
With our recent release of TokuMX 1.0, we’ve made some bold claims about how fast TokuMX can run MongoDB workloads. In this post, I want to dig into one of the big areas of improvement, write performance and reduced I/O.
One of the innovations of TokuMX is that it eliminates a long-held rule of databases: to get good write performance, the working set of your indexes should fit in memory. The standard reasoning goes along the lines of: if your indexes’ working set does not fit in memory, then your writes will induce I/O, you will become I/O bound, and performance will suffer. So, either make sure your indexes fit in memory, or make sure your indexes have an insertion pattern that keeps the working set small, like right-most insertions.
With TokuMX, THIS SIMPLY ISN’T TRUE. The innovation of Fractal Tree indexes is that as your working set grows larger than main memory, write performance stays consistent. This innovation is why Fractal Tree indexes perform so well on write-heavy benchmarks (for both MongoDB and MySQL).
So how does TokuMX achieve this write performance where many other databases struggle? By replacing B-Trees, the predominant storage data structure in many databases (MongoDB, MySQL, BerkeleyDB, etc…) with Fractal Tree indexes, a write-optimized data structure.
What do we mean by a write-optimized data structure?
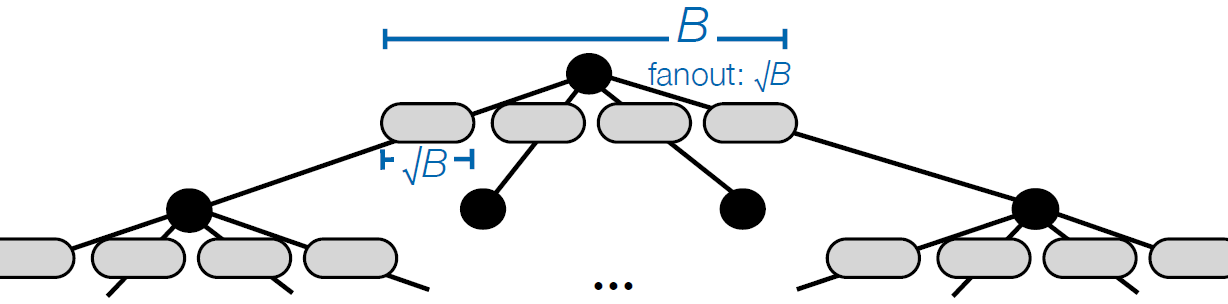
To understand what we mean, we first need to understand why a B-Tree struggles when indexes no longer fit in memory. Below is a picture of a B-tree.

A B-tree is a simple (and elegant) data structure. The internal nodes store many pivots and pointers, and the leaf nodes store all the data. To insert into a B-tree, one must traverse to the leaf node where the data belongs, and place the data into the leaf node. If all of the data fits in memory, this is fast. But if most of the data does not fit in memory (as in the picture above, where only the internal nodes and very few leaf nodes fit), then retrieving that leaf node will require an I/O. In fact, nearly all insertions will incur an I/O. This is where the I/O bottleneck comes from. This is where the struggling write performance comes from. If your hard disk can do on the order of a few hundred I/O’s per second, then your B-tree can handle at most a few hundred insertions per second. This is why MongoDB and MySQL struggle with iiBench, and users are justifiably told to “keep the working set of indexes in memory”.
So why are Fractal Tree indexes so much better? In short, they drastically reduce the I/O. Here is how.
The key difference between Fractal Tree indexes and B-Trees that explains the difference in write performance can be found in the internal nodes:
Note in the picture above that in the internal node, for each child, there is a grey buffer.
The buffers batch up write operations, so that a write works as follows:
The flush of a buffer in the root node may cause a cascading flush. That is, the flush in the root node may flood the child with enough data such that now the child’s buffers are full, and the child needs to flush. This keeps happening until data eventually flushes all the way down to leaves.
So why does this algorithm result in such better performance? The short answer is reduced I/O (really, it’s ALL about the I/O). With I/O’s being so expensive, if we must do an I/O we want the benefit we receive to be worth it. With B-trees, on a write, we do an I/O to insert one measly document or row, or key/value pair. With Fractal Tree indexes, by assuming the root node is always in memory, we know that when we perform an I/O on a write, we do it to flush a buffer’s worth of data. This may contain many many documents (or rows, etc…). With each I/O servicing many more writes, Fractal Tree indexes reduce the amount of I/O done by a LARGE factor, thereby eliminating the I/O bottleneck that B-Trees have.
