
This is the third blog post in the series of blog posts leading up to the talk comparing the optimizer enhancements in MySQL 5.6 and MariaDB 5.5. This blog post is targeted at the join related optimizations introduced in the optimizer. These optimizations are available in both MySQL 5.6 and MariaDB 5.5, and MariaDB 5.5 has introduced some additional optimizations which we will also look at, in this post.
Now let me briefly explain these optimizations.
Traditionally, MySQL always uses Nested Loop Join to join two or more tables. What this means is that, select rows from first table participating in the joins are read, and then for each of these rows an index lookup is performed on the second table. This means many point queries, say for example if table1 yields 1000 rows then 1000 index lookups are performed on table2. Of course this could mean a lot of random lookups in case the dataset does not fit into memory or if the caches are not warm, this also does not take into account locality of access, as you could be reading the same page multiple times. Consider if you have a small buffer pool and a very large number of rows from table2 that do not fit into the buffer pool, then worst case you could be reading the same page multiple times into the buffer pool.
So considering this drawback, Batched Key Access (BKA) optimization was introduced. When BKA is being used then, after the selected rows are read from table1, the values of indexed columns that will be used to perform a lookup on table2 are batched together and sent to the storage engine. The storage engine then uses the MRR interface (which I explained in my previous post) to lookup the rows in table2. So this means that we have traded many point index lookups to one or more index range lookups. This means MySQL can employ many other optimizations like for example if columns other then the secondary key columns are required to be fetched, then MRR interface can instead access the PK by arranging the secondary key values by PK column and then performing the lookup, and then there are other possibilities like InnoDB doing read_ahead by noticing the sequential access pattern.
BKA is available in both MySQL 5.6 and MariaDB 5.5. You can read more about BKA in MySQL 5.6 here and BKA in MariaDB 5.5 here.
However, MariaDB 5.5 has one additional optimization that is used in conjunction with BKA and that is MRR Key-ordered Scan. Let’s see what this optimization actually is.
With this optimization the idea of MRR is further extended to improve join performance. As I told you above, when table t1 would be joined to table t2, then selected rows from t1 would be read and then for all rows, index lookup would be performed on t2. Here is where Key-ordered scan comes in. With BKA turned on, the index lookups to t2 are batched together and sent to the MRR interface. Now when the MRR interface is going to perform the lookup on t2 by a secondary key on the common join column, let’s suppose col1, then with Key-ordered scan, the secondary key on col1 would be sorted by col1 i.e. in index order and then the lookup will be performed. So key-ordered scan is basically an extension of MRR to secondary keys. You can read more about Key-ordered Scan for BKA here.
Now there is one additional join optimization in MariaDB that I would like to quickly explain here, and that is Hash Joins.
As I have told before MySQL has only supported one join algorithm and that is Nested Loop Join. MariaDB has introduced a new join algorithm Hash Join. This join algorithm only works with equi-joins. Now let me briefly explain how hash join algorithm works. Suppose you have two tables t1 and t2, that you wish to join together in an equi-join, then the way hash join algorithm will operate is that first a hash table will be created based on the columns of table t1 that are two be used to join rows with table t2. This step is called the build step. After the hash table has been created, rows from table t2 are read and hash function is applied to the columns participating in the join condition and then a hash table lookup is performed, on the hash table we created earlier. This step is known as probe step. This join algorithm works best for highly selective queries, and obviously when the first operand used in the build step is such that the hash table fits in memory. You can read more about the hash join algorithm here.
Now let’s move on to the benchmarks, to see the difference in numbers.
For the purpose of this benchmark, I have used TPC-H Query #3 and ran it on TPC-H dataset (InnoDB tables) with a Scale Factor of 2 (InnoDB dataset size ~5G). Note that query cache is disabled during these benchmark runs and that the disks are 4 5.4K disks in Software RAID5.
Also note that the following changes were made on MySQL 5.6 config:
|
1 2 3 4 5 6 |
optimizer_switch='index_condition_pushdown=off' optimizer_switch='mrr=on' optimizer_switch='mrr_cost_based=off' optimizer_switch='batched_key_access=on' join_buffer_size=6M read_rnd_buffer_size=6M |
Also note that the following changes were made on MariaDB 5.5 config:
|
1 2 3 4 5 6 7 8 9 10 |
optimizer_switch='index_condition_pushdown=off' optimizer_switch='mrr=on' optimizer_switch='mrr_sort_keys=on' optimizer_switch='mrr_cost_based=off' optimizer_switch='join_cache_incremental=on' optimizer_switch='join_cache_hashed=on' optimizer_switch='join_cache_bka=on' join_cache_level=8 join_buffer_size=6M mrr_buffer_size=6M |
Note that I have turned off ICP because I would like to see the affect of BKA on the query times. But I also had to turn on MRR because BKA uses the MRR interface. Note also the additional optimizer switches and variables in case of MariaDB 5.5. You can read more about these variables here.
