
Migrate to Percona software for MySQL – an open source, production-ready, and enterprise-grade MySQL alternative.
This blog shares some column store database benchmark results and compares the query performance of MariaDB ColumnStore v.1.0.7 (based on InfiniDB), ClickHouse, and Apache Spark.
I’ve already written about ClickHouse.
The purpose of the benchmark is to evaluate how these three solutions perform on a single large server with many CPU cores and large amounts of RAM. All systems are massively parallel (MPP) databases, designed to utilize many cores for SELECT queries.
This post focuses on Wikipedia page counts. Other datasets will be covered separately.
All tests were run on a single server.
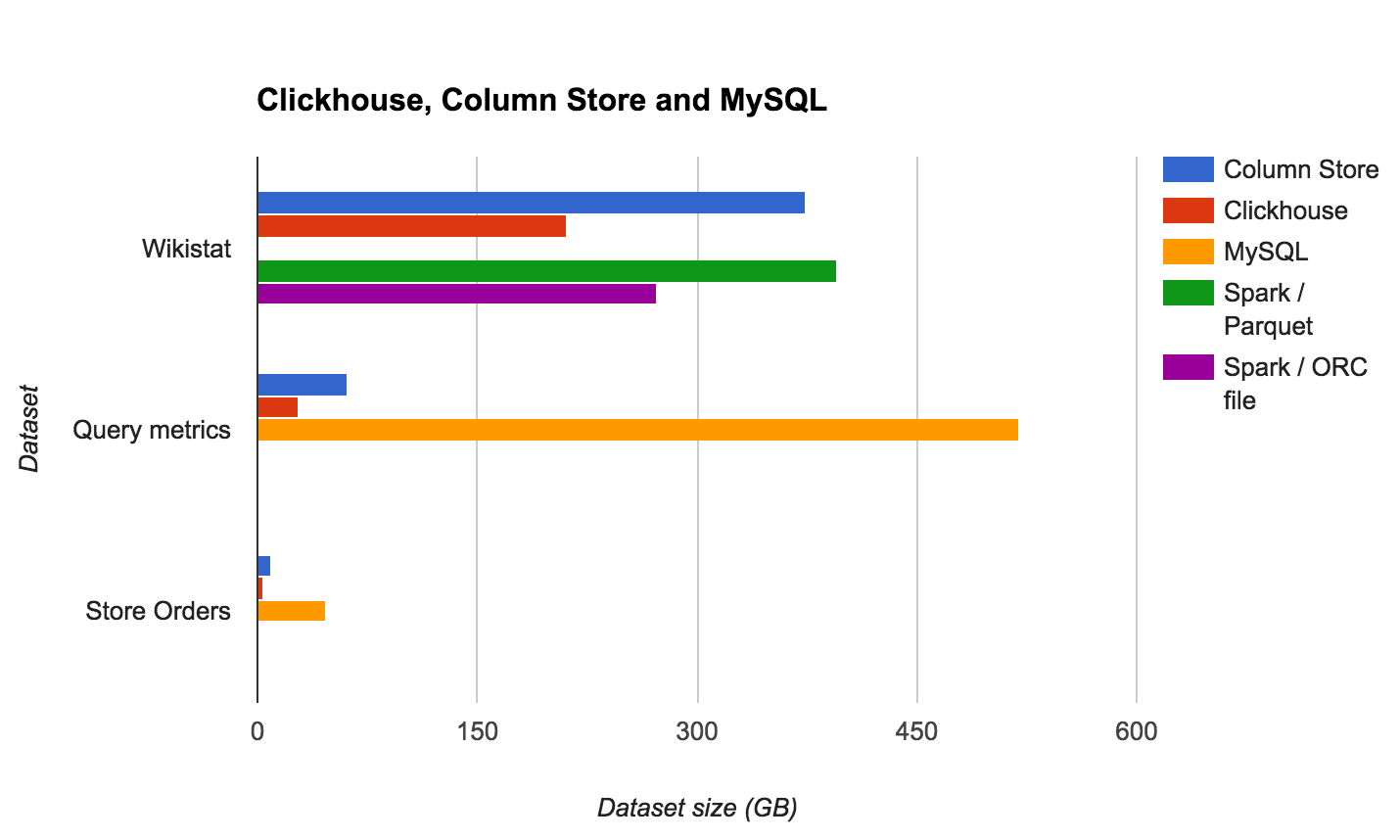
| Dataset | ColumnStore | ClickHouse | MySQL | Spark (Parquet) | Spark (ORC) |
|---|---|---|---|---|---|
| Wikistat | 374.24 GB | 211.3 GB | n/a (>2 TB) | 395 GB | 273 GB |
| Query metrics | 61.23 GB | 28.35 GB | 520 GB | ||
