 In my previous post Amazon Aurora – Looking Deeper, I promised benchmark results on Amazon Aurora.
In my previous post Amazon Aurora – Looking Deeper, I promised benchmark results on Amazon Aurora.
Amazon used quite a small dataset in their benchmark: 250 tables, with 25000 rows each, which in my calculation corresponds to 4.5GB worth of data. For this datasize, Amazon used r3.8xlarge instances, which provided 32 virtual CPUs and 244GB of memory. So I can’t say their benchmark is particularly illustrative, as all the data fits nicely into the available memory.
In my benchmark, I wanted to try different datasizes, and also compare Amazon Aurora with Percona Server 5.6 in identical cloud instances.
You can find my full report there: http://benchmark-docs.readthedocs.org/en/latest/benchmarks/aurora-sysbench-201511.html
Below is a short description of the benchmark:
Data Sizes
- Initial dataset. 32 sysbench tables, 50 million (mln) rows each. It corresponds to about 400GB of data.
- Testing sizes. For this benchmark, we vary the maximum amount of rows used by sysbench: 1mln, 2.5mln, 5mln, 10mln, 25mln, 50mln.
In the chart, the results are marked in thousands of rows: 1000, 2500, 5000, 10000, 25000, 50000. In other words, “1000” corresponds to 1mln rows.
Instance Sizes
It is actually very complicated to find an equal configuration (in both performance and price aspects) to use as a comparison between Percona Server running on an EC2 instance and Amazon Aurora.
Amazon Aurora:
- db.r3.xlarge instance (4 virtual CPUS + 30GB memory)
- Monthly computing cost (1-YEAR TERM, No Upfront): $277.40
- Monthly storage cost: $0.100 per GB-month * 400 GB = $40
- Extra $0.200 per 1 million IO requests
Total cost (per month, excluding extra per IO requests): $311.40
Percona Server:
- r3.xlarge instance (4 virtual CPUS + 30GB memory)
- Monthly computing cost (1-YEAR TERM, No Upfront): $160.60
For the storage we will use 3 options:
- General purpose SSD volume (marked as “ps” in charts), 500GB size, 1500/3000 ios, cost: $0.10 per GB-month * 500 = $50
- Provisioned IOPS SSD volume (marked as “ps-io3000”), 500GB, 3000 IOP = $0.125 per GB-month * 500 + $0.065 per provisioned IOPS-month * 3000 = $62.5 + $195 = $257.5
- Provisioned IOPS SSD volume (marked as “ps-io2000”), 500GB, 2000 IOP = $0.125 per GB-month * 500 + $0.065 per provisioned IOPS-month * 2000 = $62.5 + $130 = $192.5
So corresponding total costs (per month) for used EC2 instances are: $210.60; $418.10; $353.10
Results
More graphs, including timelines, are available by the link http://benchmark-docs.readthedocs.org/en/latest/benchmarks/aurora-sysbench-201511.html
Summary results of Amazon Aurora vs Percona Server vs different datasizes:
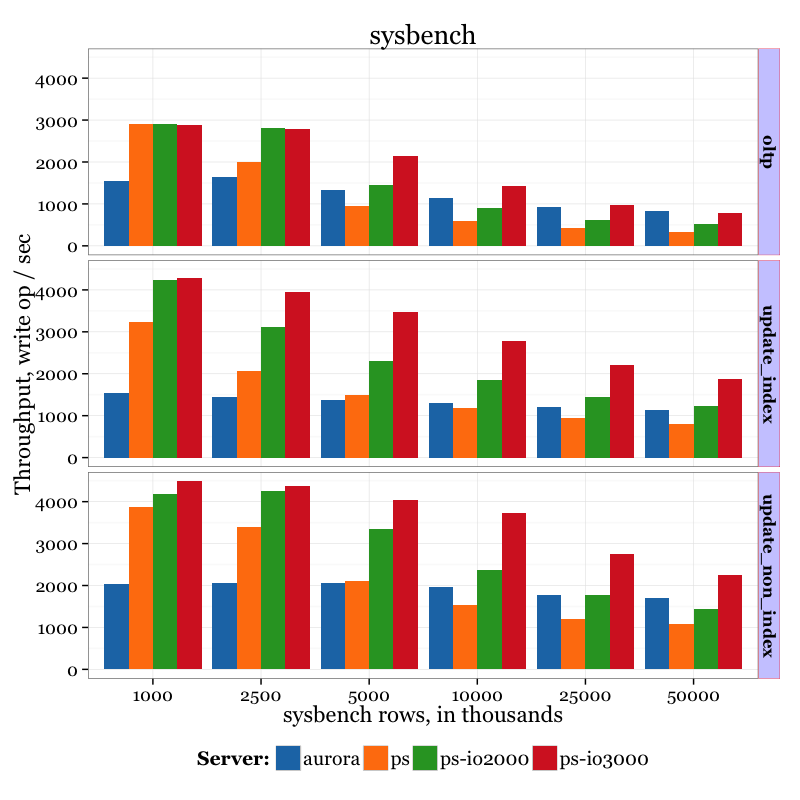
Observations
There are few important points to highlight:
- Even in long runs (2 hours) I didn’t see a fluctuation in results. The throughput is stable.
