
This is the second blog post in the series of blog posts leading up to the talk comparing the optimizer enhancements in MySQL 5.6 and MariaDB 5.5. This blog post is aimed at the optimizer enhancement Multi Range Read (MRR). Its available in both MySQL 5.6 and MariaDB 5.5
Now let’s take a look at what this optimization actually is and what benefits it brings.
With traditional secondary index lookups, if the columns that are being fetched do not belong to the secondary index definition (and hence covering index optimization is not used), then primary key lookups have to be performed for each secondary key entry fetched. This means that secondary key lookups for column values that do not belong to the secondary index definition can result in a lot of Random I/O. The purpose of MRR is to reduce this Random I/O and make it more sequential, by having a buffer in between where secondary key tuples are buffered and then sorted by the primary key values, and then instead of point primary key lookups, a range lookup is performed on the primary key by using the sorted primary key values.
Let me give you a simple example. Suppose you have the following query executed on the InnoDB table:
|
1 |
SELECT non_key_column FROM tbl WHERE key_column=x |
This query will roughly be evaluated in following steps, without MRR:
As you can see that the values returned from Step 1 are sorted by the secondary key column ‘key_column’, and then for each value of ‘pk_column’ which is a part of the secondary key tuple, a point primary key lookup is made against base table, the number of these point primary key lookups will be depend on the number of rows that match the condition ‘key_column=x’. You can see that there are a lot of random primary key lookups made.
With MRR, then steps above are changed to the following:
As you can see by utilizing the buffer for sorting the secondary key tuples by pk_column, we have converted a lot of point primary key lookups to one or more range primary key lookup. Thereby, converting Random access to one or more sequential access. There is one another interesting thing that has come up here, and that is the importance of the size of the buffer used for sorting the secondary key tuples. If the buffer size is large enough only a single range lookup will be needed, however if the buffer size is small as compared to the combined size of the secondary key tuples fetched, then the number of range lookups will be:
|
1 2 3 4 |
CEIL(S/N) where, S is the combined size of the secondary key tuples fetched, and N is the buffer size. |
In MySQL 5.6 the buffer size used by MRR can be controlled by the variable read_rnd_buffer_size, while MariaDB introduces a different variable to control the MRR buffer size mrr_buffer_size. Both buffer sizes default to 256K in MySQL 5.6 and MariaDB 5.5 respectively, which might be low depending on your scenario.
You can read more about the MRR optimization available in MySQL 5.6 here:
http://dev.mysql.com/doc/refman/5.6/en/mrr-optimization.html
and as available in MariaDB 5.5 here:
http://kb.askmonty.org/en/multi-range-read-optimization
Now let’s move on to the benchmarks, to see the difference in numbers.
For the purpose of this benchmark, I have used TPC-H Query #10 and ran it on TPC-H dataset (InnoDB tables) with a Scale Factor of 2 (InnoDB dataset size ~5G). I did not use Scale Factor of 40 (InnoDB dataset size ~95G), because the query was taking far too long to execute, ~11 hours in case of MySQL 5.5 and ~5 hours in case of MySQL 5.6 and MariaDB 5.5. Note that query cache is disabled during these benchmark runs and that the disks are 4 5.4K disks in Software RAID5.
Also note that the following changes were made in the MySQL config:
optimizer_switch=’index_condition_pushdown=off’
optimizer_switch=’mrr=on’
optimizer_switch=’mrr_sort_keys=on’ (only on MariaDB 5.5)
optimizer_switch=’mrr_cost_based=off’
read_rnd_buffer_size=4M (only on MySQL 5.6)
mrr_buffer_size=4M (only on MariaDB 5.5)
We have turned off ICP optimization for the purpose of this particular benchmark, because we want to see the individual affect of an optimization (where possible). Also note that we have turned off mrr_cost_based, this is because the cost based algorithm used to calculate the cost of MRR when the optimizer is choosing the query execution plan, is not sufficiently tuned and it is recommended to turn this off.
The query used is:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
select c_custkey, c_name, sum(l_extendedprice * (1 - l_discount)) as revenue, c_acctbal, n_name, c_address, c_phone, c_comment from customer, orders, lineitem, nation where c_custkey = o_custkey and l_orderkey = o_orderkey and o_orderdate >= '1993-08-01' and o_orderdate < date_add( '1993-08-01' ,interval '3' month) and l_returnflag = 'R' and c_nationkey = n_nationkey group by c_custkey, c_name, c_acctbal, c_phone, n_name, c_address, c_comment order by revenue desc LIMIT 20; |
Now let’s see how effective is MRR when the workload fits entirely in memory. For the purpose of benchmarking in-memory workload, the InnoDB buffer pool size is set to 6G and the buffer pool was warmed up, so that the relevant pages were already loaded in the buffer pool. Note that as mentioned at the start of the benchmark results section, the InnoDB dataset size is ~5G. Ok so now let’s take a look at the graph:
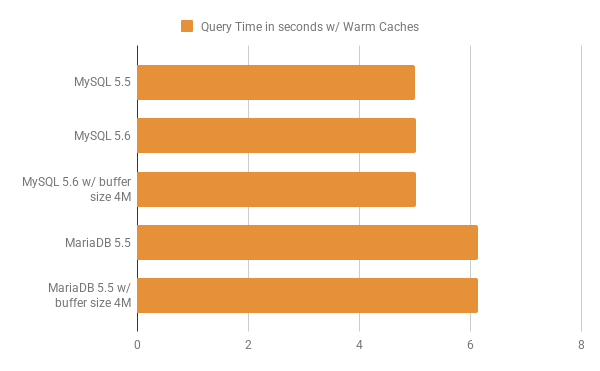
MRR doesn’t really make any positive difference to the query times for MySQL 5.6, when the workload fits entirely in memory, because there is no extra cost for memory access at random locations versus memory access at sequential locations. In fact there is extra cost added by the buffering step introduced by MRR, and hence, there is a slight increase in query time for MySQL 5.6, increase of 0.02s. But the query times for MariaDB 5.5 are greater than both MySQL 5.5 and MySQL 5.6
Now let’s see how effective is MRR when the workload is IO bound. For the purpose of benchmarking IO bound workload, the InnoDB buffer pool size is set to 1G and the buffer pool was not warmed up, so that it does not have the relevant pages loaded up already:
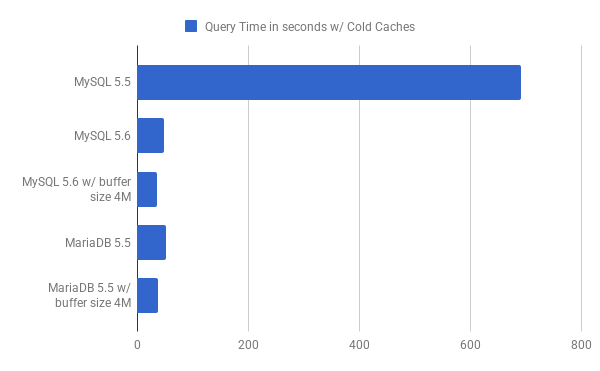
MRR does make a lot of difference when the workload is IO bound, the query time is decreased from ~11min to under a minute. The query time is reduced further when the buffer size is set to 4M. Note also that query time for MariaDB is still a little higher by a couple of seconds, when compared to MySQL 5.6.
Now let’s take a look at the status counters.
These status counters were captured when performing the benchmark on IO bound workload, mentioned above.
| Counter Name | MySQL 5.5 | MySQL 5.6 | MySQL 5.6 w/ read_rnd_bufer_size=4M | MariaDB 5.5 | MariaDB 5.5 w/ mrr_buffer_size=4M |
| Created_tmp_disk_tables | 1 | 1 | 1 | 1 | 1 |
| Created_tmp_tables | 1 | 1 | 1 | 1 | 1 |
| Handler_mrr_init | N/A | 0 | 0 | 1 | 1 |
| Handler_mrr_rowid_refills | N/A | N/A | N/A | 1 | 0 |
| Handler_read_key | 508833 | 623738 | 622184 | 508913 | 507516 |
| Handler_read_next | 574320 | 574320 | 572889 | 574320 | 572889 |
| Handler_read_rnd_next | 136077 | 136094 | 136366 | 136163 | 136435 |
| Innodb_buffer_pool_read_ahead | 0 | 20920 | 23669 | 20920 | 23734 |
| Innodb_buffer_pool_read_requests | 1361851 | 1264739 | 1235472 | 1263290 | 1235781 |
| Innodb_buffer_pool_reads | 120548 | 102948 | 76882 | 102672 | 76832 |
| Innodb_data_read | 1.84G | 1.89G | 1.53G | 1.89G | 1.53G |
| Innodb_data_reads | 120552 | 123872 | 100551 | 103011 | 77213 |
| Innodb_pages_read | 120548 | 123868 | 100551 | 123592 | 100566 |
| Innodb_rows_read | 799239 | 914146 | 912318 | 914146 | 912318 |
| Select_scan | 1 | 1 | 1 | 1 | 1 |
| Sort_scan | 1 | 1 | 1 | 1 | 1 |
Sometimes both for MariaDB 5.5 and MySQL 5.6, the optimizer chooses the wrong query execution plan. Let’s take a look at what are the good and bad query execution plans.
a. Bad Plan
|
1 2 3 4 5 |
id select_type table type possible_keys key key_len ref rows filtered Extra 1 SIMPLE nation ALL PRIMARY NULL NULL NULL 25 100.00 Using temporary; Using filesort 1 SIMPLE customer ref PRIMARY,i_c_nationkey i_c_nationkey 5 dbt3.nation.n_nationkey 2123 100.00 1 SIMPLE orders ref PRIMARY,i_o_orderdate,i_o_custkey i_o_custkey 5 dbt3.customer.c_custkey 7 100.00 Using where 1 SIMPLE lineitem ref PRIMARY,i_l_orderkey,i_l_orderkey_quantity PRIMARY 4 dbt3.orders.o_orderkey 1 100.00 Using where |
b. Good Plan
|
1 2 3 4 5 |
id select_type table type possible_keys key key_len ref rows filtered Extra 1 SIMPLE orders range PRIMARY,i_o_orderdate,i_o_custkey i_o_orderdate 4 NULL 232722 100.00 Using where; Rowid-ordered scan; Using temporary; Using filesort 1 SIMPLE customer eq_ref PRIMARY,i_c_nationkey PRIMARY 4 dbt3.orders.o_custkey 1 100.00 Using where 1 SIMPLE nation eq_ref PRIMARY PRIMARY 4 dbt3.customer.c_nationkey 1 100.00 1 SIMPLE lineitem ref PRIMARY,i_l_orderkey,i_l_orderkey_quantity PRIMARY 4 dbt3.orders.o_orderkey 2 100.00 Using where |
So during cold query runs the optimizer would switch to using plan ‘a’, which does not involve MRR, and the query time for MySQL 5.6 and MariaDB 5.5 jumps to ~11min (this is the query time for MySQL 5.5) While when it sticks to plan ‘b’ for MySQL 5.6 and MariaDB 5.5, then query times remain under a minute. So when the correct query execution plan is not used, there is no difference in query times between MySQL 5.5 and MySQL 5.6/MariaDB 5.5 This is another area of improvement in the optimizer, as it is clearly a part of the optimizer’s job to select the best query execution plan. I had noted a similar thing when benchmarking ICP, the optimizer made a wrong choice. It looks like that there is still improvement and changes needed in the optimizer’s cost estimation algorithm.
MariaDB 5.5 expands the concept of MRR to improve the performance of secondary key lookups as well. But this works only with joins and specifically with Block Access Join Algorithms. So I am not going to cover it here, but will cover it in my next post which will be on Block Access Join Algorithms.
There is a huge speedup when the workload is IO bound, the query time goes down from ~11min to under a minute. The query time is reduced further when buffer size is set large enough so that the index tuples fit in the buffer. But there is no performance improvement when the workload is in-memory, in fact MRR adds extra sorting overhead which means that the queries are just a bit slower as compared to MySQL 5.5 MRR clearly changes the access pattern to sequential, and hence InnoDB is able to do many read_aheads. Another thing to take away is that MariaDB is just a bit slower as compared to MySQL 5.6, may be something for the MariaDB guys to look at.
Resources
RELATED POSTS





Thanks for an interesting post!
Do you know if there are any plans to implement this in Percona Server 5.5, or will we have to wait for 5.6?
Thanks for interesting results!
The variation in query execution plans is probably a result of variation in InnoDB statistics. It is not much the Optimizer can do about that. In MySQL 5.6 you can use InnoDB Persistent Statistics to get stable statistics and plan stability. (See http://oysteing.blogspot.com/2011/05/innodb-persistent-statistics-save-day.html). You can also reduce the instability in earlier versions by increasing the amount of sampling used to compute the statistics. (See http://oysteing.blogspot.com/2011/04/more-stable-query-execution-time-by.html)
Oystein,
As benchmark show using MRR makes sense when data is not in memory. Do you have any plans to store information about how much of the table fits in memory ? It can be helpful for other choices too, for example full table scan vs index scan depends a lot whenever table is in memory or not.
Oystein and Peter,
MRR would also benefit a lot from a proper MRR cost calculation algorithm which it does not have at the moment and that’s why I had to set the optimizer switch mrr_cost_based=off And as Peter pointed out it would be great if the cost calculation would include how much of the data fits in memory for a particular query.
Hi Sigurd,
To answer your question, no we don’t currently have any plans to implement this in Percona Server 5.5.
Hi Stewart,
thanks for the quick reply!
‘@Peter: The optimizer cannot tell whether the data is in memory or not. That information needs to come from the storage engines. My idea is that the storage engines should take this into account when reporting the cost of operations (e.g., scan, look-up) to the optimizer.
@Ovais: Yes, the MRR cost-based calculation is definitely something that needs to be looked at.
Oystein,
Yes I understand Optimizer can’t know it alone. However it could be working with storage engine to get that information. I believe simple way to do it would be to use the same random dives trick Innodb uses – You can do 100 partial random dives in the index tree for each index, you either reach the leaf page in the buffer pool or you find one of the pages on your path is not in the buffer pool and so you stop just short of reading it. This would get you approximate in memory fit for each index and it can be refreshed every so often. Now of course it might not be enough for all cases as frequently you would have only some portion in memory, but it is the portion which is queried the most often.
hi ~ Ovais Tariq ,do you have dbt-3 Implementation document ?
mydbalife,
DBT3 is a decision support system type workload benchmark that is based on TPC-H. You can get more information about TPC-H here: http://www.tpc.org/tpch/ Btw, what exactly are you looking for?