
We recently looked at how various open-source database engines maintain their secondary indexes (in a previous analysis) and found significant differences. The maintenance of indexes is not the only aspect where storage engines differ, another significant difference is how they handle simple row updates. These updates highlight how these open-source databases organize data and manage the versions of records while processing transactions. The management of versions is called MVCC, which stands for Multi-version Concurrency Control. In this post, we’ll examine one aspect of open-source database engines: how IO-efficient they are for simple updates.
While performing updates, storage engines require access to storage for multiple reasons. Obviously, in order to update a record, it must be read from storage and, eventually, it will need to be written back. The storage engines also have to manage the record versions which, depending on the MVCC implementation, may require additional IOPs. All storage engines also use operational journal to sequentially log their operation for recovery purpose. These journals are called redo or WAL and are normally only written to. Finally, there must be crash protections against partial writes which could cause data corruption. Such protections also normally only consist of writes.
For this post, we’ll conduct an experiment using the dataset created during the previous post and update an unindexed column from 100k randomly chosen rows. In order to see the impacts of data reorganization, we’ll run updates to the same set of rows a second time. In both cases, we’ll examine the total number of required IOPs, limited to a size of 16KB.
Since the MVCC implementations are less known, let’s first examine what exactly their responsibilities are. MVCC is required only when there is significant concurrency for access and manipulation of data. At low concurrency, locking is simpler and often preferred. A good example of this is MySQL’s MyISAM engine, where any attempt to write to a table results in a full table lock. At higher concurrency, many sessions have queries running simultaneously. MVCC manages the record versions and determines which version a given transaction can see and update.
IO-wise, the aspects of MVCC that concern us relate to the handling and storage of the record versions. These versions are organized into lists and sorted by age. From a base record, there are two possible approaches for these lists: from oldest to newest (O2N) or from newest to oldest (N2O). Most storage engines use the N2O approach, with PostgreSQL being a notable exception, using mostly an O2N approach. Let’s discuss in more detail examples of these two implementations.
As mentioned above, PostgreSQL uses mostly an oldest to newest (O2N) approach. When a row is updated, the whole row is copied to a new position, and only the version pointer (CTID) is updated in the original row. The old version will eventually be removed by the vacuum process. In a sense, an update in PostgreSQL is essentially an INSERT followed by an eventual DELETE. When a row needs to be accessed without an index, the oldest version is accessed and then the versions are iterated until the version compatible with the current transaction number is found. This means heavily updated rows could have a long list of versions and be slower to access. At some point, though, the vacuum process will kick in and shrink the list, removing the irrelevant versions.
PostgreSQL uses physical positions of rows (CTID) as pointers for indexes. After an update to a non-indexed column, the original index record points to the oldest version. An additional index entry is added if the updated row have been written a new page. The PostgreSQL behavior with row versions is quite complex, it is likely there are aspects I don’t fully grasp. If someone wants to experiment and dig further on this topic, I recommend the pageinspect extension, it is really awesome. Eventually, IOPs will be needed during vacuum to remove the old versions.
For more information on this topic, the following link is a good starting point on PostgreSQL MVCC implementation. We must also keep on our radar a project developing a new MVCC implementation called Orioledb but so far, it has a low adoption rate.
InnoDB is a fairly typical implementation of the newest-to-oldest (N2O) approach. For simplicity, we’ll restrict ourselves to updates. When a transaction updates a row, the row diff (or delta) is copied to the undo space. Then, the row is edited, and as part of the process, the field DB_ROLL_PTR is set to point to the undo position of the row diff. Finally, the field DB_TRX_ID is set to the ID of the transaction modifying the row. When another transaction attempts to read the same row, if its transaction ID is smaller than the recorded DB_TRX_ID, the DB_ROLL_PTR points to the previous version of the row.
When no running transaction needs an undo entry, the purge process removes it. That means for short transactions, the undo space lives in memory and is only persisted by the redo log. This removes a significant amount of IOPs. Also, the secondary indexes are not impacted because they use logical pointers, the primary key. For more information on InnoDB MVCC, see this excellent article.
