
In this blog, we’ll use some test results to look at the rationale for using provisioned IOPS volumes for AWS databases.
One piece of advice you often hear running MySQL, MongoDB or other databases in the AWS EC2 environment is that you should use volumes with provisioned IOPs. This kind of makes sense on the “marketing” level, where provisioned IOPS (io1) volumes are designed for IO-intensive database workloads, while General Purpose (gp2) volumes are not. But if you go to the AWS volume type description, you will find that gp2s are shown to have pretty good IO performance. So where do all these supposed database performance problems for Amazon Elastic Block Store (EBS), with no provisioned IOs, come from?
Here is what I found out running experiments with a beta of Percona Monitoring and Management.
I ran a typical database instance workload, where the OLTP workload uses around 20% of the system capacity, and periodically I have a single user IO intensive batch job hitting the same system. Even if you do not have batch jobs running, your backup is likely to show this same IO pattern.
What would happen in this case if you have conventional local storage? Some queueing happens on the storage level, but as there is only one user with intensive IO, the impact is typically not very significant. What do we see from the AWS gp2 volume?
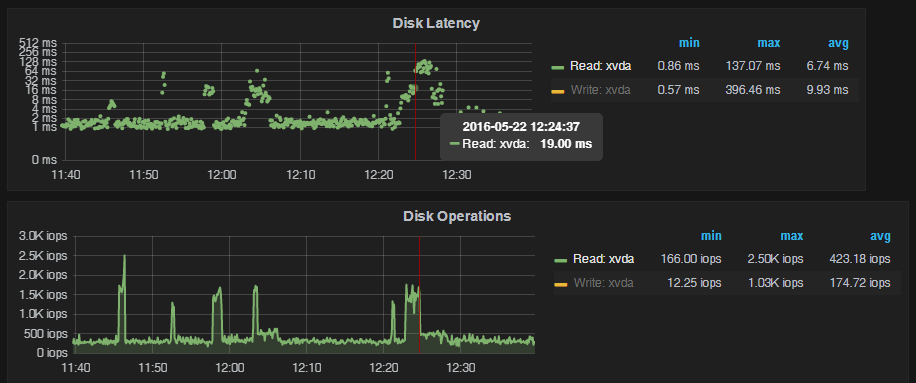
At first, the read services spike to more than 1.5K IOPS, and while latency increases from normal 1-2ms, it remains below 10ms on average. However, after a couple of minutes, IOPS drops to around 500, and read latency spikes to over 100ms (note the log scale on the graph).
What is happening here? The gp2 volumes behave differently than your conventional storage by allowing IO bursts for short periods of time – after a short period of time, however, the IOs are throttled (in this case to only 500/sec). How does throttling work? By adding delay to IO completion so that only the required IOs are completed per second, and the more concurrency we add to such throttled devices, the higher the average IO response latency is!
What does this mean from an application point of view? Let’s say you have a database transaction that requires 100 reads from the disk. If you have an average of 1ms latency, this transaction takes about 100ms reading from the disk, and will likely be seen as very good user experience. If you have an average IO latency of 100ms, the same transaction spends ten seconds reading from the disk – well above the tolerance for many users.
As a DBA, you can see how putting an extra (small) load on the database system (such as running batch job or backup) can cause your boss to come screaming that the website is down ten minutes later.
There is another key difference between conventional local storage such as RAID or SSD and an EBS volume. Not all local storage IO is created equal, while an EBS general-purpose volume seems to inject latencies into IO operations independent of what the IO is.
Transactional log flushes are one of the most latency-critical IO operations databases perform. These are very small (often just 1 page) sequential writes. RAID controllers and SSDs can handle these very quickly by only writing in memory (battery or capacitor backed up), at a fraction of the costs of other operations. This is not the case for EBS gp2: log writes come with high latency.
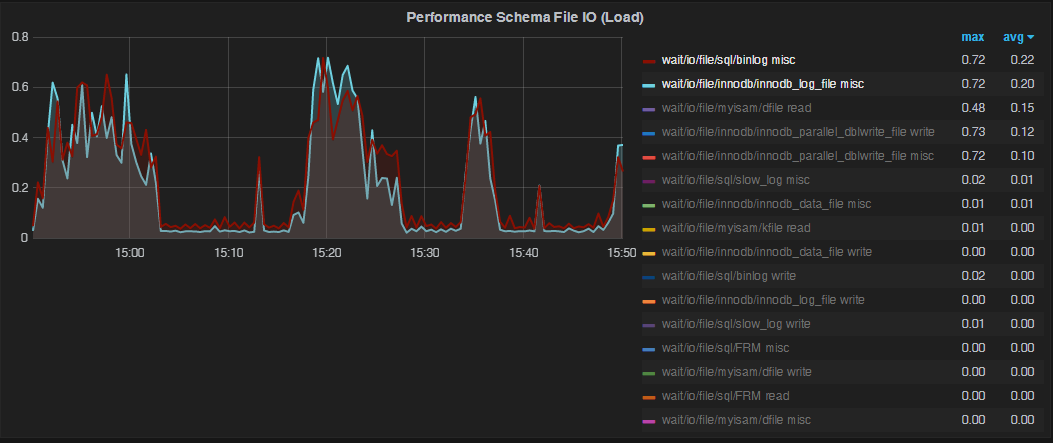
We can see this latency in Performance Schema graphs, where such patch jobs correlate to a huge amount of time spent writing to the InnoDB Transactional Log file or Binary Log File:
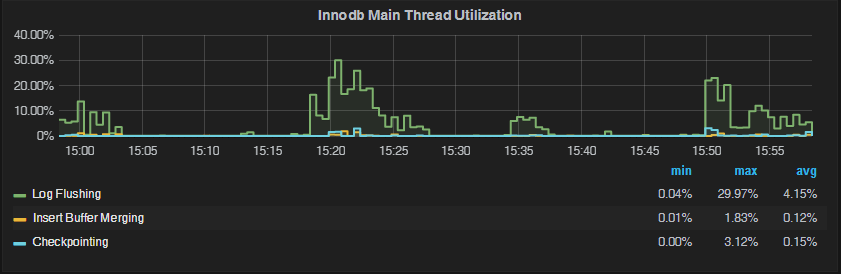
We can also see the main InnoDB thread spending up to 30% of its time flushing the log – the number is drastically lower for typical storage configuration:
Another way AWS EBS storage is different from the typical local storage is that size directly buys you performance. GP2 volumes provide 3 IOPS/GB, up to 10000 IOPS (99 percentile figure), which means that larger storage will have higher performance – though if anything, this means you’re getting better performance from your larger production volumes than your smaller test ones.
A final note: EBS storage is essentially connected to a network, which means both slightly higher latencies and limited throughput. According to the documentation, there is 160MiB/s throughput limit per volume, which is a lot less than even inexpensive SATA SSD. SSD often can provide 500MB/sec or more, and are generally limited by SATA bus capacity.
My takeaways from these results:
Want to play around with live graphs? Check out our PMM Demo, which is currently running the stated workload on Amazon EC2. You can also install the beta version to use with your own system.





hi peter, the site http://pmmdemo.percona.com/ is not working.
Hi Peter,
Very informative graphs and analysis!
As you mentioned, the key point with EBS is that performance is dependent on storage size. With 1TB+ for instance, baseline IOPS is greater than burst IOPS, so you won’t see the behavior you describe in the post.
Also provisioned IOPS vs gp2 is not the only option: you may want to over-provision your gp2 volumes to have a better baseline performance. Say you need 200GB of storage and 1500 IOPS, a 500GB gp2 volume will be cheaper (and throughput will be similar for 16KB operations). And of course, i2 instances can also be a good choice, but it’s another story because they don’t use EBS.
To add to details provided by Stephane, the IOPS in AWS also depends on instance type as there is a instance wise limit on the number of IOPS and whether the instance is set to “EBS Optimized”
Neo, Stephane you’re absolutely right on the both counts. My point is not the number of IOs you can get from non provisional volume which indeed can be very high but the fact allowed burst + extensive throttling gives very different profile compared to the storage found outside of Cloud environment.