The query used is:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
select l_orderkey, sum(l_extendedprice * (1 - l_discount)) as revenue, o_orderdate, o_shippriority from customer, orders, lineitem FORCE INDEX (i_l_orderkey) where c_mktsegment = 'AUTOMOBILE' and c_custkey = o_custkey and l_orderkey = o_orderkey and o_orderdate < '1995-03-09' and l_shipdate > '1995-03-09' group by l_orderkey, o_orderdate, o_shippriority order by revenue desc, o_orderdate LIMIT 10; |
Now let’s see how effective are the join optimizations when the workload fits entirely in memory. For the purpose of benchmarking in-memory workload, the InnoDB buffer pool size is set to 6G and the buffer pool was warmed up, so that the relevant pages were already loaded in the buffer pool. Note that as mentioned at the start of the benchmark results section, the InnoDB dataset size is ~5G. Now let’s take a look at the graph:
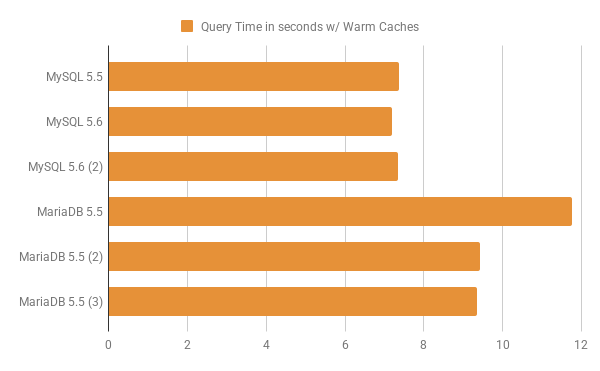
In the graph above the labels mean as follows:
MySQL 5.6 (2) is for MySQL 5.6 w/ buffer size 6M
MariaDB 5.5 (2) is for MariaDB 5.5 w/ buffer size 6M
MariaDB 5.5 (3) is for MariaDB 5.5 w/ buffer size 6M (Hash Join and Key-ordered Scan disabled)
You can see that the lowest query time is for MySQL 5.6 which takes 0.16s less as compared to MySQL 5.5 While with join_buffer_size set to 6M and read_rnd_buffer_size set to 6M, the query time for MySQL 5.6 becomes approximately equal to that of MySQL 5.5. MariaDB 5.5 is quite slow as compared to both MySQL 5.5 and MySQL 5.6. For MariaDB 5.5 the query time decreases when the join_buffer_size is set to 6M and mrr_buffer_size is set to 6M. While the lowest query time for MariaDB 5.5 is when both the Hash Join and the Key-ordered Scan are disabled.
Now let’s see how effective are the join optimizations when the workload is IO bound. For the purpose of benchmarking IO bound workload, the InnoDB buffer pool size is set to 1G and the buffer pool was not warmed up, so that it does not have the relevant pages loaded up already. Now let’s take a look at the graph:
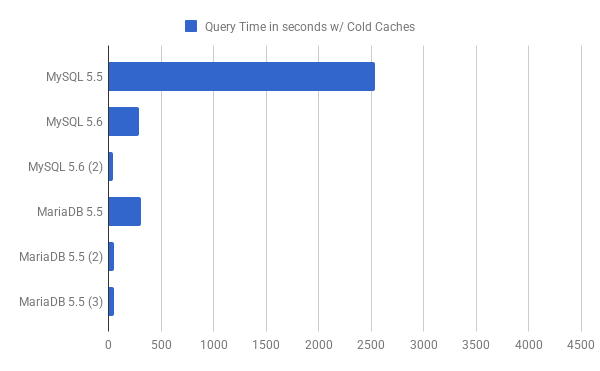
The labels in the graph above are same as in the graph for in-memory workload.
BKA makes a huge difference when the workload is IO bound and the query time drops from 2534.41s down to under a minute. MySQL 5.6 has the smallest query time when the join_buffer_size is set to 6M and the read_rnd_buffer_size is set to 6M. MariaDB 5.5 is close, yet slower by ~10s. Another thing that is important to know is that, just increasing the join_buffer_size is not going to provide the best possible query performance. As I mentioned at the start that BKA uses the MRR interface so you should also adjust/increase the size of the buffer that MRR uses appropriately. In my tests I noticed that with just the join_buffer_size increased to 6M, the query time was ~300s while when both the join_buffer_size and the read_rnd_buffer_size/mrr_buffer_size were set to 6M, the query time dropped to ~40s. So the maximum possible benefit is when size of both the buffers is increased appropriately. Also in the chart above the bottom two bars correspond to MariaDB with Hash Join and Key-ordered Scan enabled, and MariaDB with Hash Join and Key-ordered Scan disabled, and the only difference in query time is 48.78s vs 48.91s, so I don’t see Hash Join and Key-ordered Scan making much of a difference here.
