
 Recently I had the opportunity to test a storage device from ScaleFlux called CSD 2000. In this blog post, I will share the results of using it to run MySQL in comparison with an Intel device that had a similar capacity.
Recently I had the opportunity to test a storage device from ScaleFlux called CSD 2000. In this blog post, I will share the results of using it to run MySQL in comparison with an Intel device that had a similar capacity.
The answer is simple; it gives us built-in compression and atomic writes. For many workloads, but especially for database-type workloads, these are very important features.
Because of built-in compression, we can store more data on the ScaleFlux device than on a similar device with the same capacity.
Because of atomic writes, we can disable InnoDB Double Write buffer which means less writes/fsync on the disk layer. This should give us a performance advantage against non-atomic drives.
I ran many different tests on different data sizes, with different schemas.
In these tests, I was not trying to find the performance limits of the cards. I was comparing CSD 2000 against an Intel drive with the same storage capacity. My goal was to see what kind of performance I got from these cards using the same data and workload.
The drives used in these tests were:
Servers used in these tests were:
On the application server, we ran Sysbench which is a standard tool for MySQL benchmarks. On the database server, Percona Server for MySQL 8.0.19 ran with mostly default settings.
I also disabled binary, slow query logging, and adaptive hash. As you can see I used quite a small InnoDB Buffer Pool. Why? That was on purpose. Here I was comparing storage devices so there is no point having a huge Buffer Pool and serving the queries from memory. I wanted to hit the disk as many times as possible.
The only setting that I changed between the tests is the innodb_doublewrite, and I tested both drives with Double write disabled and enabled.
I have used the following settings:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
innodb_buffer_pool_size=8G innodb_log_file_size = 2G max_connections=500 slow_query_log=off disable_log_bin innodb_doublewrite=ON/OFF tmpdir = /var/lib/mysql/ innodb_adaptive_hash_index=off innodb_flush_method=O_DIRECT innodb_purge_threads=32 sync_binlog=0 max_prepared_stmt_count=4000000 |
First I ran the standard OLTP read_only, write_only, and read-write tests from Sysbench with the standard schema. Then I made small changes in the schema. I added two additional varchar fields with more realistic text, here is the new schema:
|
1 2 3 4 5 6 7 8 9 10 11 |
CREATE TABLE `sbtest1` ( `id` int NOT NULL AUTO_INCREMENT, `k` int NOT NULL DEFAULT '0', `c` char(120) NOT NULL DEFAULT '', `pad` char(60) NOT NULL DEFAULT '', `data1` varchar(255) DEFAULT NULL, `data2` varchar(255) DEFAULT NULL, PRIMARY KEY (`id`), KEY `k_1` (`k`), KEY `idx_data1` (`data1`) ) ENGINE=InnoDB AUTO_INCREMENT=9999948 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci |
data1 and data2 are the additional varchar fields, I used books from the Gutenberg project and loaded random lines from a book.
Why did I do that? Because this is where ScaleFlux drive positions itself. They claim if the data is compressible they can outperform the Intel drive. With these modifications the table was much more compressible – the compression ratio was around 2x.
I also added the following queries to the OLTP lua scripts to actually use these fields:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
index_updates = { "UPDATE %s%u SET k=?,data1=? WHERE id=?", t.INT,{t.CHAR,255},t.INT}, non_index_updates = { "UPDATE %s%u SET c=?,data2=? WHERE id=?", {t.CHAR,120},{t.CHAR,255},t.INT}, inserts = { "INSERT INTO %s%u (id, k, c, pad, data1, data2) VALUES (?, ?, ?, ?, ?, ?)", t.INT, t.INT, {t.CHAR, 120}, {t.CHAR, 60}, {t.CHAR,255}, {t.CHAR,255}}, index_selects = { "SELECT id,data2 FROM %s%u WHERE data1=?", {t.CHAR,255}}, update_based_on_data1 = { "UPDATE %s%u SET data2=? WHERE data1=?", {t.CHAR,255},{t.CHAR,255}}, |
The tests were executed against the following table configurations:
But enough talk! Let’s see some graphs…!
I am not going to show all the graphs from all the tests – I will just highlight the most important ones.