| Store Orders | 9.3 GB | 4.01 GB | 46.55 GB |
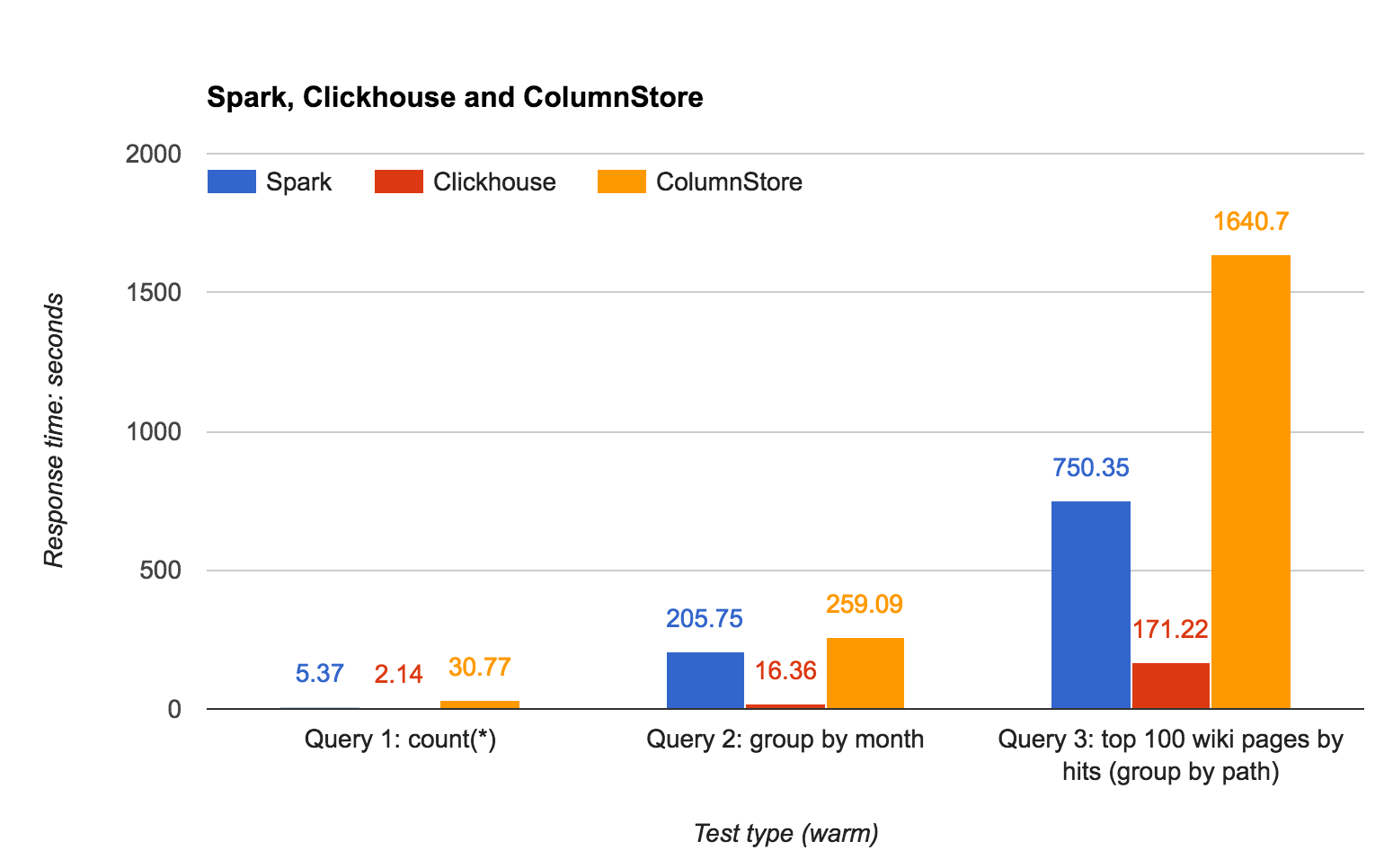
| Query | Spark | ClickHouse | ColumnStore |
|---|---|---|---|
| count(*) | 5.37 | 2.14 | 30.77 |
| group by month | 205.75 | 16.36 | 259.09 |
| top 100 pages | 750.35 | 171.22 | 1640.7 |
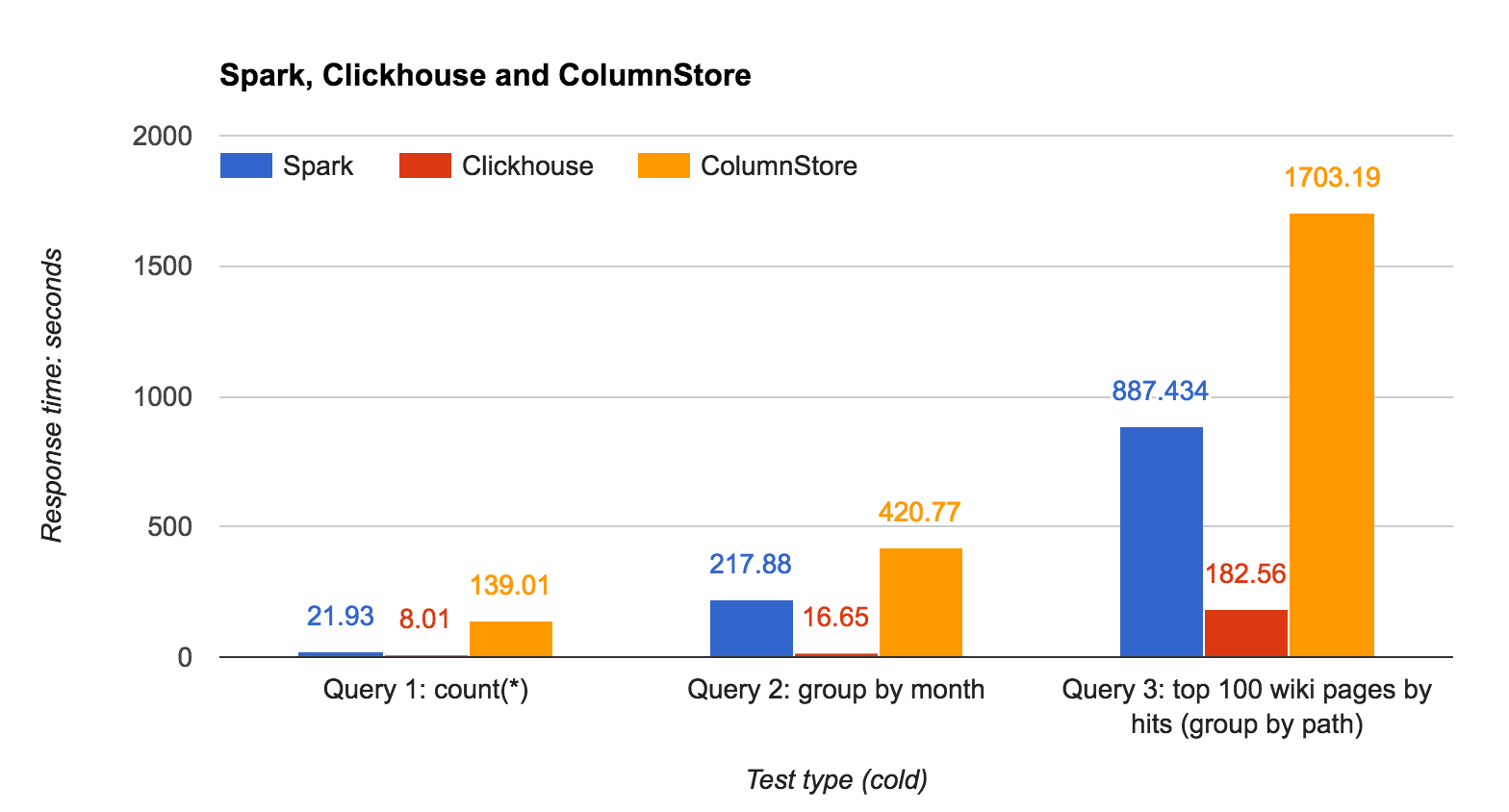
| Query | Spark | ClickHouse | ColumnStore |
|---|---|---|---|
| count(*) | 21.93 | 8.01 | 139.01 |
| group by month | 217.88 | 16.65 | 420.77 |
| top 100 pages | 887.43 | 182.56 | 1703.19 |
ClickHouse uses primary keys to scan only relevant data chunks:
|
1 2 3 4 |
SELECT count(*), toMonth(date) AS mon FROM wikistat WHERE toYear(date)=2008 AND toMonth(date)=1 GROUP BY mon; |
ColumnStore requires rewriting queries using date ranges for partition elimination:
|
1 2 3 4 |
SELECT count(*), month(date) AS mon FROM wikistat WHERE date BETWEEN '2008-01-01' AND '2008-01-31' GROUP BY mon; |
Large GROUP BY operations require significant memory due to hash table usage:
|
1 2 3 4 5 |
