
 One of the questions you often will be faced with operating a Linux-based system is managing memory budget. If a program uses more memory than available you may get swapping to happen, oftentimes with a terrible performance impact, or have Out of Memory (OOM) Killer activated, killing process altogether.
One of the questions you often will be faced with operating a Linux-based system is managing memory budget. If a program uses more memory than available you may get swapping to happen, oftentimes with a terrible performance impact, or have Out of Memory (OOM) Killer activated, killing process altogether.
Before adjusting memory usage, either by configuration, optimization, or just managing the load, it helps to know how much memory a given program really uses.
If your system runs essentially a single user program (there is always a bunch of system processes) it is easy. For example, if I run a dedicated MySQL server on a system with 128GB of RAM I can use “used” as a good proxy of what is used and “available” as what can still be used.
|
1 2 3 4 |
root@rocky:/mnt/data2/mysql# free -h total used free shared buff/cache available Mem: 125Gi 88Gi 5.2Gi 2.0Mi 32Gi 36Gi Swap: 63Gi 33Mi 63Gi |
There is just swap to keep in mind but if the system is not swapping heavily, even there is swap space used, it usually keeps “unneeded junk” which does not need to factor in the calculation.
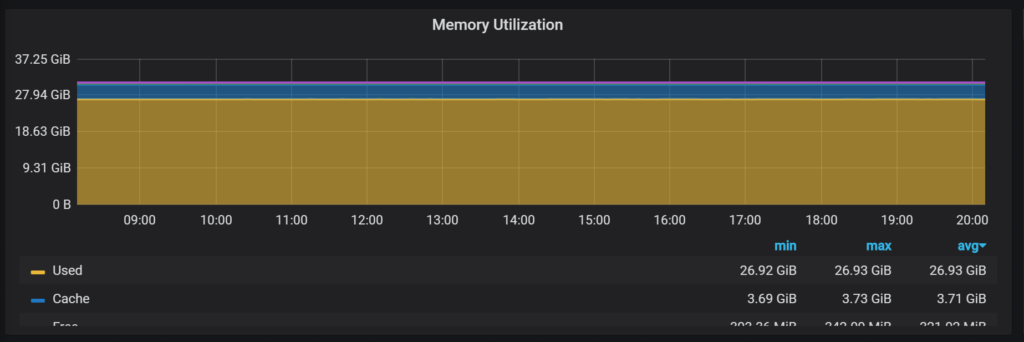
If you’re using Percona Monitoring and Management you will see it in Memory Utilization:
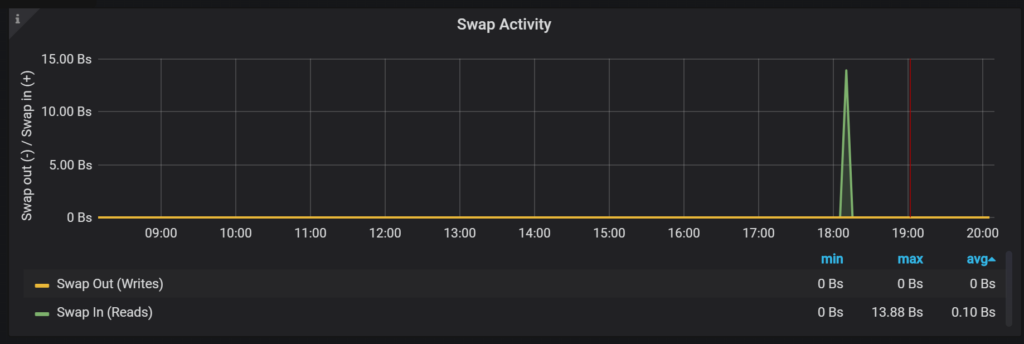
And in the Swap Activity graphs in the “Node Summary” dashboard:
If you’re running multiple processes that share system resources, things get complicated because there is no one-to-map mapping between “used” memory and process.
Let’s list just some of those complexities:
With that complexity in mind let’s look at the “top” output, one the most common programs to look at current load on Linux. By default, “top” sorts processes by CPU usage so we’ll press “Shift-M” to sort it by (resident) memory usage instead.