Because of this I/O reduction, Fractal Tree indexes don’t require indexes to fit in memory, and TokuMX is able to achieve such high sustained write performance on data that does not fit in memory.
Another interesting thing to note about these algorithmic properties is that if the data resides in memory, then Fractal Tree indexes are not providing any algorithmic advantage over B-Trees for write performance. If everything fits in memory, then algorithmically, both data structures are fast.





This explains how writes can be made more efficient. However for reads, presumably the algorithmic complexity is the same as it is for B-Trees? If the index is larger than memory won’t reads, on average, cause random I/O?
This is accurate. In fact, regardless of the data structure, if the data is greater than memory, queries will require an I/O because the data MUST be on disk and MUST be read.
I’ll dig a little more into how queries are done in a future blog post.
What happens in the case where there is a power outage and with unflushed data is in the buffers? Is this a case of minimizing I/O versus data loss?
The buffers are part of the data structure that gets serialized to disk. When we write an internal node to disk, be it for checkpoint or due to eviction, we write the buffers as well. So, there is no data loss. For crashes or power outages, we have logging and recovery. We log high level operations (insert, delete, etc…) that happen in our system, and during recovery, we replay them. So, if a write happened before the last checkpoint, then the data is on disk, but if it did not, then recovery will replay the operation from the log.
So the different levels do not overlap in what they store?
I am not sure what you mean here. I assume by levels you mean buffers at some height of the tree. Each individual buffer stores messages aimed for a leaf node below it. It’s possible for several messages to be aimed at the same key. These messages are stored in the order in which they modify the key, so we are sure that the correct modifications are performed. Does this answer your question?
Sorry for being unclear. Isn’t the effective cache size reduced since you are trading some block space for store buffer space? How does this affect the read performance? Does this approach also not increase the height of the index?
Yes, buffers take up more cache space. In write-heavy workloads, it does not matter because having leaf nodes in memory does not matter. For read heavy workloads, we have background threads periodically flushing buffers to ensure that buffers do not get too full and swallow up cache. These background threads also run in write heavy workload, but have little effect. So, in read-heavy workloads, the effect is minimal. In write heavy workloads, read performance is affected, but that’s ok because you are doing plenty of writes anyway.
The height of the tree (or index as you say it) is also higher.
Thank you.
what’s the main difference between Fractal tree and Arge’s buffer tree ? thanks
Arge’s buffer tree uses internal nodes with buffers of size Θ(M) and fanout Θ(M). While this gives the nice theoretical result that inserting N elements is as fast as sorting N elements, it’s not very practical to implement in a transactional database system. Our Fractal Trees instead use buffers and fanout of constant size, constants which have been tuned for good performance with the disks we have in the real world. Other than that, the basic idea is very similar.
Beyond this, when we say “Fractal Tree,” in the most rigorous sense we mean “the thing that we implement in its most current form,” not some ideal data structure that’s written in a theory paper somewhere that we’re trying to implement. While it’s tempting to say “we implement X data structure,” we actually take ideas from a lot of places and add in a healthy dose of heuristics so that the end result is an amalgam of many different structures, and even works a little like a B-tree sometimes (B-trees are very good at sequential insertions, after all). Some day we want to be able to publish all of our ideas, optimizations, and heuristics in real papers, but that’s a big project and we have a lot of work to do for our customers right now. For now we’re just trying to blog about all of them in bits and pieces as we get the chance. So the other differences between a buffer tree and a Fractal Tree are all the extra optimizations and tuning we’ve added over the years.
This answers my question. Thank you !
Hmm interesting. But then you need two things:
1. The lookup for a value should look into the buffers too.
2. There need to be a very complex algorithm, which applies the changes in the buffers in an efficient way.
Do you have articles about the second point?
Interesting but I’ve not understood how you don’t violate the ACID compliance. Any insert should be backed by an I/O on a stable media (i.e. the log files) in order to honor the “D” durable… how can a buffer help?