
A decade ago MySQL folks were in love with the concept of a relay slave for MySQL high availability across data centers. A relay is a single slave in a remote data center that receives replication from the global master and, in turn, replicates to all the other local slaves in that data center. This saved a lot of bandwidth, especially back in the days before memcached when scaling reads meant lots of slaves. Sending 20 copies of your replication stream cross-WAN gets expensive.
In Galera and Percona XtraDB Cluster (PXC), by default when a transaction commits on a given node it is sent to every other node in the cluster from that node. That is, the actual writeset payload (the RBR events) are sent over the network to every other node, so the bandwidth to replicate is roughly:
|
1 |
<writeset size> * (<number of nodes> - 1) |
If any of your nodes happen to be in a remote data center, the replication is still duplicated for each remote node, much like a master-slave topology without a relay.
To illustrate this I setup a 3 node PXC 5.6 cluster test environment: (it would work the same on PXC 5.5 and Galera 2.x)
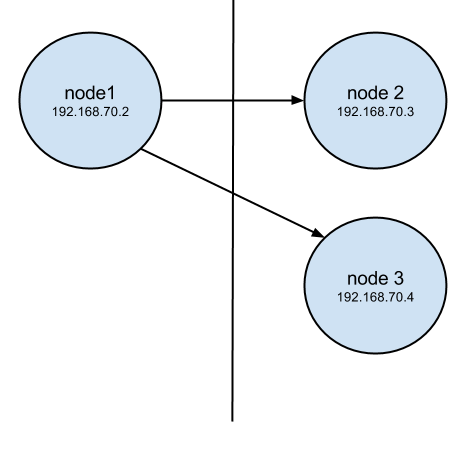
This isn’t the best design for HA, but let’s assume nodes 2 and 3 are in a remote data center. If I use some simple iptables ACCEPT rules in the OUTPUT chain, I can easily track the amount of bandwidth replication uses on each node in a simple 1 minute sysbench update-only test that writes only on node1:
|
1 2 3 4 5 6 7 8 9 10 |
pkts bytes target prot opt in out source destination node1: 24689 18M ACCEPT tcp -- any eth1 192.168.70.2 192.168.70.3 24389 18M ACCEPT tcp -- any eth1 192.168.70.2 192.168.70.4 node2: 24802 2977K ACCEPT tcp -- any eth1 192.168.70.3 192.168.70.2 20758 2767K ACCEPT tcp -- any eth1 192.168.70.3 192.168.70.4 node3: 22764 2871K ACCEPT tcp -- any eth1 192.168.70.4 192.168.70.2 20872 2772K ACCEPT tcp -- any eth1 192.168.70.4 192.168.70.3 |
We can see that node1 sends a full 18M of data to both node2 and node3. The traffic from nodes 2 and 3 between each other and back to node1 is group communication, you can think of it as replication acknowledgements and other cluster communication.
Galera 3 (available with PXC 5.6) introduces a new feature called WAN segments that basically implements the relay-slave concept, but in a more elegant way. To enable this, we simply assign each node in a given data center a common gmcast.segment integer in wsrep_provider_options. Each data center must have a distinct identifier and each node in that data center should have the same segment.
If we apply this configuration to our above environment where node1 is in gmcast.segment=1 and nodes 2 and 3 are in gmcast.segment=2, we get the following network throughput from the same 1 minute test:
|
1 2 3 4 5 6 7 8 9 10 |
pkts bytes target prot opt in out source destination node1: 20642 15M ACCEPT tcp -- any eth1 192.168.70.2 192.168.70.3 6088 317K ACCEPT tcp -- any eth1 192.168.70.2 192.168.70.4 node2: 19045 2368K ACCEPT tcp -- any eth1 192.168.70.3 192.168.70.2 33652 17M ACCEPT tcp -- any eth1 192.168.70.3 192.168.70.4 node3: 14682 2144K ACCEPT tcp -- any eth1 192.168.70.4 192.168.70.2 21974 2522K ACCEPT tcp -- any eth1 192.168.70.4 192.168.70.3 |
We can now clearly see that our replication is following this path, using node2 as a relay:
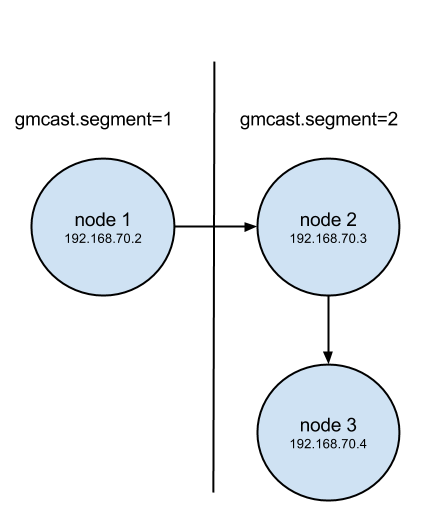
So our hypothetical WAN link here between segment 1 and segment 2 only needs a single copy of the replication stream instead of one per remote node.
