing ClickHouse for relatively large volumes of data (1.2Tb uncompressed). Here is a list of ClickHouse advantages and disadvantages that I saw:
 ClickHouse advantages
ClickHouse advantages
Here is a full list of ClickHouse features
ClickHouse disadvantages
Full list of ClickHouse limitations
Running out of memory is one of the potential problems you may encounter when working with large datasets in ClickHouse:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
SELECT min(toMonth(date)), max(toMonth(date)), path, count(*), sum(hits), sum(hits) / count(*) AS hit_ratio FROM wikistat WHERE (project = 'en') GROUP BY path ORDER BY hit_ratio DESC LIMIT 10 ↖ Progress: 1.83 billion rows, 85.31 GB (68.80 million rows/s., 3.21 GB/s.) ██████████▋ 6%Received exception from server: Code: 241. DB::Exception: Received from localhost:9000, 127.0.0.1. DB::Exception: Memory limit (for query) exceeded: would use 9.31 GiB (attempt to allocate chunk of 1048576 bytes), maximum: 9.31 GiB: (while reading column hits): |
By default, ClickHouse limits the amount of memory for group by (it uses a hash table for group by). This is easily fixed – if you have free memory, increase this parameter:
|
1 |
SET max_memory_usage = 128000000000; #128G |
If you don’t have that much memory available, ClickHouse can “spill” data to disk by setting this:
|
1 2 |
set max_bytes_before_external_group_by=20000000000; #20G set max_memory_usage=40000000000; #40G |
According to the documentation, if you need to use max_bytes_before_external_group_by it is recommended to set max_memory_usage to be ~2x of the size of max_bytes_before_external_group_by.
(The reason for this is that the aggregation is performed in two phases: (1) reading and building an intermediate data, and (2) merging the intermediate data. The spill to disk can only happen during the first phase. If there won’t be spill, ClickHouse might need the same amount of RAM for stage 1 and 2.)
Both ClickHouse and Spark can be distributed. However, for the purpose of this test I’ve run a single node for both ClickHouse and Spark. The results are quite impressive.
Benchmark summary
| Size / compression | Spark v. 2.0.2 | ClickHouse |
| Data storage format | Parquet, compressed: snappy | Internal storage, compressed |
| Size (uncompressed: 1.2TB) | 395G | 212G |
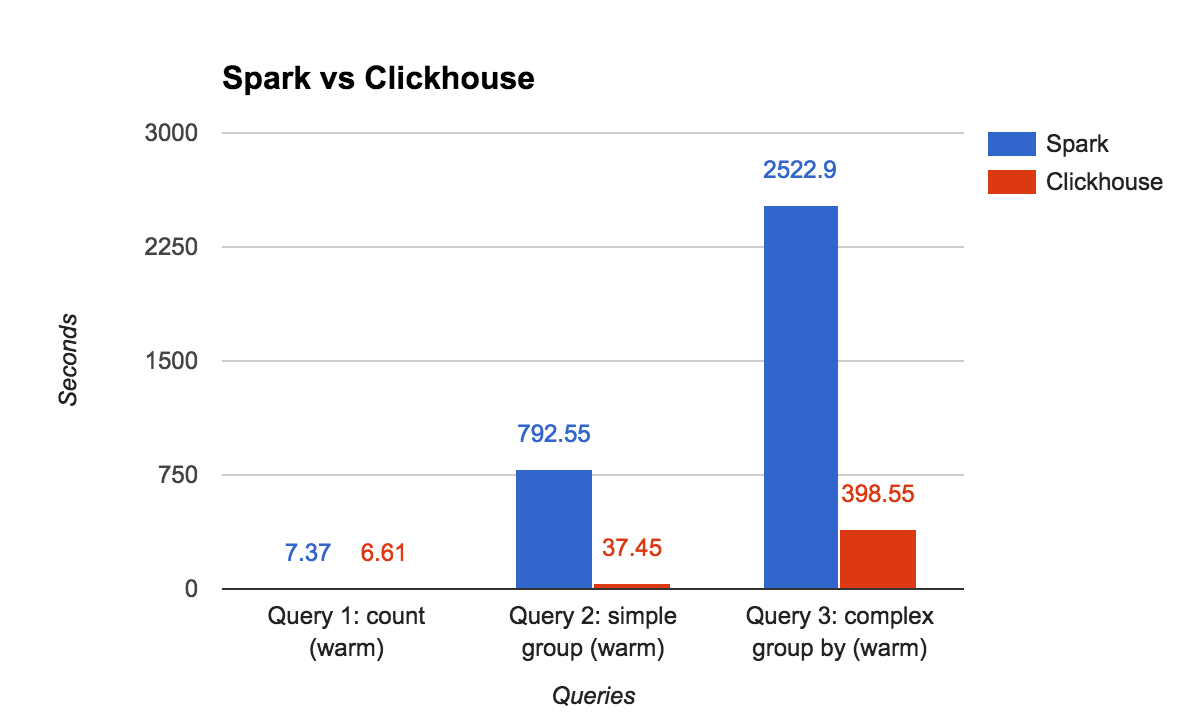
| Test | Spark v. 2.0.2 | ClickHouse | Diff |
| Query 1: count (warm) | 7.37 sec (no disk IO) | 6.61 sec | ~same |
| Query 2: simple group (warm) | 792.55 sec (no disk IO) | 37.45 sec | 21x better |
| Query 3: complex group by | 2522.9 sec | 398.55 sec | 6.3x better |
I wanted to see how ClickHouse compared to MySQL. Obviously, we can’t compare some workloads. For example:
Usually big data systems provide us with real-time queries. Systems based on map/reduce (i.e., Hive on top of HDFS) are just too slow for real-time queries, as it takes a long time to initialize the map/reduce job and send the code to all nodes.
Potentially, you can use ClickHouse for real-time queries. It does not support secondary indexes, however. This means it will probably scan lots of rows, but it can do it very quickly.
To do this test, I’m using the data from the Percona Monitoring and Management system. The table I’m using has 150 columns, so it is good for column storage. The size in MySQL is ~250G:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
mysql> show table status like 'query_class_metrics'G *************************** 1. row *************************** Name: query_class_metrics Engine: InnoDB Version: 10 Row_format: Compact Rows: 364184844 Avg_row_length: 599 Data_length: 218191888384 Max_data_length: 0 Index_length: 18590056448 Data_free: 6291456 Auto_increment: 416994305 |
Scanning the whole table is significantly faster in ClickHouse. Retrieving just ten rows by key is faster in MySQL (especially from memory).
But what if we only need to scan limited amount of rows and do a group by? In this case, ClickHouse may be faster. Here is the example (real query used to create sparklines):
MySQL
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
SELECT (1480888800 - UNIX_TIMESTAMP(start_ts)) / 11520 as point, FROM_UNIXTIME(1480888800 - (SELECT point) * 11520) AS ts, COALESCE(SUM(query_count), 0) / 11520 AS query_count_per_sec, COALESCE(SUM(Query_time_sum), 0) / 11520 AS query_time_sum_per_sec, COALESCE(SUM(Lock_time_sum), 0) / 11520 AS lock_time_sum_per_sec, COALESCE(SUM(Rows_sent_sum), 0) / 11520 AS rows_sent_sum_per_sec, COALESCE(SUM(Rows_examined_sum), 0) / 11520 AS rows_examined_sum_per_sec FROM query_class_metrics WHERE query_class_id = 7 AND instance_id = 1259 AND (start_ts >= '2014-11-27 00:00:00' AND start_ts < '2014-12-05 00:00:00') GROUP BY point; ... 61 rows in set (0.10 sec) # Query_time: 0.101203 Lock_time: 0.000407 Rows_sent: 61 Rows_examined: 11639 Rows_affected: 0 explain SELECT ... *************************** 1. row *************************** id: 1 select_type: PRIMARY table: query_class_metrics partitions: NULL type: range possible_keys: agent_class_ts,agent_ts key: agent_class_ts key_len: 12 ref: NULL rows: 21686 filtered: 100.00 Extra: Using index condition; Using temporary; Using filesort *************************** 2. row *************************** id: 2 select_type: DEPENDENT SUBQUERY table: NULL partitions: NULL type: NULL possible_keys: NULL key: NULL key_len: NULL ref: NULL rows: NULL filtered: NULL Extra: No tables used 2 rows in set, 2 warnings (0.00 sec) |
It is relatively fast.