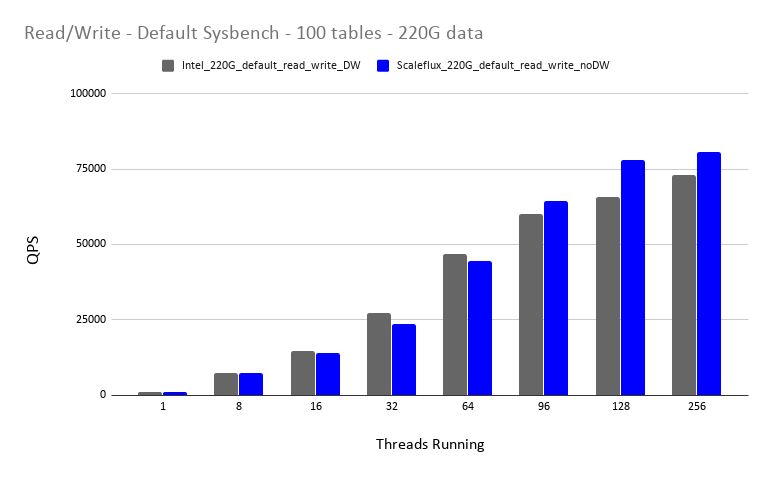
With Default schema and Sysbench we used 100 tables. Each table had 10M rows and the data size was roughly 220G. We can see that MySQL actually performs slightly better on the Intel drive, ScaleFlux only takes the lead at 96 threads. It is important to note that as the ScaleFlux drive is atomic, we disabled InnoDB Double Write Buffer. With the Intel drive, it is not recommended to do that, so we were using Double Write Buffer enabled.
In this test, we had the two additional varchar fields, which basically doubled our data size and made the data much more compressible. This is where ScaleFlux claims that their drive should perform better.
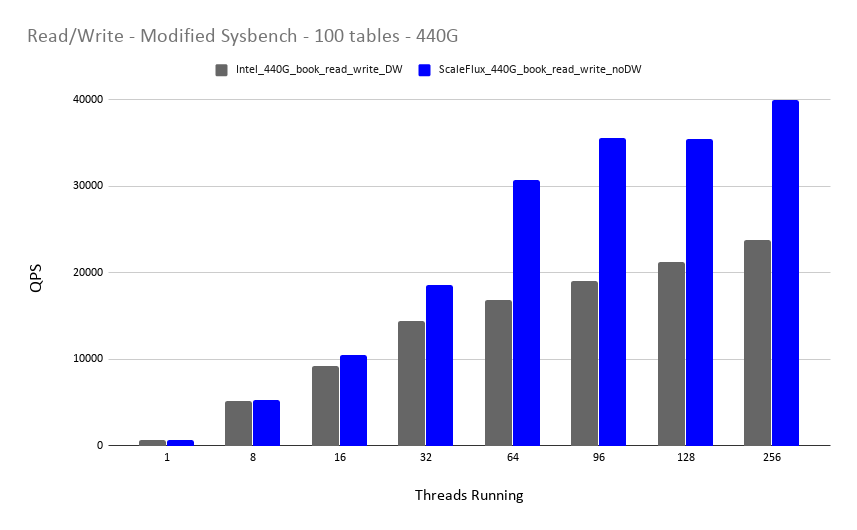
As claimed, MySQL clearly performs better on ScaleFlux when the dataset is more compressible. With higher thread numbers this is more obvious. But again, Double Write (aka DW) is disabled for ScaleFlux but not for intel – so let’s see how it looks for write-only workloads, when DW is disabled/enabled for both drives.
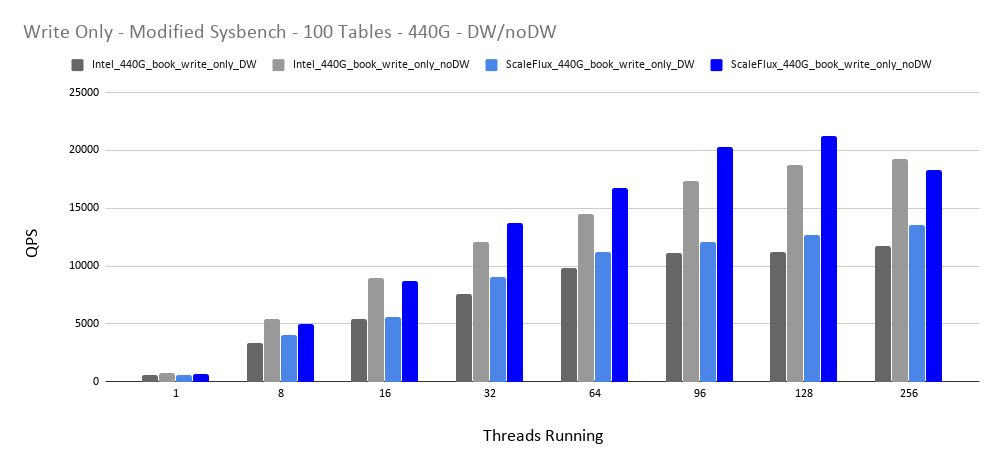
In both cases when Double Write is enabled for both drives, or when Double Write is disabled for both drives, MySQL performs better on the ScaleFlux drive. Remember, though, that we wouldn’t want to turn off Double Write when using any drive that doesn’t support Atomic Writes.