The starting point of this experiment is the dataset at the end of our previous experiment, centered on the maintenance of secondary indexes. These datasets have 10 million rows in a table with 7 indexes, one primary on an integer and 6 on large varchar UUID values. From that dataset, 100k rows were randomly selected for an update on the unindexed column, status. The updates were executed twice to illustrate the reorganization of data caused by the MVCC implementations. The best way to illustrate the impacts is to report the total number of IOPs (read and writes) to/from storage. For consistency, IOP sizes are limited to 16KB. The results are shown below:
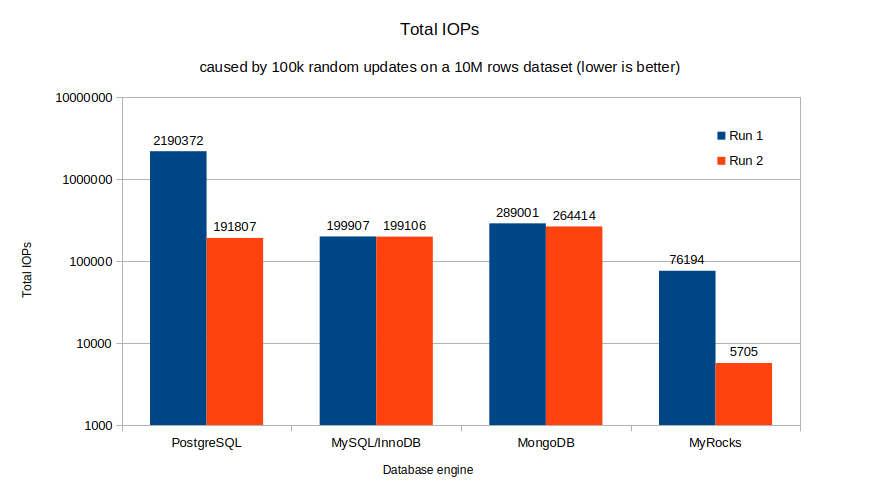
It is important to note the logarithmic scale used for Total IOPs. The large variation in IOPs imposed that choice of scale for readability.
The “Run 1” of PostgreSQL illustrates the issues with its MVCC implementation. It is actually worse than I expected. This first set of updates required, on average, nearly 22 IOPs per update. A significant amount of these IOPs are caused by Full Page Writes (FPW). FPW occurs the first time a page is modified after a checkpoint. It is there to protect against torn pages, serving the same purpose as the InnoDB doublewrite buffer with MySQL.
Since PostgreSQL MVCC copies updated rows to new pages (which are append-only), this has the benefit of grouping the active rows. In our experiment, the updated rows, about 1% of all the rows, end up grouped together in a limited number of database pages. Because of this, the “Run 2” required less than 1/10th of the IOPs of “Run 1”. It is important to highlight the importance of this behavior as nearly all database workloads present a small subset of very active rows. While PostgreSQL old MVCC implementation bears a very high cost for the initial run, it kind of self-tunes for a much better “Run 2”.
InnoDB results are better in terms of IOPs and feature-less, both runs are within a few hundred IOPs of each other. This is a testimony to its younger MVCC design. The actual number of IOPs required is just a few percent above the second run of PostgreSQL. This means, while its behavior is excellent, performance will not improve over time with a small set of active rows.
MongoDB WiredTiger engine required about 33% more IOPs than InnoDB in our experiment. Because of the way MongoDB evaluates updates, the actual value of the status had to be modified between the update runs, otherwise the second update would have been a no-op. The second run required about 8% less IOPs than the first one.
RocksDB is optimized for writes, and it shows. MyRocks demonstrates a significant advantage over other engines. It required about 1/3rd of the IOPs of the second contender (InnoDB) for “Run 1” and, amazingly, only 1/30th of PostgreSQL (2nd best) for “Run 2”. Clearly, if your workload is dominated by writes, and you can cope with slightly slower reads, you should take a look at MyRocks.
This database experiment sheds some light on the various Multi-version concurrency control implementations of popular database engines. We have observed large variations in the number of required IOPs between engines for similar workloads.
Here are some key points to remember:




