
 In a recent post, Vadim compared the performance of Amazon Aurora and Percona Server on AWS. This time, I am comparing write throughput for InnoDB and TokuDB, using the same workload (sysbench oltp/update/update_non_index) and a similar set-up (r3.xlarge instance, with general purpose ssd, io2000 and io3000 volumes) to his experiments.
In a recent post, Vadim compared the performance of Amazon Aurora and Percona Server on AWS. This time, I am comparing write throughput for InnoDB and TokuDB, using the same workload (sysbench oltp/update/update_non_index) and a similar set-up (r3.xlarge instance, with general purpose ssd, io2000 and io3000 volumes) to his experiments.
All the runs used 16 threads for sysbench, and the following MySQL configuration files for InnoDB and TokuDB respectively:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
[mysqld] table-open-cache-instances=32 table_open_cache=8000 innodb-flush-method = O_DIRECT innodb-log-files-in-group = 2 innodb-log-file-size = 16G innodb-flush-log-at-trx-commit = 1 innodb_log_compressed_pages =0 innodb-file-per-table = 1 innodb-buffer-pool-size = 20G innodb_write_io_threads = 8 innodb_read_io_threads = 32 innodb_open_files = 1024 innodb_old_blocks_pct =10 innodb_old_blocks_time =2000 innodb_checksum_algorithm = crc32 innodb_file_format =Barracuda innodb_io_capacity=1500 innodb_io_capacity_max=2000 metadata_locks_hash_instances=256 innodb_max_dirty_pages_pct=90 innodb_flush_neighbors=1 innodb_buffer_pool_instances=8 innodb_lru_scan_depth=4096 innodb_sync_spin_loops=30 innodb-purge-threads=16 |
|
1 2 3 4 5 6 7 8 9 10 11 12 |
[mysqld] tokudb_read_block_size=16K tokudb_fanout=128 table-open-cache-instances=32 table_open_cache=8000 metadata_locks_hash_instances=256 [mysqld_safe] thp-setting=never |
You can see the full set of graphs here, and the complete results here.
Let me start illustrating the results with this summary graph for the io2000 volume, showing how write throughput varies over time, per engine and workload (for all graphs, size is in 1k rows, so 1000 is actually 1M):
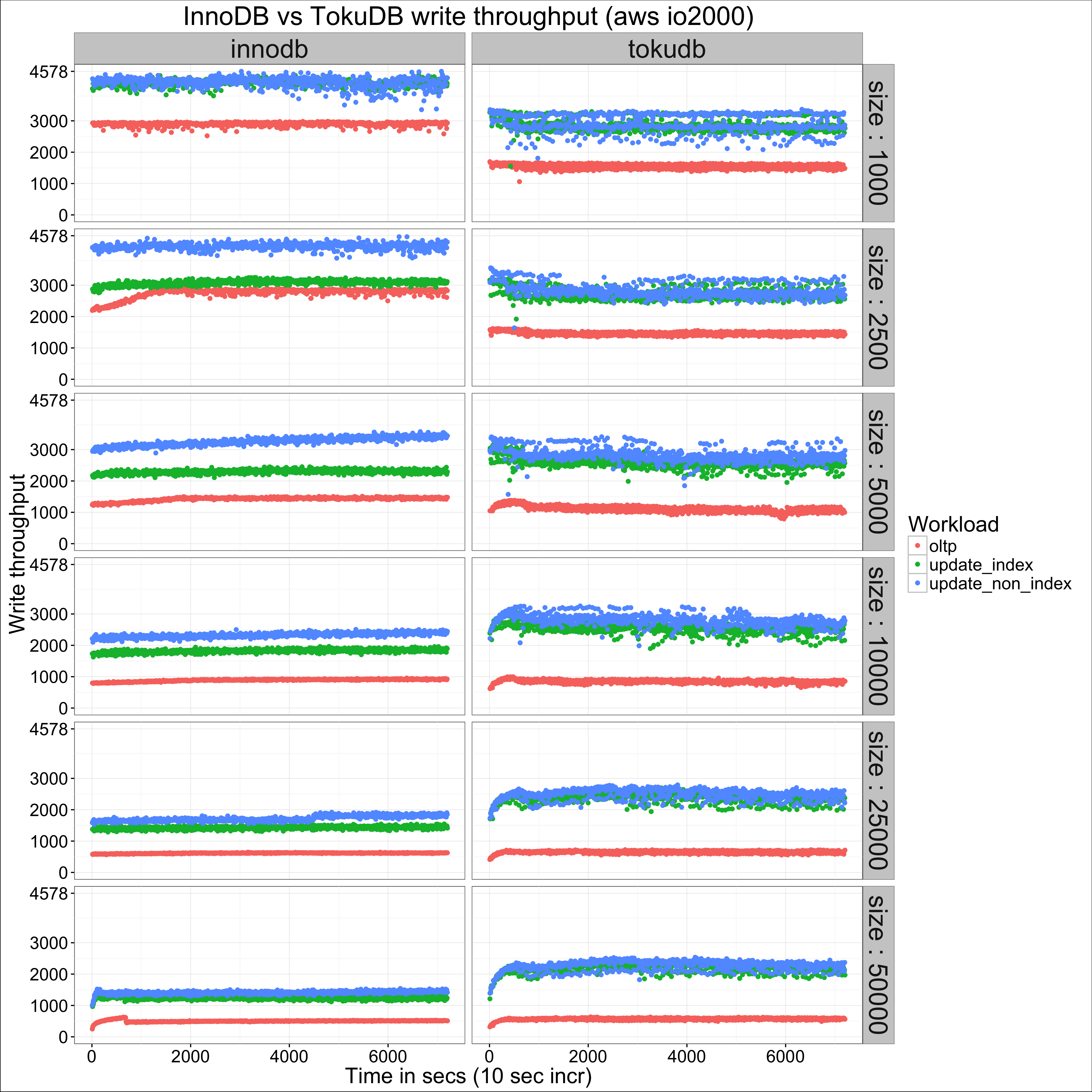
We can see a few things already:
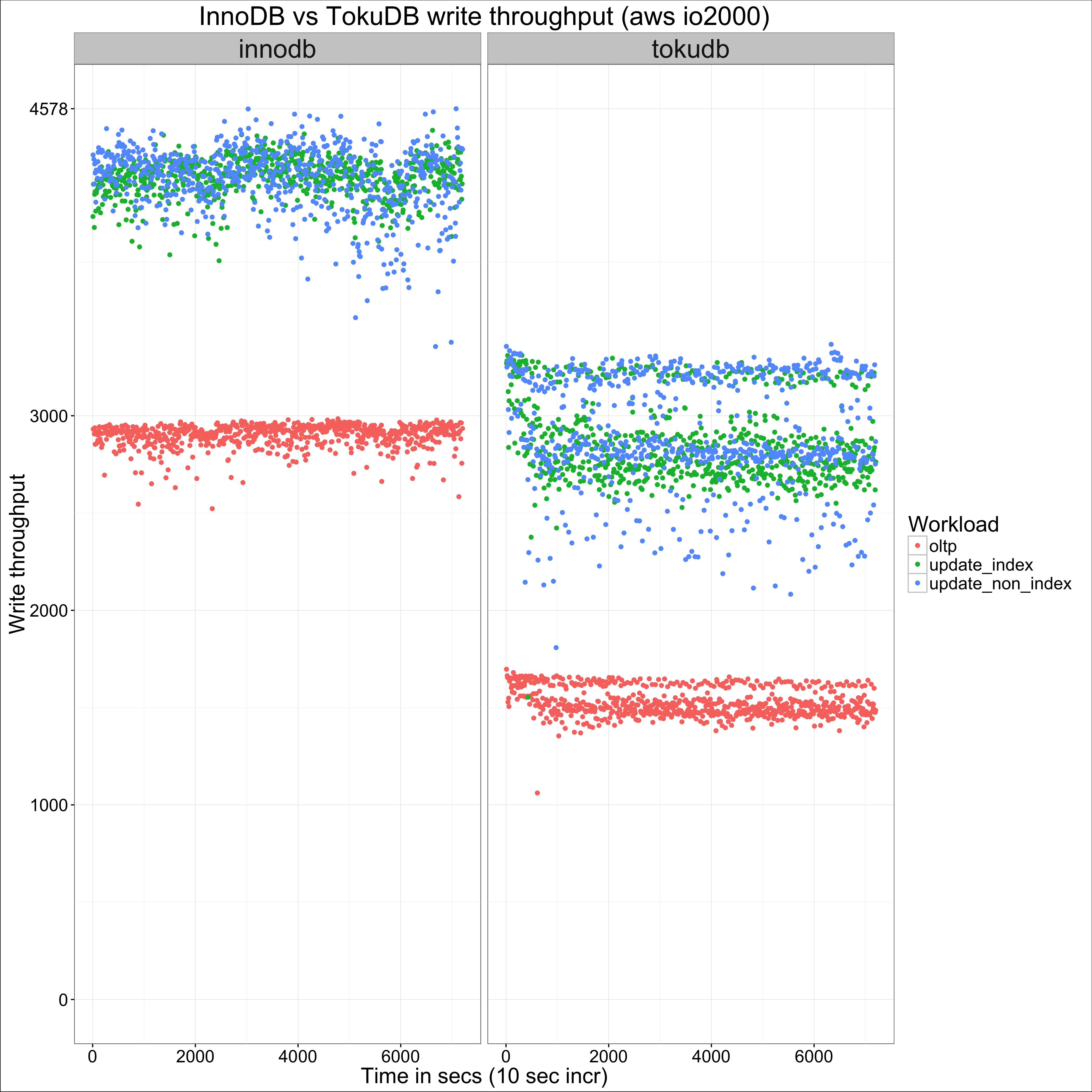
Let’s dig in a bit more and look at the extreme ends in terms of table size, starting with 1M rows:
and ending in 50M:
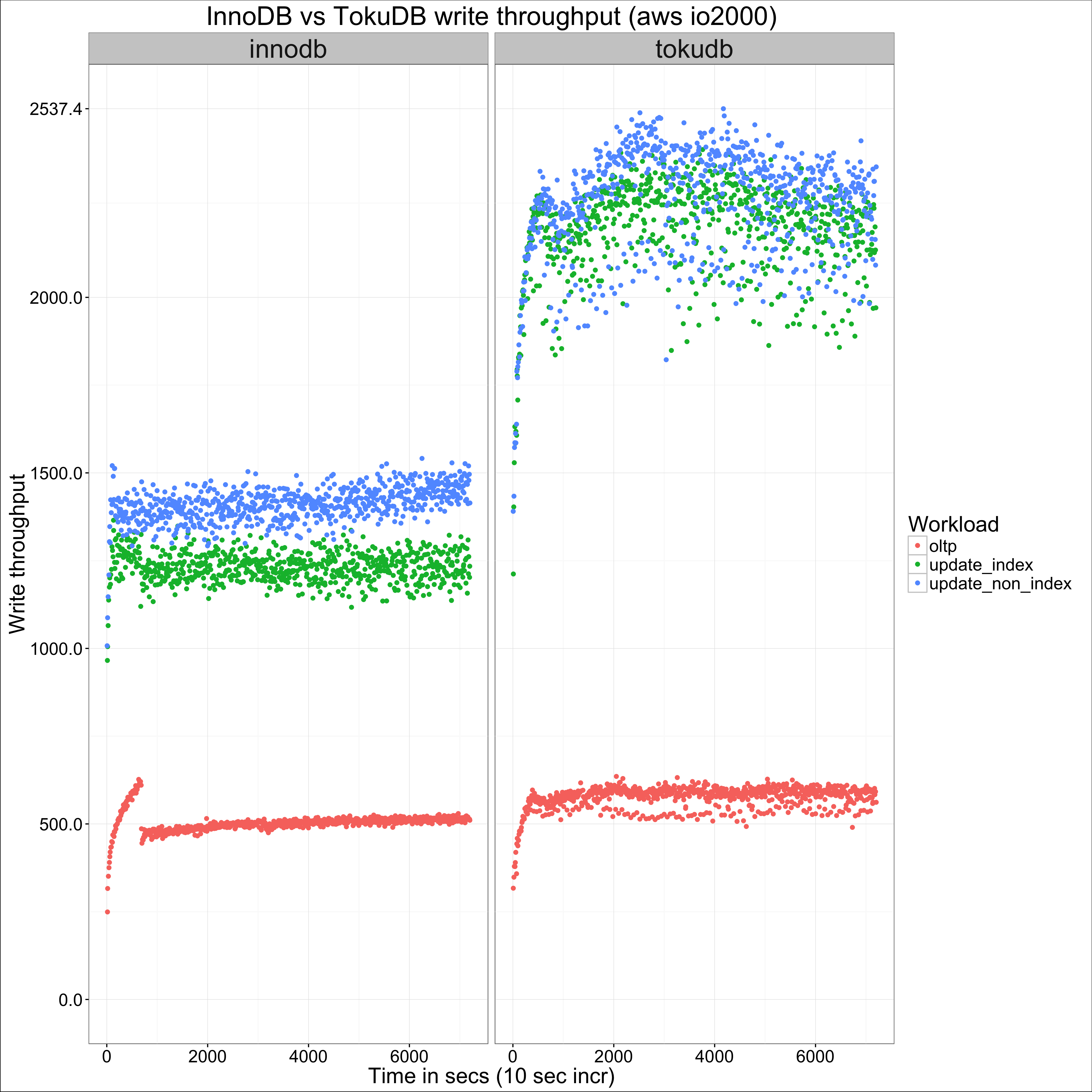
In the first case, we can see that not only does InnoDB show better write throughput, it also shows less variance. In the second case, we can confirm that the difference does not seem significant for oltp, but it is for the other workloads.
This should come as no surprise, as one of the big differences between TokuDB’s Fractal trees and InnoDB’s B-tree implementation is the addition of message buffers to nodes, to handle writes (the other big difference, for me, is node size). For write-intensive workloads, TokuDB needs to do a lot less tree traversing than InnoDB (in fact, this is done only to validate uniqueness constraints when required, otherwise writes are just injected into the message buffer and the buffer is flushed to lower levels of the tree asynchronously. I refer you to this post for more details).
For oltp, InnoDB is at advantage at smaller table sizes, as it does not need to scan message buffers all across the search path when reading (nothing is free in life, and this is the cost for TokuDB’s advantage for writes). I suspect this advantage is lost for high enough table sizes because at that point, either engine will be I/O bound anyway.
My focus here was write throughput, but as a small example see how this is reflected on response time if we pick the 50M table size and drop oltp from the mix:
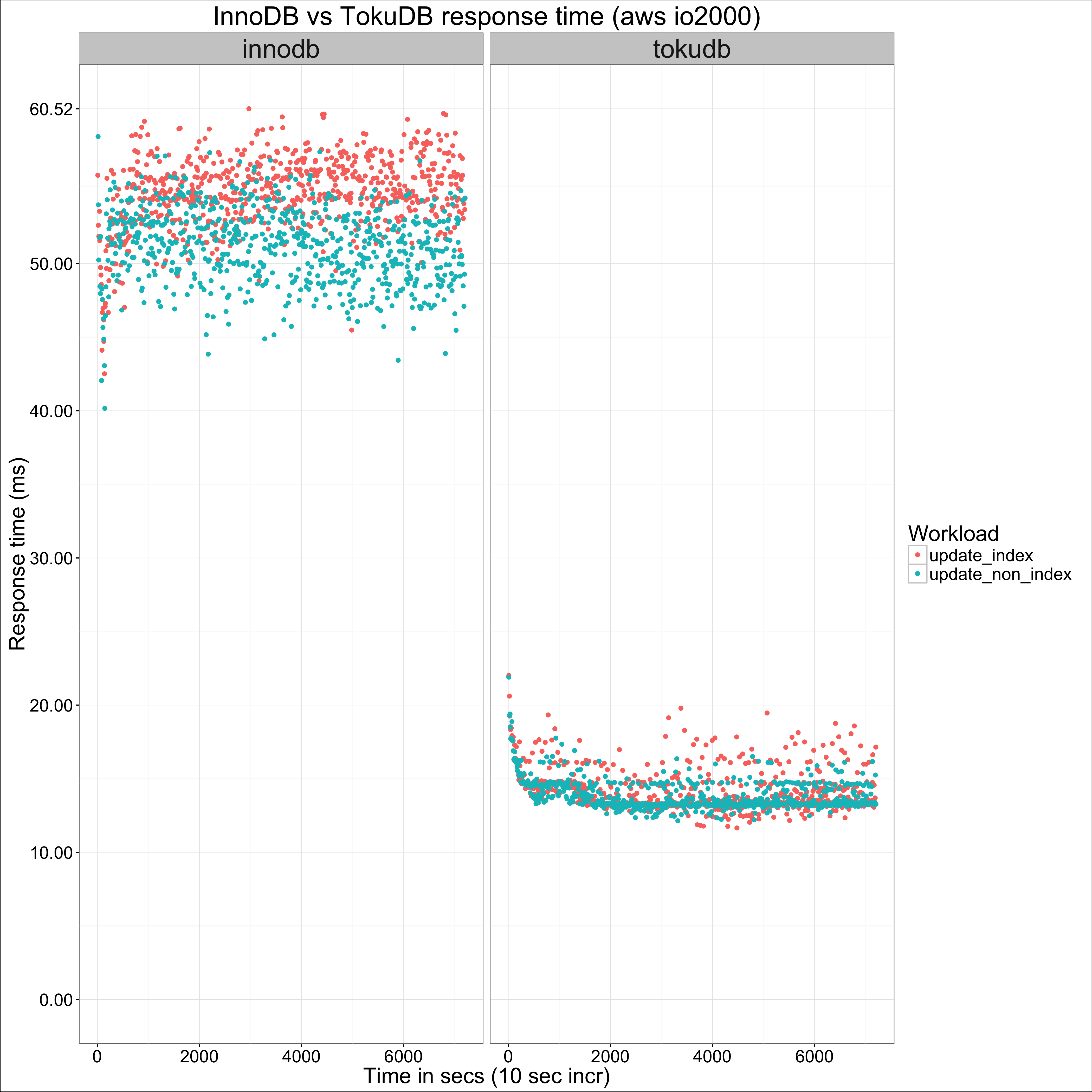
At this point, you may be wondering why I focused on the io2000 results (and if you’re not, bear with me please!). The reason is the results for io3000 and the general purpose ssd showed characteristics that I attribute to latency on the volumes. You can see what I mean by looking at the io3000 graph:
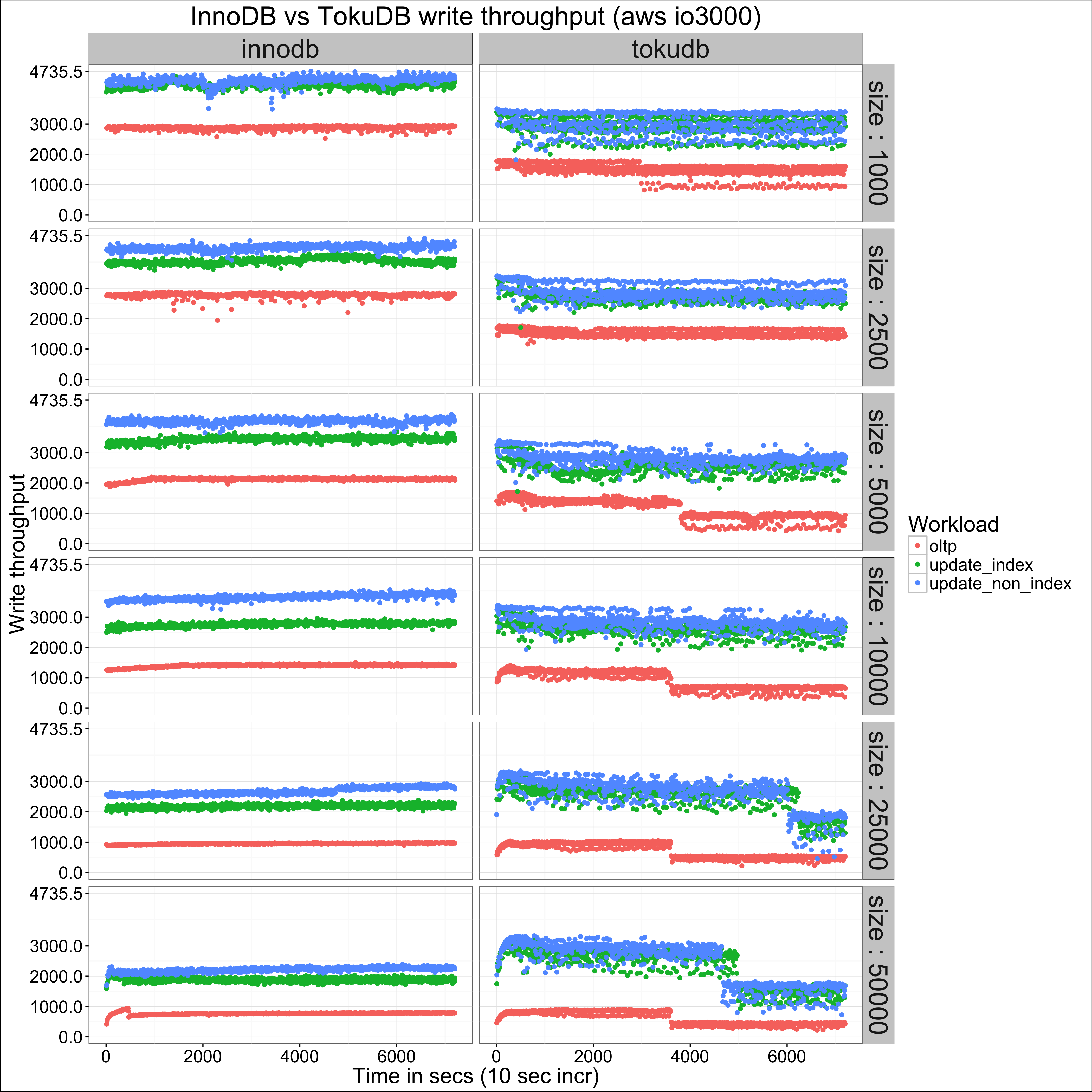
I say “I attribute” because, unfortunately, I do not have any metrics other than sysbench’s output to go with (an error I will amend on future benchmarks!). I have seen the same pattern while working on production systems on AWS, and in those cases I was able to correlate it with increases in stime and/or qtime on diskstats. The fact that this is seen on the lower and higher capacity volumes for the same workload, but not the io2000 one, increases my confidence in this assumption.
Conclusion
I would not consider TokuDB a general purpose replacement for InnoDB, by which I mean I would never blindly suggest someone to migrate from one to the other, as the performance characteristics are different enough to make this risky without a proper assessment.
That said, I believe TokuDB has great advantages for the right scenarios, and this test highlights some of its strengths:
Other advantages of TokuDB over InnoDB, not directly evidenced from these results, are:
Resources
RELATED POSTS





Fernando, it would be great to see some real-world numbers from customer’s who have made the switch from InnoDB to TokuDB.
Can send the detailed test command
A bit late here, but that’s what happens when publishing a post right before going on vacation 🙂
@Tim: I agree, unfortunately, it is difficult to get customers to publish results so, for now, synthetic benchmarks are all I have to offer.
@liuqian: Basically, this, for every volume type: https://gist.github.com/fipar/e1d3a966201eeccf0ed9. For more recent tests, I scripted it here: https://github.com/Percona-Lab/benchmark_automation (check out https://github.com/Percona-Lab/benchmark_automation/blob/master/examples/sysbench_runs_and_graph.md for an example).
Did you test TokuDB with binary log enables? I find the write throughout decrease lots when enable binary log
‘@James: No, I did not test either engine with binary log enabled.
A bit late here – but how about read benchmarking, especially large range seeks?