- I actually made one run for 48 hours. There were still no fluctuations.
- For Percona Server, as expected, better storage gives better throughput. 3000 IOPS is better then Amazon Aurora, especially for IO-heavy cases.
- Amazon Aurora shows worse results with smaller datasizes. Aurora outperforms Percona Server (with general purpose SSD and provisioned SSD 2000IOPS volumes) when it comes to big datasizes.
- It appears that Amazon Aurora does not benefit from adding extra memory – the throughput does not grow much with small datasizes. I think it proves my assumption that Aurora has some kind of write-through cache, which shows better results in IO-heavy workloads.
- Provisioned IO volumes indeed give much better performance compared to general purpose volume, though they are more expensive.
- From a cost consideration (compared to provisioned IO volumes) 3000 IOPS is more cost efficient (for this particular case, but in your workload it might be different) than 2000 IOPS, in the sense that it gives more throughput per dollar.






Very Interesting!
Few Observations!
– It is interesting how Amazon Aurora scales much better with workload becoming more IO Bound. You would expect that from major optimizations of IO subsystem!
– Interesting to see how with in memory workloads Amazon Aurora is slower with writes, One would expect that with essentially write-through buffer pool design.
– It would be interesting to see the read-only runs as well, with what it seems to be improved Query Cache this might be explanations for some good results posted by others
– The tests done with 16 connections which is likely to be optimal for Percona Server. It would be interesting to see some of the tests for various connection number to see how different systems scale
– It is not clear to me how HA provided is different in this case. As I understand with single Percona Server node if it is ever to crash the EBS can be used to have poor man’s active-passive fail-over. Is same applicable to Amazon Aurora as well ? It would be interesting of course to see how environments which provide HA compare – PXC ? Couple of Amazon Aurora nodes versus replication ?
Would be very interesting to see benchmarking not only by IO scaling but by connection scaling with lower cache hit ration. We can extrapolate, but would be nice to see an actual curve between Aurora and MySQL. Also interesting to see Enterprise MySQL benchmarking. Did anybody done that?
Can you speak to the thread count? Are 16 threads on a t2.medium really sufficient to saturate these machines? In the AWS benchmark, they used 1000 threads spread over 4 r3.8xlarge instances.
Would it be possible to repeat the PS test but on the ephemeral instance storage provided to the instance? This is what we use for relational databases, because it provides far higher throughput than even provisioned IOPS EBS drives can, and without having to pay.
Peter, I agree with your comments that Aurora will scale better with a higher number of connections. We’ve engineered the service to scale with # connections, # cores, and size of working set, so you should also see better comparative performance as you scale instance and data size as well. Altogether too many benchmarks fit in memory which just isn’t representative of most customer workloads.
It is also important to note that Aurora always durably writes across 3 Availability Zone, only acknowledging commits when data has been hardened to disk on at least 4 out of 6 copies of the data. With a small dataset, and low connection count, you’re bound to see a fairly underutilized database engine, at least with Aurora, as the throughput for write operations will be dominated by network latency (without sufficient work to take advantage of batching).
Finally, we run some of the benchmarks independently ourselves, and achieved in some cases higher results with Aurora compared to the ones you published. For example, this result here https://github.com/Percona-Lab/benchmark-results/blob/aurora-sysbench-201511/aurora/au.1000.oltp.txt – oltp with 1 million rows rows – shows 6962.99 requests per second, whereas we measured around 10,000 ourselves. Was your client machine in the same Availability Zone and VPC as the database server? This is something we highlight in our benchmarking whitepaper here https://d0.awsstatic.com/product-marketing/Aurora/RDS_Aurora_Performance_Assessment_Benchmarking_v1-2.pdf . In particular, it is important that client and server are in the same VPC to avoid excessive overhead caused by Network Address Translation. I suggest reviewing that part of your setup to double check.
We also went ahead and collected numbers with a higher connection count and a larger instance type in Aurora to show its ability to scale. Again please keep in mind that all these numbers factor the overhead of synchronously replicating across Availability Zones, which is a fundamental design decision to maximize availability and durability. We also used a larger instance type for the client to avoid it becoming a bottleneck at higher throughput rates. The numbers are expressed in read/write requests per second . Please notice how increasing the connection count increases throughput anywhere between 50% and 15X depending on instance and workload type. You should be able to reproduce these fairly straightforwardly, but do reach out to us if you have any difficulty doing so. I hope the data displays OK.