ClickHouse (some functions are different, so we will have to rewrite the query):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
SELECT intDiv(1480888800 - toRelativeSecondNum(start_ts), 11520) AS point, toDateTime(1480888800 - (point * 11520)) AS ts, SUM(query_count) / 11520 AS query_count_per_sec, SUM(Query_time_sum) / 11520 AS query_time_sum_per_sec, SUM(Lock_time_sum) / 11520 AS lock_time_sum_per_sec, SUM(Rows_sent_sum) / 11520 AS rows_sent_sum_per_sec, SUM(Rows_examined_sum) / 11520 AS rows_examined_sum_per_sec, SUM(Rows_affected_sum) / 11520 AS rows_affected_sum_per_sec FROM query_class_metrics WHERE (query_class_id = 7) AND (instance_id = 1259) AND ((start_ts >= '2014-11-27 00:00:00') AND (start_ts < '2014-12-05 00:00:00')) GROUP BY point; 61 rows in set. Elapsed: 0.017 sec. Processed 270.34 thousand rows, 14.06 MB (15.73 million rows/s., 817.98 MB/s.) |
As we can see, even though ClickHouse scans more rows (270K vs. 11K – over 20x more) it is faster to execute the ClickHouse query (0.10 seconds in MySQL compared to 0.01 second in ClickHouse). The column store format helps a lot here, as MySQL has to read all 150 columns (stored inside InnoDB pages) and ClickHouse only needs to read seven columns.
Wikipedia trending article of the month
Inspired by the article about finding trending topics using Google Books n-grams data, I decided to implement the same algorithm on top of the Wikipedia page visit statistics data. My goal here is to find the “article trending this month,” which has significantly more visits this month compared to the previous month. As I was implementing the algorithm, I came across another ClickHouse limitation: join syntax is limited. In ClickHouse, you can only do join with the “using” keyword. This means that the fields you’re joining need to have the same name. If the field name is different, we have to use a subquery.
Below is an example.
First, create a temporary table to aggregate the visits per month per page:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
CREATE TABLE wikistat_by_month ENGINE = Memory AS SELECT path, mon, sum(hits) / total_hits AS ratio FROM ( SELECT path, hits, toMonth(date) AS mon FROM wikistat WHERE (project = 'en') AND (lower(path) NOT LIKE '%special%') AND (lower(path) NOT LIKE '%page%') AND (lower(path) NOT LIKE '%test%') AND (lower(path) NOT LIKE '%wiki%') AND (lower(path) NOT LIKE '%index.html%') ) AS a ANY INNER JOIN ( SELECT toMonth(date) AS mon, sum(hits) AS total_hits FROM wikistat WHERE (project = 'en') AND (lower(path) NOT LIKE '%special%') AND (lower(path) NOT LIKE '%page%') AND (lower(path) NOT LIKE '%test%') AND (lower(path) NOT LIKE '%wiki%') AND (lower(path) NOT LIKE '%index.html%') GROUP BY toMonth(date) ) AS b USING (mon) GROUP BY path, mon, total_hits ORDER BY ratio DESC Ok. 0 rows in set. Elapsed: 543.607 sec. Processed 53.77 billion rows, 2.57 TB (98.91 million rows/s., 4.73 GB/s.) |
Second, calculate the actual list:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 |
SELECT path, mon + 1, a_ratio AS ratio, a_ratio / b_ratio AS increase FROM ( SELECT path, mon, ratio AS a_ratio FROM wikistat_by_month WHERE ratio > 0.0001 ) AS a ALL INNER JOIN ( SELECT path, CAST((mon - 1) AS UInt8) AS mon, ratio AS b_ratio FROM wikistat_by_month WHERE ratio > 0.0001 ) AS b USING (path, mon) WHERE (mon > 0) AND (increase > 2) ORDER BY mon ASC, increase DESC LIMIT 100 ┌─path───────────────────────────────────────────────┬─plus(mon, 1)─┬──────────────────ratio─┬───────────increase─┐ │ Heath_Ledger │ 2 │ 0.0008467223172121601 │ 6.853825241458039 │ │ Cloverfield │ 2 │ 0.0009372609760313347 │ 3.758937474560766 │ │ The_Dark_Knight_(film) │ 2 │ 0.0003508532447770276 │ 2.8858100355450484 │ │ Scientology │ 2 │ 0.0003300109101992719 │ 2.52497180013816 │ │ Barack_Obama │ 3 │ 0.0005786473399980557 │ 2.323409928527576 │ │ Canine_reproduction │ 3 │ 0.0004836300843539438 │ 2.0058985801174662 │ │ Iron_Man │ 6 │ 0.00036261003907049 │ 3.5301196568303888 │ │ Iron_Man_(film) │ 6 │ 0.00035634745198422497 │ 3.3815325090507193 │ │ Grand_Theft_Auto_IV │ 6 │ 0.0004036713142943461 │ 3.2112732008504885 │ │ Indiana_Jones_and_the_Kingdom_of_the_Crystal_Skull │ 6 │ 0.0002856570195547951 │ 2.683443198030021 │ │ Tha_Carter_III │ 7 │ 0.00033954377342889735 │ 2.820114216429247 │ │ EBay │ 7 │ 0.0006575000133427979 │ 2.5483158977946787 │ │ Bebo │ 7 │ 0.0003958340022793501 │ 2.3260912792668162 │ │ Facebook │ 7 │ 0.001683658379576915 │ 2.16460972864883 │ │ Yahoo!_Mail │ 7 │ 0.0002190640575012259 │ 2.1075879062784737 │ │ MySpace │ 7 │ 0.001395608643577507 │ 2.103263660621813 │ │ Gmail │ 7 │ 0.0005449834079575953 │ 2.0675919337716757 │ │ Hotmail │ 7 │ 0.0009126863121737026 │ 2.052471735190232 │ │ Google │ 7 │ 0.000601645849087389 │ 2.0155448612416644 │ │ Barack_Obama │ 7 │ 0.00027336526076130943 │ 2.0031305241832302 │ │ Facebook │ 8 │ 0.0007778115183044431 │ 2.543477658022576 │ │ MySpace │ 8 │ 0.000663544314346641 │ 2.534512981232934 │ │ Two-Face │ 8 │ 0.00026975137404447024 │ 2.4171743959768803 │ │ YouTube │ 8 │ 0.001482456447101451 │ 2.3884527929836152 │ │ Hotmail │ 8 │ 0.00044467667764940547 │ 2.2265750216262954 │ │ The_Dark_Knight_(film) │ 8 │ 0.0010482536106662156 │ 2.190078096294301 │ │ Google │ 8 │ 0.0002985028319919154 │ 2.0028812075734637 │ │ Joe_Biden │ 9 │ 0.00045067411455437264 │ 2.692262662620829 │ │ The_Dark_Knight_(film) │ 9 │ 0.00047863754833213585 │ 2.420864550676665 │ │ Sarah_Palin │ 10 │ 0.0012459220318907518 │ 2.607063205782761 │ │ Barack_Obama │ 12 │ 0.0034487235202817087 │ 15.615409029600414 │ │ George_W._Bush │ 12 │ 0.00042708730873936023 │ 3.6303098900144937 │ │ Fallout_3 │ 12 │ 0.0003568429236849597 │ 2.6193094036745155 │ └────────────────────────────────────────────────────┴──────────────┴────────────────────────┴────────────────────┘ 34 rows in set. Elapsed: 1.062 sec. Processed 1.22 billion rows, 49.03 GB (1.14 billion rows/s., 46.16 GB/s.) |
Their response time is really good, considering the amount of data it needed to scan (the first query scanned 2.57 TB of data).