But why is this better than a regular old async relay slave? It’s better because node2 was chosen dynamically to be the relay, I did not configure anything special besides the segment designation. The cluster could have just as easily chosen node3. If node2 failed, node3 will simply take over relay responsibilities (assuming there were more nodes).
Further, as I understand the feature, there’s nothing forcing all replication to get relayed through a single node in each segment. Any given transaction from any given node in the cluster might use any node in a given segment as a relay. The relaying is actually per-transaction and fully dynamic. No fuss, no muss.
Astute readers know that node1 still must ultimately get acknowledgement from all other nodes before responding to the client. When we are using segment relays, this should add some latency to commit time.
In my testing I was on a single virtual LAN, but my commit latency averages came out about pretty close. I also setup a WAN environment on AWS where node1 was in us-east-1 and nodes 2 and 3 were in us-west-1 and the difference in commit latency was effectively nil.
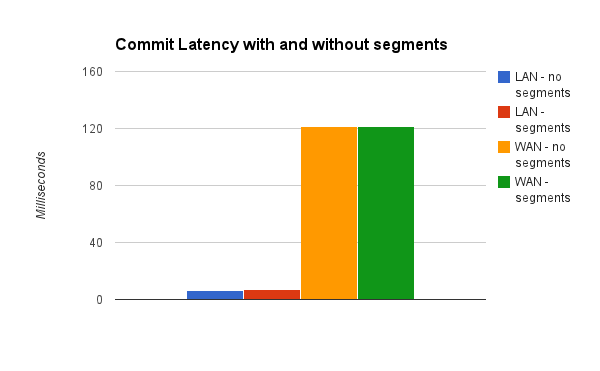
The additional latency is about 1ms in the LAN test case, these are 3 VMs on the same physical host, so there’s probably some additional overhead here in play. The high latency between the data centers fully masks the relaying overhead in a true WAN case.
Here are the raw results from the WAN tests:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
Sysbench run sysbench 0.5: multi-threaded system evaluation benchmark Running the test with following options: Number of threads: 8 Random number generator seed is 0 and will be ignored Threads started! OLTP test statistics: queries performed: read: 0 write: 3954 other: 0 total: 3954 transactions: 0 (0.00 per sec.) deadlocks: 0 (0.00 per sec.) read/write requests: 3954 (65.80 per sec.) other operations: 0 (0.00 per sec.) General statistics: total time: 60.0952s total number of events: 3954 total time taken by event execution: 480.4790s response time: min: 83.20ms avg: 121.52ms max: 321.30ms approx. 95 percentile: 169.67ms Threads fairness: events (avg/stddev): 494.2500/1.85 execution time (avg/stddev): 60.0599/0.03 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
Sysbench run sysbench 0.5: multi-threaded system evaluation benchmark Running the test with following options: Number of threads: 8 Initializing random number generator from seed (1). Threads started! OLTP test statistics: queries performed: read: 0 write: 3944 other: 0 total: 3944 transactions: 0 (0.00 per sec.) deadlocks: 0 (0.00 per sec.) read/write requests: 3944 (65.63 per sec.) other operations: 0 (0.00 per sec.) General statistics: total time: 60.0957s total number of events: 3944 total time taken by event execution: 480.1212s response time: min: 82.96ms avg: 121.73ms max: 226.33ms approx. 95 percentile: 166.85ms Threads fairness: events (avg/stddev): 493.0000/1.58 execution time (avg/stddev): 60.0151/0.03 |
I built my test environment on both local VMs and in AWS using an open source Vagrant environment you can find here: https://github.com/jayjanssen/pxc_testing/tree/5_6_segments (check the run_segments.sh script as well as the README.md and documentation for the submodule).
We’ve also released Percona Xtradb Cluster 5.6 RC1 with Galera 3.2 , the above Vagrant environment should pull the latest 5.6 build in automatically.





Very interesting feature, the outgoing bandwidth of the committing node can be saved with segment configuration.
Hi Jay,
What is the max writes per second you managed to achieve please, if you still remember ?
Thanks a lot in advance