
 Point-In-Time Recovery (PITR) for MySQL databases is an important feature that is essential and covers common use cases, like a recovery to the latest possible transaction or roll-back the database to a specific date before some bad query was executed. Percona Operator for MySQL based on Percona XtraDB Cluster (PXC) added support for PITR in version 1.7, and in this blog post we are going to look into the technical details and decisions we made to implement this feature.
Point-In-Time Recovery (PITR) for MySQL databases is an important feature that is essential and covers common use cases, like a recovery to the latest possible transaction or roll-back the database to a specific date before some bad query was executed. Percona Operator for MySQL based on Percona XtraDB Cluster (PXC) added support for PITR in version 1.7, and in this blog post we are going to look into the technical details and decisions we made to implement this feature.
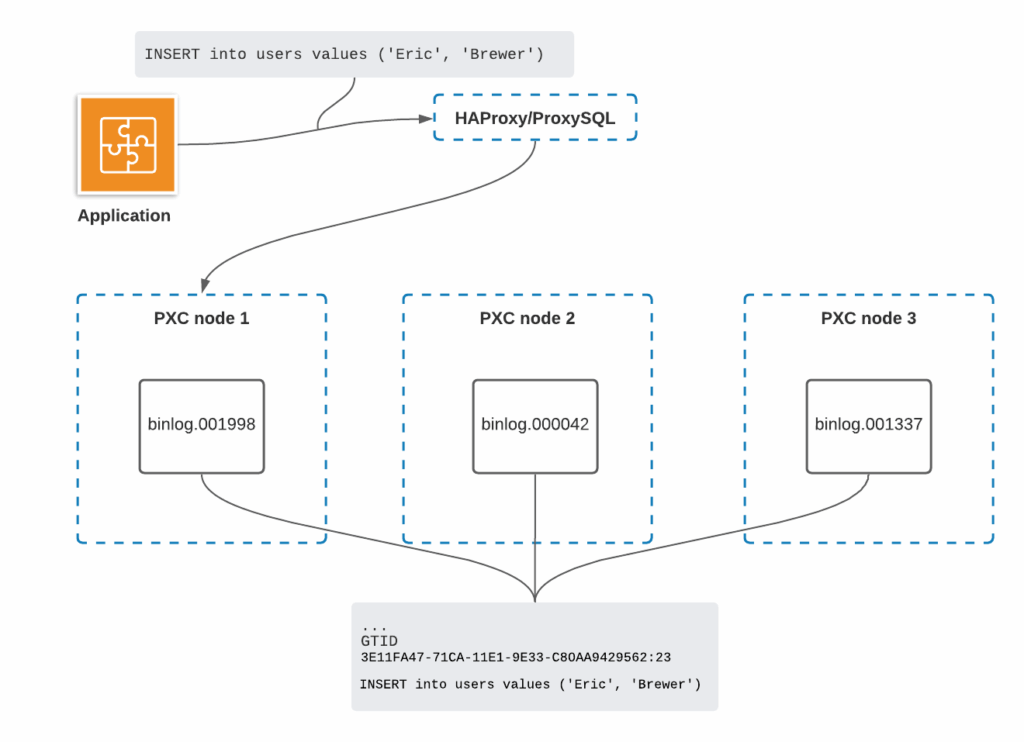
MySQL uses binary logs to perform point-in-time recovery. Usually, they are stored locally along with the data, but it is not an option for us:
We have decided to add a new Binlog Uploader Pod, which connects to the available PXC member and uploads binary logs to S3. Under the hood, it relies on the mysqlbinlog utility.
Binary logs on the clustered nodes are not synced and can have different names and contents. This becomes a problem for the Uploader, as it can connect to different PXC nodes for various reasons.
To solve this problem, we decided to rely on Global Transaction ID (GTID). It is a unique transaction identifier, but it is unique not only to the server on which it originated, but is unique across all servers in a given replication topology. With the GTID captured in binary logs, we can identify any transaction not depending on the filename or its contents. This allows us to continue streaming binlogs from any PXC member at any moment.