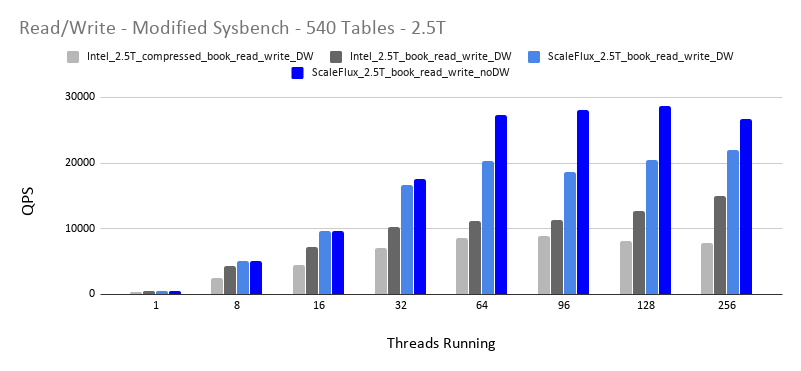
Both drives have 3.2T capacity and we used 2.5T on them. I also did an additional test here. I recreated all the tables with InnoDB table-level compression, as well on the Intel Drive. The graph shows that MySQL performs better on the ScaleFlux drive. One potential explanation could be the page cleaning. In SSD drives there is an internal garbage collector running if the drives reach a certain amount of used capacity.
Because ScaleFlux drive has built-in compression, and the data can compress around 2x, physically it only takes up around 1.4T space on the drive. As that is less than half of the drive capacity, garbage collection doesn’t kick in on ScaleFlux drive. The InnoDB table-level compression has a big performance impact compared even to Intel without compression.
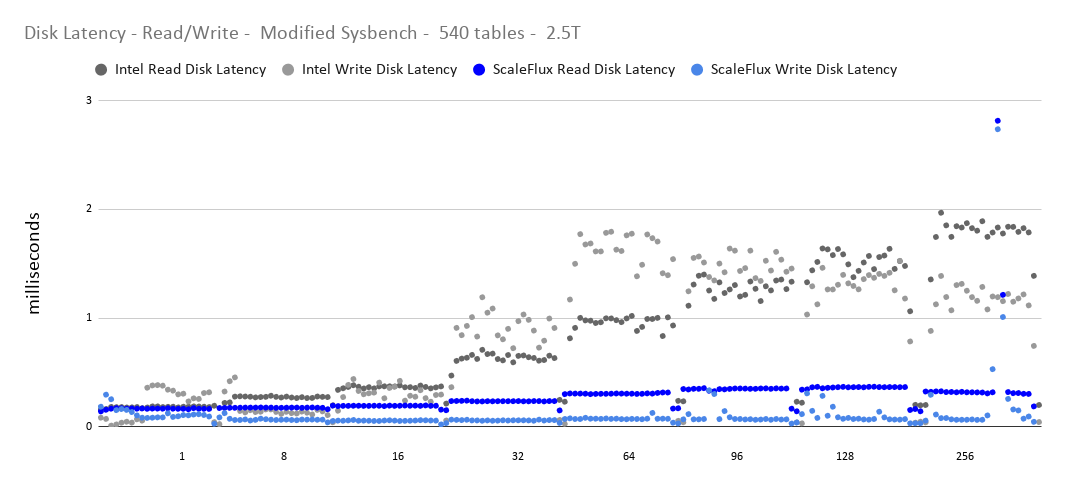
If we look at the disk latency reported by the Operating System for ScaleFlux it is quite steady, but we see a big jump in Intel.