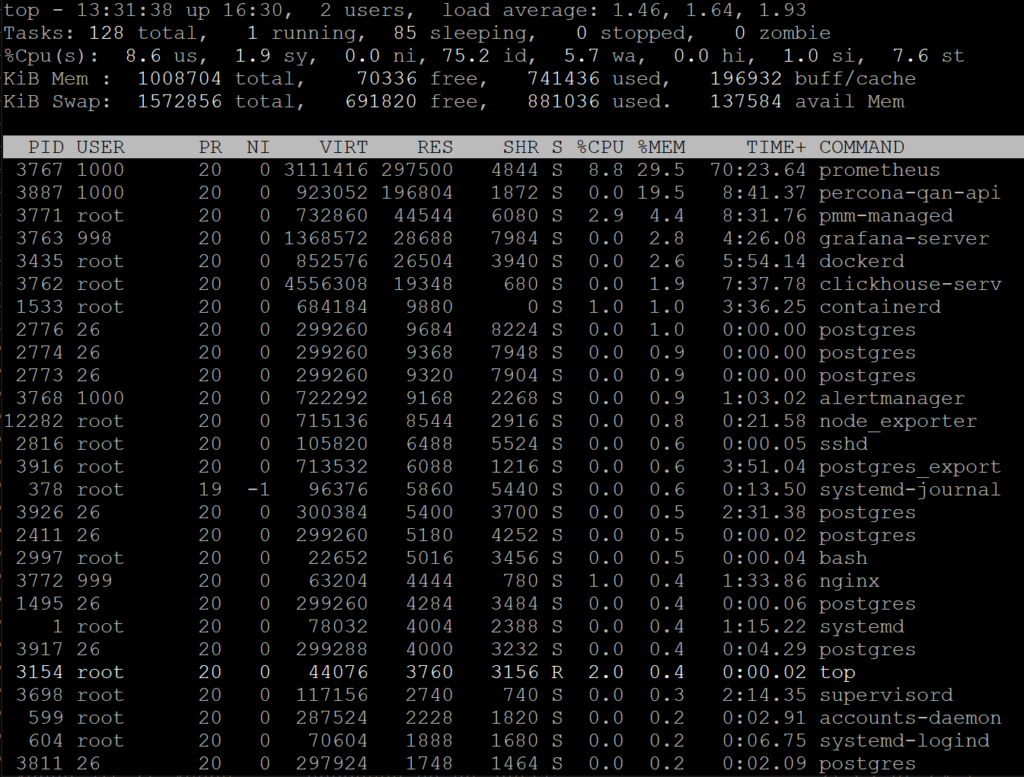
The first thing you will notice is that this system, which has only 1GB of physical memory, has a number of processes which has virtual memory (VIRT) in excess of 1GB.
For various reasons, modern memory allocators and programming languages (i.e. GoLang) can allocate a lot of virtual memory which they do not really use so virtual memory usage has little value to understand how much real memory a process needs to operate.
Now there is resident memory (RES) which shows us how much physical memory the process really uses. This is good… but there is a problem. Memory can be non-resident either because it was not really “used” and exists as virtual memory only, or because it was swapped out.
If we look into the stats kernel actually provides for the process we’ll see there is more data available:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
root@PMM2Server:~# cat /proc/3767/status Name: prometheus Umask: 0022 State: S (sleeping) Tgid: 3767 Ngid: 0 Pid: 3767 PPid: 3698 TracerPid: 0 Uid: 1000 1000 1000 1000 Gid: 1000 1000 1000 1000 FDSize: 256 Groups: 1000 NStgid: 3767 17 NSpid: 3767 17 NSpgid: 3767 17 NSsid: 3698 1 VmPeak: 3111416 kB VmSize: 3111416 kB VmLck: 0 kB VmPin: 0 kB VmHWM: 608596 kB VmRSS: 291356 kB RssAnon: 287336 kB RssFile: 4020 kB RssShmem: 0 kB VmData: 1759440 kB VmStk: 132 kB VmExe: 26112 kB VmLib: 8 kB VmPTE: 3884 kB VmSwap: 743116 kB HugetlbPages: 0 kB CoreDumping: 0 Threads: 11 SigQ: 0/3695 SigPnd: 0000000000000000 ShdPnd: 0000000000000000 SigBlk: fffffffe3bfa3a00 SigIgn: 0000000000000000 SigCgt: fffffffe7fc1feff CapInh: 00000000a80425fb CapPrm: 0000000000000000 CapEff: 0000000000000000 CapBnd: 00000000a80425fb CapAmb: 0000000000000000 NoNewPrivs: 0 Seccomp: 2 Speculation_Store_Bypass: vulnerable Cpus_allowed: 1 Cpus_allowed_list: 0 Mems_allowed: 00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000000,00000001 Mems_allowed_list: 0 voluntary_ctxt_switches: 346 nonvoluntary_ctxt_switches: 545 |
VmSwap is a particularly interesting data point, as it shows the amount of memory used by this process which was swapped out.