The ClickHouse column-oriented database looks promising for data analytics, as well as for storing and processing structural event data and time series data. ClickHouse can be ~10x faster than Spark for some workloads.
Hardware
Query 1
|
1 |
select count(*) from wikistat |
ClickHouse:
|
1 2 3 4 5 6 7 8 9 10 |
:) select count(*) from wikistat; SELECT count(*) FROM wikistat ┌─────count()─┐ │ 26935251789 │ └─────────────┘ 1 rows in set. Elapsed: 6.610 sec. Processed 26.88 billion rows, 53.77 GB (4.07 billion rows/s., 8.13 GB/s.) |
Spark:
|
1 2 3 |
spark-sql> select count(*) from wikistat; 26935251789 Time taken: 7.369 seconds, Fetched 1 row(s) |
Query 2
|
1 2 3 4 5 |
select count(*), month(dt) as mon from wikistat where year(dt)=2008 and month(dt) between 1 and 10 group by month(dt) order by month(dt); |
ClickHouse:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
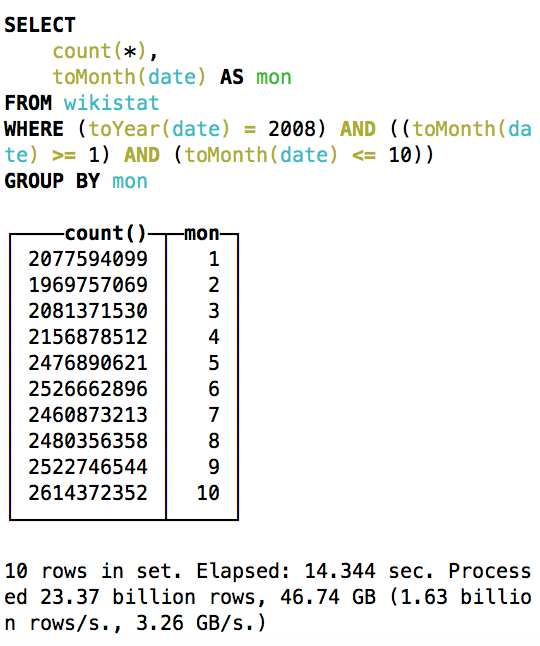
:) select count(*), toMonth(date) as mon from wikistat where toYear(date)=2008 and toMonth(date) between 1 and 10 group by mon; SELECT count(*), toMonth(date) AS mon FROM wikistat WHERE (toYear(date) = 2008) AND ((toMonth(date) >= 1) AND (toMonth(date) <= 10)) GROUP BY mon ┌────count()─┬─mon─┐ │ 2100162604 │ 1 │ │ 1969757069 │ 2 │ │ 2081371530 │ 3 │ │ 2156878512 │ 4 │ │ 2476890621 │ 5 │ │ 2526662896 │ 6 │ │ 2489723244 │ 7 │ │ 2480356358 │ 8 │ │ 2522746544 │ 9 │ │ 2614372352 │ 10 │ └────────────┴─────┘ 10 rows in set. Elapsed: 37.450 sec. Processed 23.37 billion rows, 46.74 GB (623.97 million rows/s., 1.25 GB/s.) |
Spark:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
spark-sql> select count(*), month(dt) as mon from wikistat where year(dt)=2008 and month(dt) between 1 and 10 group by month(dt) order by month(dt); 2100162604 1 1969757069 2 2081371530 3 2156878512 4 2476890621 5 2526662896 6 2489723244 7 2480356358 8 2522746544 9 2614372352 10 Time taken: 792.552 seconds, Fetched 10 row(s) |
Query 3
|
1 2 3 4 5 6 7 8 9 10 |
SELECT path, count(*), sum(hits) AS sum_hits, round(sum(hits) / count(*), 2) AS hit_ratio FROM wikistat WHERE project = 'en' GROUP BY path ORDER BY sum_hits DESC LIMIT 100; |
ClickHouse:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