Aurora results on R3.XL:
Number of connections 16 100 250 OLTP 1 Million 10K 15.1K 16.0K OLTP 50 Million 3.9K 5.8K 7.2K Update Index 1 Million 1.5K 3.5K 5.0K Update Index 50 Million 1.3K 2.6K 3.3K Update Non Index 1 Million 2.1K 7.8K 11.1K Update Non Index 50 Million 1.9K 4.2K 6.0KAurora results on R3.8XL:
Number of connections 16 100 500 1,000 OLTP 1 Million 15.7K 56.2K 95.4K 102.7K OLTP 50 Million 12.8K 42.4K 60.4K 74.1K Update Index 1 Million 2.0K 8.0K 23.4K 32.0K Update Index 50 Million 2.3K 7.9K 20.0K 26.4K Update Non Index 1 Million 2.4K 9.6K 28.0K 38.8K Update Non Index 50 Million 2.8K 8.7K 22.4K 31.4KI should also note that we _do not_ write through the buffer pool. No buffer pool writes are required in Aurora, as we instantiate data pages in background at the storage tier from log records. The only writes from the database to storage are for redo log records.
I see that my table formatting got lost. Would you mind republishing those numbers in a table format accepted by your blogging software?
My understanding is that the Aurora storage is replicated to another data center (actually two, but only one needs to respond for the write to complete). This would prevent caching the writes but give a 0 RTO for localized failures.
I assume Percona is not using remote replication beyond the local EBS mirroring. That also would affect the test Matt suggested as ephemeral drives are unprotected. Of course you could compare a Percona XtraDB cluster using ephemeral drives — that might be a better comparison to Aurora.
Bryan, that’s correct (strictly speaking, Aurora has 6 copies of data, spread across 3 data centers, any four of which need to return, all peer-to-peer replicating in background). This does allow a customer to spin up an instance in a new data center should their data center go down. Or run read replicas in another data center, and have it automatically promoted on loss of the primary instance.
In any case, you’ll see that the core issue in this particular compare is just not providing enough work to Aurora (number of connections) to get peak throughput.
‘@Matt Yonkovit,
Instances r3.xlarge come only with 80GB of ephemeral storage, so I won’t be able to fit 400GB of data there.
‘@Anurag,
Thank you for your comments, I will accommodate suggestions in further experiments.
It is worth to note that R3.8XL Aurora instances will set you $2204.60 / month with 1-year commitment, so it is also will be interesting to compare this with high end bare metal servers.
‘@Vadim Tkachenko, thanks for that. Do let us know if you have any difficulty reproducing our numbers. We’re happy to take a look at your setup and ensure it is aligned with ours. As with any experiment, the data only has validity if reproducible by others. I have my team looking at updating our performance white paper to include a broader set of benchmarks than there currently – this should help with this process.
I agree that a comparison to bare metal servers would be useful for customers. You might also compare to the i2 instance family in AWS – it has roughly the same specs as R3, but with locally attached SSDs. Though both i2 and bare metal servers have a different durability/availability profile than Aurora with multi-data-center storage.
Thank you for this. Very interesting.
FYI a common cost optimisation: you can achieve those IOPS cheaper simply by increasing the volume size as it is guaranteed 3 IOPS/GB to a maximum of 10,000 IOPS.
I.e. To get 3000 IOPS use a volume size of 1000GB at a cost of $100.
Anurag,
Thank you very much for our detailed explanations. It would be great to have more benchmarks across the concurrency and data sizes as you see wide variety of them relevant for different applications. The concurrency of 16 might look low and indeed might not saturate system fully but it is very rare to see sustained concurrency higher than that – you often see many connections but only few of them are active at the same time.
It would be interesting to see some “injection” benchmarks which look at the response time at given inflow transaction rate – it is much more relevant to how real world applications behave
Thank you for availability zone explanations. If I understand you correctly normal EBS exists in single Availability zone so it does not provide as good reliability as Amazon Aurora.
In terms of write load I’m not sure I understand the Network latency being dominating factor – if you ensure on the write transaction commit is written to 6 copies in 3 availability zones with at least 4 acknowledgement – would not this be dominating latency for commits ?
I hope we will be able to find while you’re getting the different numbers than we do – we would like to know how to get the best performance possible from Amazon Aurora.
Thanks for sharing more details on how replication works. From what you describe now it looks like “log shipping” where application of logs both on source AZ as well as others is done on the storage level. Very nice!
Thanks Vadim for this very interesting chart. I was under the impression that Amazon technologies were slower, but the above chart does not support my theory.
I’m surprised that only Peter mentioned Aurora’s cache in the comment section – I thought this subject would get a lot more attention considering the results above.
@Anurag – would it be possible for you to explain a bit on how caching is done on Aurora? It would be very interesting to know.
‘@Fadi, are you referring to the query cache or the buffer cache?