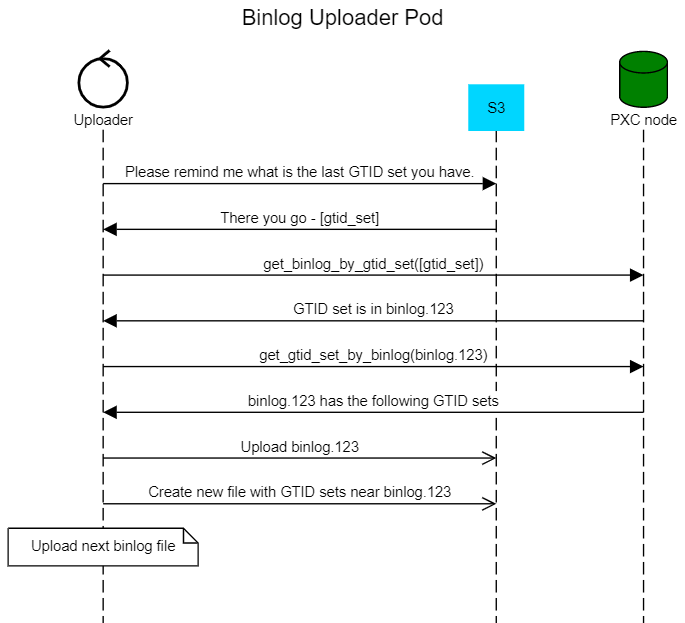
We have a unique identifier for every transaction, but the mysqlbinlog utility still doesn’t have the functionality to determine which binary log file contains which GTID. We decided to extend MySQL with few User Defined Functions and added them to Percona Server for MySQL and Percona XtraDB Cluster versions 8.0.21.
This function returns all GTIDs that are stored inside the given binlog file. We put the GTID setlist to a new file next to the binary log on S3.
This function takes GTID set as an input and returns a binlog filename which is stored locally. We use it to figure out which GTIDs are already uploaded and which binlog to upload next.
Our quality assurance team caught a bug before the release which can happen in the cluster only:
|
1 |
2021/01/19 11:23:19 ERROR: collect binlog files: get last uploaded binlog name by gtid set: scan binlog: sql: Scan error on column index 0, name "get_binlog_by_gtid_set('a8e657ab-5a47-11eb-bea2-f3554c9e5a8d:15')": converting NULL to string is unsupported |
The error is valid, as this node is new and there are no binary log files that have the GTID set that Uploader got from S3. If you look into this pull request, the quick patch is to always pick the oldest node in the array or in other words the node, which most likely would have the binary logs we need. In the next release of the Operator, we add more sophisticated logic, to discover the node which has the oldest binary logs for sure.
The size of binlogs depends on the cluster usage patterns, so it is hard to predict the size of the storage or memory required for them. We decided to take this complexity away by making our Binary Log Uploader Pod completely storageless. Mysqlbinlog can store remote binlog only into files, but we need to put them to S3. To get there we decided to use a named pipe or FIFO special file. Now mysqlbinlog utility loads the binary log file to a named pipe, our Uploader reads it and streams the data directly to S3.
Also, storageless design means that we never store any state between Uploader restarts. Basically, state is not needed, we only need to know which GTIDs are already uploaded and we have this data on a remote S3 bucket. Such design enables the continuous upload flow of binlogs.
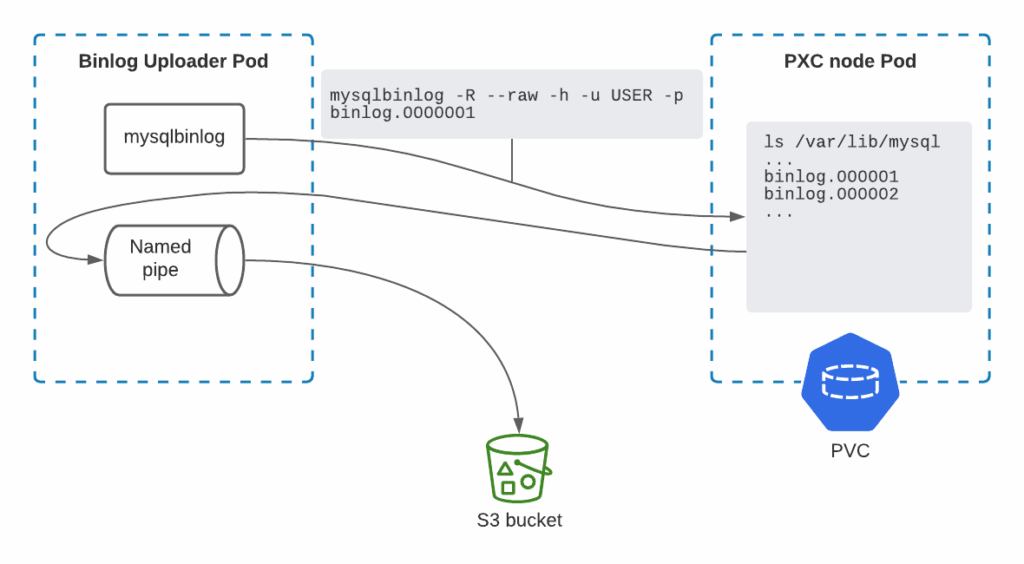
S3 protocol expects that the file is completely uploaded. If the file upload is interrupted (let’s say Uploader Pod is evicted), the file will not be accessible/visible on S3. Potentially we can lose many hours of binary logs because of such interruptions. That’s why we need to split the binlog stream into files and upload them separately.
One of the options that users can configure when enabling point-in-time recovery in Percona Operator for MySQL based on Percona XtraDB Cluster is timeBetweenUploads. It sets the number of seconds between uploads for Binlog Uploader Pod. By default, we set it to 60 seconds, but it can go down to one second. We do not recommend setting it too low, as every invocation of the Uploader leads to FLUSH BINARY LOGS command execution on the PXC node. We need to flush the logs to close the binary log file to upload it to external storage, but doing it frequently may negatively affect IO and as a result database performance.
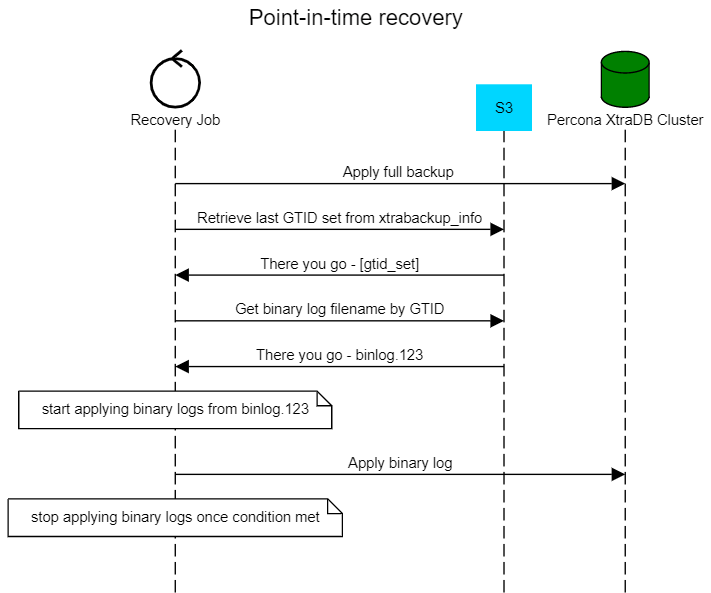
It is all about recovery and it has two steps:
We already have the functionality to restore from a full backup (see here), so let’s get to applying the binary logs.
First, we need to figure out from which GTID set we should start applying binary logs – in other words: where do we start?. As we rely on the Percona XtraBackup utility to take full MySQL backups, what we need to do is read the xtrabackup_info file which has lots of useful metadata. We already have this file on S3 near the full backup.
Second, find the binlog which has the GTID set we need. As you remember, we store a file with binlog’s GTID sets on S3 already, so it boils down to reading these files.
Third, download binary logs and apply them. Here we rely on mysqlbinlog as well, which has the flags we need, like –stop-datetime – which stops recovery when the event with a specific timestamp is caught in the log.
MySQL is more than 25 years old and has a great tooling ecosystem established around it, but as we saw in this blog post, not all these tools are cloud-native ready. Percona engineering teams are committed to providing users the same features across various environments, whether it is a bare-metal installation in the data center or cutting edge Kubernetes in the cloud.





Why are we doing it as UDF ? Would not it be more natural to extend mysqlbinlog to be able to extract this data ?
Hi Peter,
UDF is more or less easily portable between forks of MySQL.
Theoretically, any end-user on the internet can adapt UDF functions (for example) for upstream MySQL without rebuilding upstream MySQL from the sources.
We and end-users can build PITR systems that can work between forks of MySQL.
But does not it apply to mysqlbinlog as well which is separate tool ?
I’ve seen people using MariaDB mysqlbinlog (before MySQL an MariaDB became so different) to get some features only it contained ?
In any case it makes sense.
Peter we use mysqlbinlog -R (read-from-remote-server), so mysqlbinlog does not have access to the binary log files. So we needed an agent (in this case server itself) to find binary log file by GTID position