VmRSS+VmSwap is a much better indication of the “physical” memory the process needs. In the case above, it will be 1010MB, which is a lot higher than 284MB of resident set size but also a lot less than the 3038MB “virtual memory” size for this process.
The problem with the swapped out part, though we do not know if it was swapped out “for good” being dead weight, is, for example, some code or data which is not used in your particular program use case or if it was swapped out due to memory pressure, and we really would need to have it in real memory (RAM) for optimal performance – but we do not have enough memory available.
The helpful data point to look at in this case is major page faults. It is not in the output above but is available in another file – /proc/[pid]/stat. Here is some helpful information on Stack Overflow.
A high number of major page faults indicates the stuff program needs is not in physical memory. Swap activity will be included here but also references to currently unmapped code in the shared library or references to the data in memory-mapped files, which is currently not in RAM. In any case, a high rate of major page faults often indicates RAM pressure.
Let’s go to our friend “top”, though, and see if we can get more helpful information displayed in it. You can use the “F” keyboard shortcut to select fields you want to be displayed.
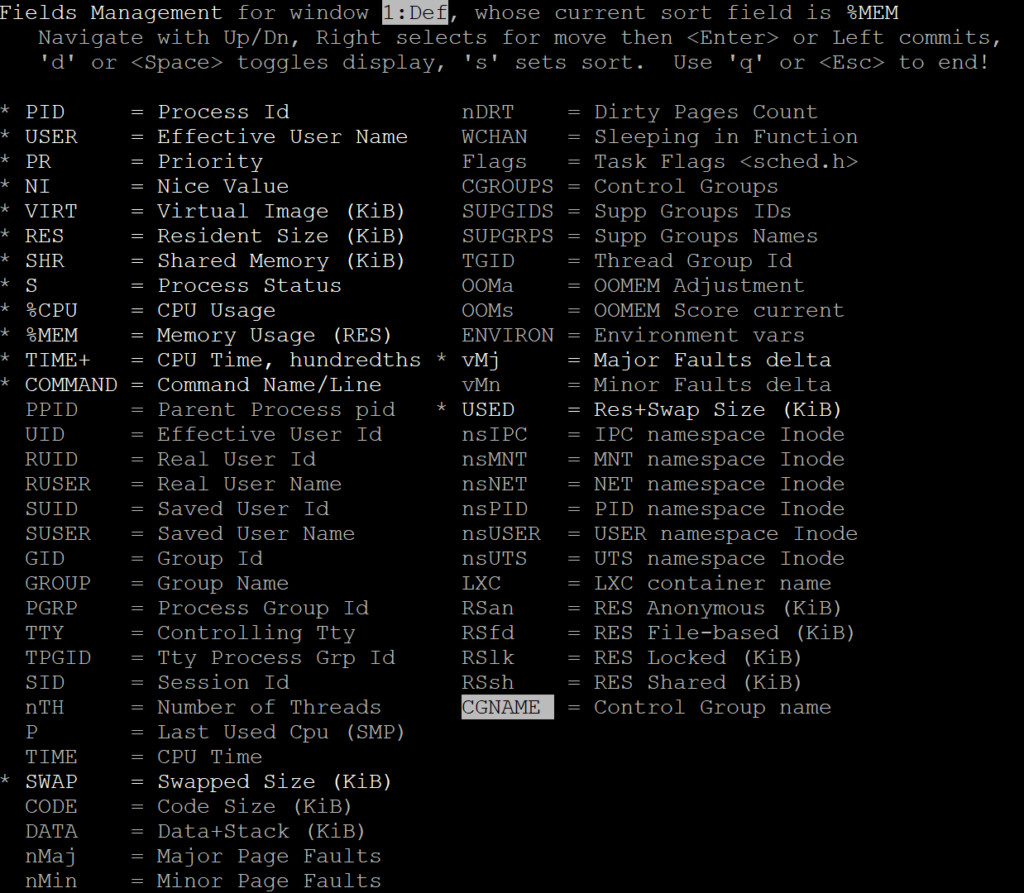
You can add SWAP, Major Faults Delta, and USED columns to display all the items we spoke about!