If query cache, Aurora is much like MySQL, except that we’ve modified the query cache locking quite significantly. MySQL turns off query cache by default, because the system (5.6 at least) runs slower with caching due to the need to lookup and invalidate cached entries on table updates. We’ve addressed this to a large degree, and are hopeful that this removes the need to front-end MySQL with a memcached layer for many applications. Not only does this reduce costs, it also reduces application complexity, since the cached entries are invalidated transactionally alongside the data updates. The tradeoff is that, due to the nature of SQL, we have to be quite conservative about invalidating entries when a table changes, while an application can be more discriminating – so there is still an argument for front-ending the database with cache in some cases.
The Aurora buffer cache is quite different from MySQL or other traditional databases. Most significantly, there is no checkpointing. Checkpointing is a process wherein the database ensures that no dirty block in the buffer cache is more than X minutes old (X is typically 5 minutes). This puts an outer bound on the amount of redo that might need to be replayed during crash recovery. Aurora doesn’t do checkpointing (or any other writes of data pages from the database tier). Redo records are pushed to storage nodes and storage nodes are responsible for ensuring that they eventually are used to generate updated versions of data blocks – either on demand as the page is requested or in background as part of the general coalesce and GC process. Similar to checkpointing, a traditional database needs to ensure that pages are being written out to disk at the same rate at which they are being dirtied – otherwise, one may need to stall reading a page in until the replacement victim block has been written to disk. In Aurora, since pages are generated at the storage tier, we can just throw away the block (once, like MySQL, we’ve ensured that the log records needed to generate it have also been written to disk).
As a side effect of this architecture, Aurora doesn’t need to wait for redo log replay to open the database after a crash. The storage nodes will generate current versions of blocks as needed at any time, so there’s no reason why they must be brought to current version as part of crash recovery. This can greatly reduce crash recovery time, particularly for write-heavy workloads.
Make sense?
‘@Peter, in “log shipping”, we send the same redo log records we send to storage nodes over to our read replicas. If the replica has the associated data block in buffer cache, it is responsible for updating its cache entry by applying the redo record. If the block isn’t in buffer cache, the replica can just throw away the entry, as it shares the same underlying storage as the primary instance. There is some modest bookkeeping required since 1) the replica is in the past of the primary and we may have to provide an earlier version of a block to a replica than is current on primary and 2) we need to align DDL changes with DML changes, but that’s the gist of the idea. It does greatly reduce replica lag.
A nice side-effect of this design is that you can run replicas asynchronously to reduce write latency on the primary, but not lose data if we need to promote the replica to primary – all writes that were ack’ed at the primary would have been persistented on disk, so are visible to the replica on promotion.
‘@Peter, on Availability Zones, EBS (or RDS Single-AZ) provides mirroring or a 2/2 quorum model with two disks in a single AZ. RDS Multi-AZ improves on this by creating a standby instance with it’s own EBS disks, and ack’ing a write only when written across the disks of both primary and standby. This is effectively a 4/4 quorum across 2 AZs.
Aurora spreads data widely in 20GB chunks of space, but each 20GB chunk is part of a protection group that consists of 6 copies of data, spread as 2 copies in each of 3 AZs. We require 4 of these 6 copies to ack a write to consider it durable. The storage nodes also gossip with each other to fill in holes for writes that they did not see. Note that the durability characteristics of this are really no better than traditional RDS Multi-AZ as, in both cases, there is a lower bound of 4 copies of data. The availability, however, is much better, since we can tolerate loss of disk or AZ without losing write activity. Repairs are also much faster since a relatively small amount of data needs to be moved.
‘@peter wrote: “In terms of write load I’m not sure I understand the Network latency being dominating factor – if you ensure on the write transaction commit is written to 6 copies in 3 availability zones with at least 4 acknowledgement – would not this be dominating latency for commits ?”
I did mean the network traffic between database nodes and storage nodes as the network activity that would dominate latency. So am aligned with your view. A point where throughput and latency start to diverge is that we are able to boxcar requests going out to the storage nodes, so can leverage the network packets better when there is more work available. So, that’s a case where latency doesn’t go up as workload increases but throughput does.
@peter also wrote “The concurrency of 16 might look low and indeed might not saturate system fully but it is very rare to see sustained concurrency higher than that – you often see many connections but only few of them are active at the same time.”
Here, while I agree with the point on sustained concurrency, I think spikes matter a great deal for a database. A lot of applications end up directly translating database latency into visible end-user latency. So, it becomes important that one’s database engine be able to absorb 2x-10x greater traffic than average or median. Too many systems operate sub-linear here, where increased load starts browning out all requests (due to locking congestion). In addition, we hope that improved concurrency will help Aurora take on workloads not previously accessible to MySQL without sharding. Its also important to know whether ones data architecture can scale as ones application and business do so.