:) SELECT :-] path, :-] count(*), :-] sum(hits) AS sum_hits, :-] round(sum(hits) / count(*), 2) AS hit_ratio :-] FROM wikistat :-] WHERE (project = 'en') :-] GROUP BY path :-] ORDER BY sum_hits DESC :-] LIMIT 100; SELECT path, count(*), sum(hits) AS sum_hits, round(sum(hits) / count(*), 2) AS hit_ratio FROM wikistat WHERE project = 'en' GROUP BY path ORDER BY sum_hits DESC LIMIT 100 ┌─path────────────────────────────────────────────────┬─count()─┬───sum_hits─┬─hit_ratio─┐ │ Special:Search │ 44795 │ 4544605711 │ 101453.41 │ │ Main_Page │ 31930 │ 2115896977 │ 66266.74 │ │ Special:Random │ 30159 │ 533830534 │ 17700.54 │ │ Wiki │ 10237 │ 40488416 │ 3955.11 │ │ Special:Watchlist │ 38206 │ 37200069 │ 973.67 │ │ YouTube │ 9960 │ 34349804 │ 3448.78 │ │ Special:Randompage │ 8085 │ 28959624 │ 3581.9 │ │ Special:AutoLogin │ 34413 │ 24436845 │ 710.11 │ │ Facebook │ 7153 │ 18263353 │ 2553.24 │ │ Wikipedia │ 23732 │ 17848385 │ 752.08 │ │ Barack_Obama │ 13832 │ 16965775 │ 1226.56 │ │ index.html │ 6658 │ 16921583 │ 2541.54 │ … 100 rows in set. Elapsed: 398.550 sec. Processed 26.88 billion rows, 1.24 TB (67.45 million rows/s., 3.10 GB/s.) |
Spark:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
spark-sql> SELECT > path, > count(*), > sum(hits) AS sum_hits, > round(sum(hits) / count(*), 2) AS hit_ratio > FROM wikistat > WHERE (project = 'en') > GROUP BY path > ORDER BY sum_hits DESC > LIMIT 100; ... Time taken: 2522.903 seconds, Fetched 100 row(s) |
Resources
RELATED POSTS





Where’s ‘Like’ button ? 🙂 I like your posting.
Would be nice to see the comparison with MariaDB ColumnStore.
I’m working on it right now, will be published shortly
It is on the left side of the screen. Feel free not only like but also share on Facebook LinkedIn or Twitter 🙂
It would be nice to compare ClickHouseDB with MariaDB ColumnStore.
It could be useful not just compare the performance, but also ease of installation,
data loading and resources consumption.
Hi Alexander, what was the spec of the equipment you used to run your benchmarks?
Sorry! ignore the request, now that my eyes are working properly I found the specs.
A few followup blog posts
https://www.percona.com/blog/2017/03/17/column-store-database-benchmarks-mariadb-columnstore-vs-clickhouse-vs-apache-spark/
https://www.percona.com/blog/2017/06/22/clickhouse-general-analytical-workload-based-star-schema-benchmark/
https://www.percona.com/blog/2017/07/06/clickhouse-one-year/