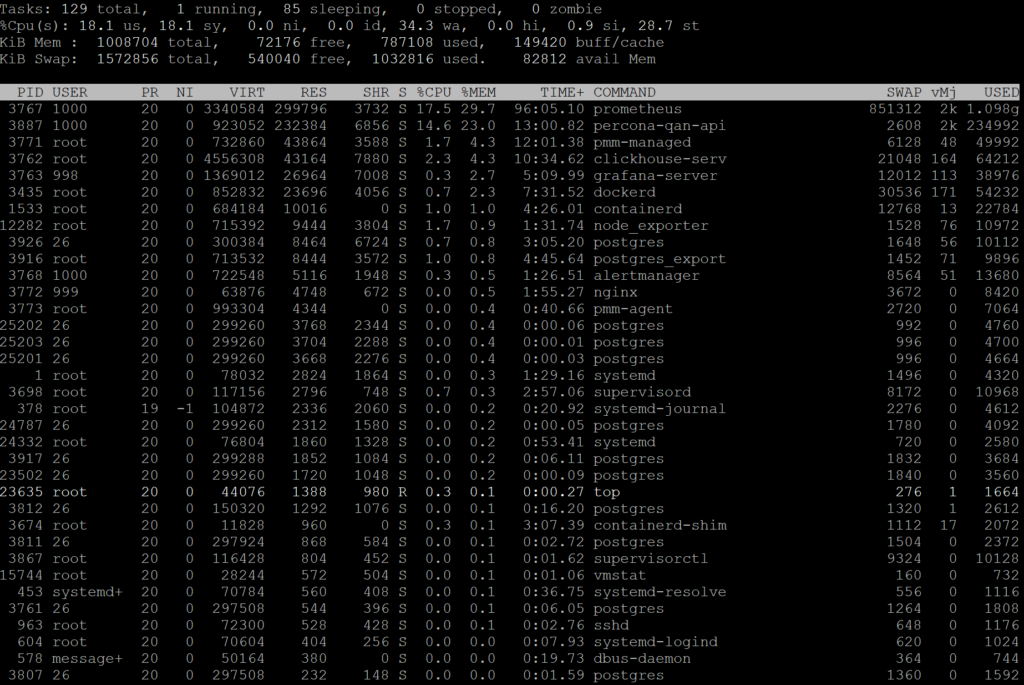
Looking at this picture we can see a large portion of “prometheus” process is swapped out and it has 2K major page faults/sec happening, pointing out the fact it is likely suffering.
The “clickhouse-serv” process is another interesting example, as it has over 4G “resident size” but has relatively little memory used and a lot less major page faults.
Finally, let’s look at “percona-qan-api” process which has a very small portion swapped out but shows 2K major page faults as well. I’m honestly not quite sure what it is, but it does not seem to be swap-IO related.
Want to see how much memory process is using? Do not look at virtual memory size or resident memory size but look at “used” memory defined as resident memory size + swap usage. Want to see if there is actual memory pressure? Check out system-wide swap input/output statistics, as well as major page fault rate, for a process you’re investigating.





Excellent article, as usual! Thank you!
Glad it was helpful!
Isn’t “clickhouse-serv” – VIRT is 4G not the “resident set”
Yep. For Clickhouse it tends to allocate a lot of Virtual Memory but not really use it.
Very informative..?
Definitely not all Linux distro’s are great at memory managing. It really depends on what the developers of a certain Linux desktop are going for? Nothing replaces the need for the proper amount of RAM to run what you do. RAM is the most efficient memory in a PC. Swap is OK if you have a decent type of storage memory that is fast. Otherwise, its a big handicap. I’ve seen some horrible results in RAM consumption from things like fractional scaling, and bad memory leak apps.