SELECT path, count(*), sum(hits) FROM wikistat GROUP BY path ORDER BY sum_hits DESC LIMIT 100; |
ColumnStore does not support disk spill for GROUP BY, so memory tuning may be required:
|
1 |
<NumBlocksPct>10</NumBlocksPct> |
| Feature | Spark | ClickHouse | ColumnStore |
|---|---|---|---|
| INSERT | Yes | Yes | Yes |
| UPDATE | No | No | Yes |
| DELETE | No | No | Yes |
| Window functions | Yes | No | Yes |
| Solution | Advantages | Disadvantages |
|---|---|---|
| MariaDB ColumnStore |
|
|
| ClickHouse |
|
|
| Apache Spark |
|
|
ClickHouse is the clear winner in this benchmark, showing significantly better performance and compression.
However, ColumnStore provides a MySQL-compatible interface, making it a strong option for migrations from MySQL.
|
1 2 3 4 5 6 7 8 9 |
CREATE TABLE wikistat ( date date, time datetime, project varchar(20), subproject varchar(2), path varchar(1024), hits bigint, size bigint ) ENGINE=Columnstore; |
|
1 |
select count(*) from wikistat; |
|
1 2 3 4 |
select count(*), month(date) as mon from wikistat where date between '2008-01-01' and '2008-10-31' group by mon; |
|
1 2 3 4 5 |
SELECT path, count(*), sum(hits) FROM wikistat GROUP BY path ORDER BY sum_hits DESC LIMIT 100; |
Resources
RELATED POSTS





I’ve been looking into different platforms to do analytics and this blog post makes me want to reconsider Clickhouse. What I don’t like about it it’s that apart of Yandex almost no one else is using it yet compared to hadoop based alternatives or MariaDB that I could easily get support in case I would have issues with them.
Also it would be really cool to see a performance comparison over multiple nodes to compare how well this different systems scale over a cluster.
Hello Luis,
as far as we can see, more than a hundred companies use ClickHouse. To make sure of this, simply join ClickHouse telegram chat or Google group. There you can ask any questions. The community and ClickHouse team responds promptly to them.
If you still need a support service, please leave your contacts at [email protected]
It is gathering popularity quickly here in Russia. For instance, we were switching to Spark from our legacy statistical system but immediately dumped everything we did after the clickhouse was released:
1) It is turned to be much quicker
2) The fact it is server greatly benifits us: free input source split. With spark you either creates a table with many columns which bad for readability and insert statement can be really long, thus error prone. Or parse these sources several times and this can be overly expensive at times. Not a problem with clickhouse.
3) With clickhouse you don’t just have naturally distributed log parsing. You naturally have continuous data, second by second, minute by minute, day by day available in the single source. With Spark you will struggle with http://stackoverflow.com/questions/38793170/appending-to-orc-file.
4) Clickhouse gives free to use realtime access to collected data. This is really useful in many circumstances. It is a great time saver sometimes.
5) It is fast as I said. Hadoop is slow to the extent you could need several hosts just to discover you match the speed of relational operations over GNU utils (awk, grep, sort, join) on the single host. Or rather not quite up to that speed. Hadoop is just too slow.
Good to see that is getting traction, I couldn’t find many information about people using it but maybe if I would search on yandex I would get better information.
I think it unfair to compare db with Spark. Spark is a very general tool. You can do pretty much everything: from data ingestion, cleaning, structuring up to the ML and GraphX modelling and finally streaming, even Natural Language Processing. Don’t forget about BigDL. I also work with highly instructed data. Spark is incredible. Spark is more like a functional programming language at scale. Yes, it is slower, but that is the tradeoff between functionality and speed. Me as a data scientist I don’t see any competitors to Spark.
Another side note: I don’t know how hard it is to scale clickhouse. I know that mongo requires a lot of engineering in order to scale. As for Spark I can easily install it on cluster myself.
Yes, it is a good point: Spark is a more general tool and not *just* MPP database. However, for the purposes of this blog post I wanted to see how fast Spark is able to just process data. If you are using other features of Apache Spark (i.e. ML) – those are of cause not available in Clickhouse and ColumnStore.
Thank you for very informative article.
It would be nice if the comparison also included the difficulty of installation, data loading and tuning.
There is no any mention about tuning. Does it mean that the databases were used “out of the box” with default settings?
Also, how well MariaDB ColumnStore, ClickHouse and Apache Spark are supported online,
I mean by Internet users? Could you find answers to your problems on the Internet?
thanks a lot
Clickhouse has no Update or Delete functionality. It is still super fast, but lack of Update/Delete is a serious limitation for many users.
I sure hope that Percona can bring ClickHouse into the MySQL protocol so that percona toolkit will work with it, as well as the PMM. Very interesting. (sure wish there was Window functions support as I now have a postgres instance for that!!!?? and sore miss percona toolkit)
You should look into ProxySQL to talk MySQL with ClickHouse: https://github.com/sysown/proxysql/wiki/ClickHouse-Support
comparing apples to oranges
Alex, I would love to see same comparison with Druid and Pinot, which seem to be more in the same league than ClickHouse. Have you considered these two? Any comments on’em?
This has already been done in https://medium.com/@leventov/comparison-of-the-open-source-olap-systems-for-big-data-clickhouse-druid-and-pinot-8e042a5ed1c7
very cool, clickhouse is very fast
potentially ClickHouse can be accessible via MySQL protocol using proxysql-clickhouse
https://github.com/sysown/proxysql/wiki/ClickHouse-Support
As of now Clickhouse also supports UPDATES / DELETES (as a form of “mutations”).
for systems as mentioned above, having a lot of data to be added, we are using columnstore as I can load a file with 50K lines into a large fact table seconds. is there any test / comparison for load times? can clickhouse load new data rapidly? for instance if I would like to add 20-50K lines per minute, is it capable of doing those data loads fast enough to avoid delays and locks?
Clickhouse supports UPDATE and DELETE, please update
https://www.altinity.com/blog/2018/10/16/updates-in-clickhouse