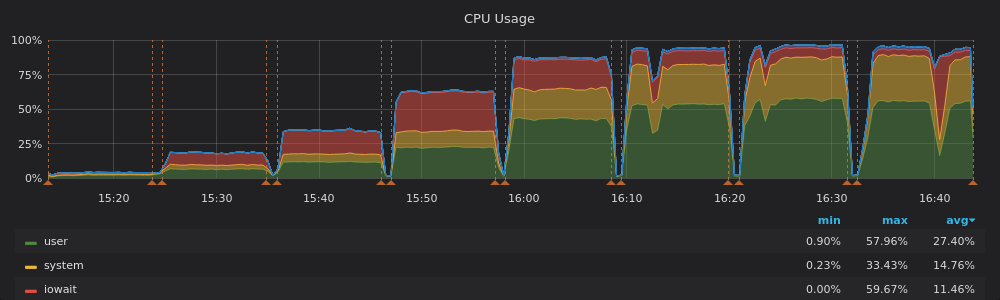
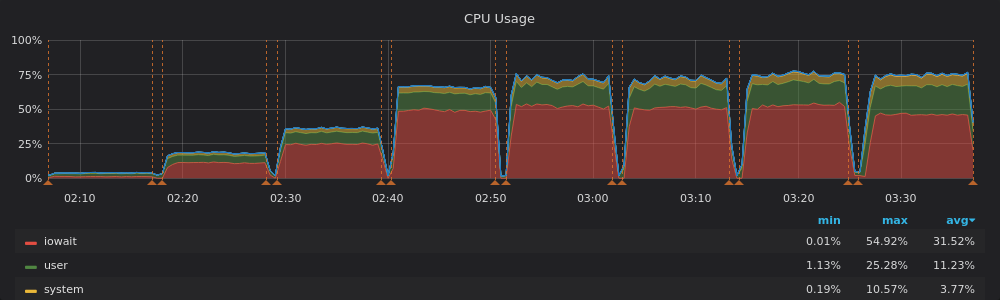
We also see much higher IOwait with the Intel drive. The server is just wasting resources by waiting for the IO.
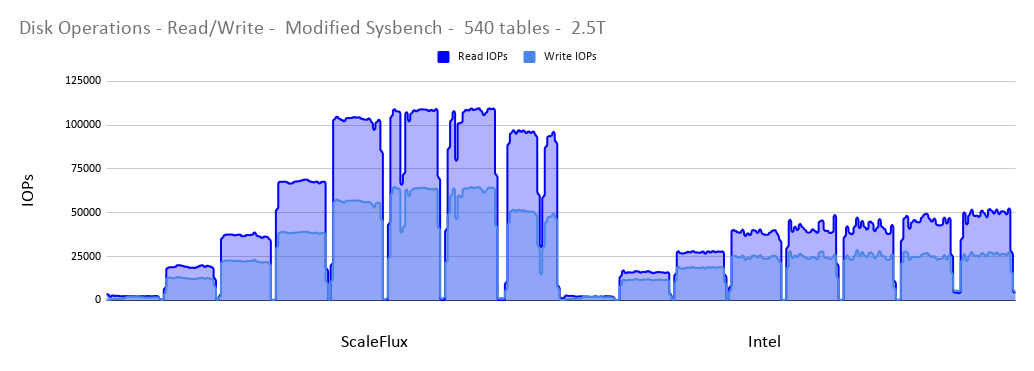
These are the disk operations that the OS reported during the test. We saw more IO operations on the ScaleFlux drive, but because MySQL performs more QPS this is expected. Performing more IOPs means MySQL can actually do more work. It can read and write more. We clearly see this in the next graph.