Now let’s take a look at the status counters.
| Counter Name | MySQL 5.5 | MySQL 5.6 | MySQL 5.6 w/ join_buffer_size=6M & read_rnd_buffer_size=6M | MariaDB 5.5 | MariaDB 5.5 w/ join_buffer_size=6M & mrr_buffer_size=6M | MariaDB 5.5 Hash Join Disabled w/ join_buffer_size=4M & mrr_buffer_size=4M |
| Created_tmp_disk_tables | 0 | 0 | 0 | 0 | 0 | 0 |
| Created_tmp_tables | 1 | 1 | 1 | 1 | 1 | 1 |
| Handler_mrr_init | N/A | 112 | 3 | 1133 | 1 | 1 |
| Handler_mrr_key_refills | N/A | N/A | N/A | 0 | 0 | 0 |
| Handler_mrr_rowid_refills | N/A | N/A | N/A | 22 | 0 | 0 |
| Handler_read_key | 1829910 | 4440511 | 4372096 | 1801917 | 1790641 | 1805995 |
| Handler_read_next | 2651500 | 2628103 | 2586036 | 2628103 | 2592816 | 2615612 |
| Handler_read_rnd_next | 23078 | 22780 | 22757 | 22867 | 23049 | 23221 |
| Innodb_buffer_pool_read_ahead | 1152 | 23231 | 130919 | 23228 | 130731 | 131497 |
| Innodb_buffer_pool_read_requests | 12947073 | 10228611 | 7816154 | 10251697 | 9319281 | 9393396 |
| Innodb_buffer_pool_reads | 327963 | 332092 | 12889 | 335080 | 14067 | 13384 |
| Innodb_data_read | 5G | 5.4G | 2.2G | 5.4G | 2.2G | 2.2G |
| Innodb_data_reads | 329115 | 355323 | 143808 | 335526 | 16164 | 15506 |
| Innodb_pages_read | 329115 | 355323 | 143808 | 358308 | 144798 | 144881 |
| Innodb_rows_read | 4127318 | 6718351 | 6611675 | 6707882 | 5479445 | 5527245 |
| Select_scan | 1 | 1 | 1 | 1 | 1 | 1 |
| Sort_scan | 1 | 1 | 1 | 1 | 1 | 1 |
The first obvious improvement is shown by the high numbers of Innodb_buffer_pool_read_ahead when the buffers are sized appropriately, which shows that the IO access pattern has been changed to become sequential. The two other most important numbers are values for Innodb_buffer_pool_reads and Innodb_data_read. We can see that with appropriately sized buffers less no. of Innodb_buffer_pool_reads are done, and less amount of data is read from disk, in fact half the amount of data is read from disk 2.2G vs 5G. However, there is one number in MariaDB 5.5 that is quite large as compared to MySQL 5.6 and that is ‘Handler_mrr_init’. Is it because of this that the query on MariaDB 5.5 is slow as compared to MySQL 5.6. Next interesting thing are the last two columns of the table above and the values for ‘Handler_read_key’, ‘Handler_read_next’ and ‘Handler_read_rnd_next’. MariaDB 5.5 with Hash Joins enabled is doing less Handler reads as compared to when the Hash Joins are disabled, but that did not make much of a difference in the query times.
BKA improves the query time by a huge margin for IO bound workload but does not make much of a difference to in-memory workload. Also BKA relies on both the join_buffer_size and the read_rnd_buffer_size/mrr_buffer_size and both of these buffers should be increased appropriately for the best possible performance gain. This is not entirely visible in the manual either for MariaDB or MySQL, but you need to appropriately increase read_rnd_buffer_size/mrr_buffer_size because these have an impact on MRR performance, and BKA uses the MRR interface, so these buffers indirectly impact BKA performance. I did not find much of a performance improvement from using Hash Join in MariaDB 5.5 or from Key-ordered Scan for TPCH query #3, in fact disabling both of these provided the best result for MariaDB 5.5 for in-memory workload.
I intend to run tests to see what specific types of queries would benefit from Hash Join as compared to Nested Loop Join, but for now it looks like Nested Loop Join is a much better general purpose join algorithm.
Resources
RELATED POSTS





Could you, please, provide us with the numbers for the original query #3 from the benchmark?
I remind you that the original query does not contain any hints:
select
l_orderkey, sum(l_extendedprice*(1-l_discount)) as revenue,
o_orderdate, o_shippriority
from customer, orders, lineitem
where c_mktsegment = ‘AUTOMOBILE’ and c_custkey = o_custkey
and l_orderkey = o_orderkey and o_orderdate date ‘1995-03-15’
group by l_orderkey, o_orderdate, o_shippriority
order by revenue desc, o_orderdate
limit 10;
‘@Igor,
Yes you are right the original query does not have an index hint, but I have had to make the QEP selected by the optimizer consistent otherwise it would keep flipping. I would post the numbers for the query without the index hint soon.
I don’t know why there is no support of hash-join or sort-join in MySQL 5.5 . What is problem in using this join algorithm ? I think these is very fast in case of large tables or small main-memory .
My Guess :
1) nested loop join can run faster in case of smaller tables.
2) hash join can not support theta join.
Smit,
Nested-loop join is a good general purpose join algorithm that works well in majority of the cases. However, I think it would be nice to have hash join and sort join algorithms available as well. MySQL 5.6, MariaDB 5.3 and MariaDB 5.5 support Hash Joins. You can check out my post on Hash Joins here: http://www.mysqlperformanceblog.com/2012/05/31/a-case-for-mariadbs-hash-joins/
Куда графики подевали? Не видно же нам ничего! 🙂