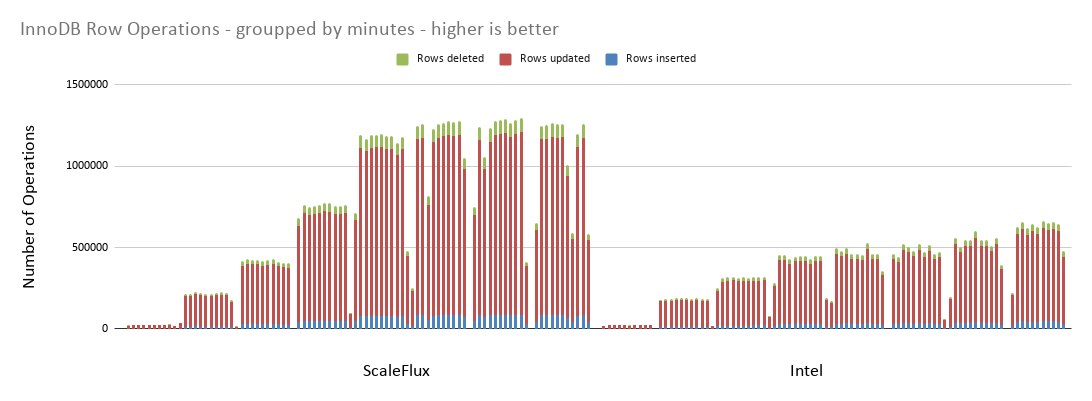 These numbers were collected from InnoDB – how many rows were inserted/updated/deleted per minute.
These numbers were collected from InnoDB – how many rows were inserted/updated/deleted per minute.
MySQL is able to perform almost twice as many write operations on the ScaleFlux drive than on the Intel one. As InnoDB does not have to double write the pages twice, it means it can perform more operations.
Based on my tests the ScaleFlux drive has real potential and they do what they claim. With a large compressible data size, it performs really well. However, as we could see in the first test, with a smaller data set that does not compress well, the Intel drive has a clear advantage.
If you would like more information on our testing and the results you can download our new whitepaper here. If anyone is using ScaleFlux drive in production I would like to hear the real-life experiences in the comments.
Also, stay tuned for our next blog post where we show you how can you write more than the Logical Capacity of the drive.
Download “Testing the Value of ScaleFlux Computational Storage Drive (CSD) for MySQL”





What does ScaleFlux need from the application (InnoDB) to guarantee that InnoDB page writes are atomic? Assume innodb_page_size=16kb and the filesystem page size is 4kb. What magic happens to communicate from InnoDB down to the device that the 4 4kb filesystem pages should be all written, or none must be written?
Hi Mark,
Thanks for your interest. Operating as a standard block device under Linux, ScaleFlux drive can guarantee the atomicity for each individual block layer write IO request (the request size can be up to 256KB in current implementation and can be easily increased if needed). Hence, to achieve the write atomicity for each 16KB InnoDB page without any changes to InnoDB and Linux IO stack, one must ensure that each 16KB InnoDB page entirely resides in one block layer write IO request. To meet this requirement, one needs to ensure two things: (1) each 16KB page spans over 4 consecutive LBAs (e.g., using ext4 bigalloc), and (2) InnoDB flushes each 16KB page through direct-io.
Tong Zhang @ ScaleFlux
Hi Tong,
I don’t see how EXT4 bigalloc + O_DIRECT could help you to guarantee atomicity for IO requests coming to your flash storage.. — on Linux implementation of O_DIRECT it’s only allowing the IO request to by-pass FS cache, but still there is absolutely no any guarantee that 16KB sent as a single write() will arrive at the end as a single IO operation. It may still be sent as several IO writes to the storage, so you could not know on the storage level what is really “atomic” — every 4K write or only 4x4K writes together as the whole (4K is only used as example here).. And if OS crash happens in the middle of these writes, which of them you’ll consider “finished” and which ones “partial” ?..
Rgds,
-Dimitri
Hi Dimitri,
Without using direct-io, there is certainly no guarantee that the four 4KB sectors in each 16KB InnoDB page will be flushed from the page cache altogether. When using direct-io, each 16KB page (over consecutive LBAs) reaches the block layer as a single request, and the block layer will encapsulate them in a single BIO and send it to the device driver. Yes, in theory the block layer could unnaturally break the contiguous 16KB data into multiple BIOs, but based on our study of the block layer source code, we could not find any circumstance under which the block layer could have such unnatural behavior. I would very much appreciate any your further comments in case we may have any misunderstanding.
Thanks,
Tong
Hi Tong,
if I recall well, there was a long research done by FB Devs who proved that BIO layer may even split a single 4K IO write into several 512 Bytes writes, so I can imagine only worse with 16KB.. — so, I’m sorry, but I’m not convinced you can guaranty atomic writes the way you’re proposing (there are many efforts made over a time by many vendors, but still nothing finalized)..
Rgds,
-Dimitri
Hi Dimitri,
Could you refer us to the FB research you mentioned? Or do you remember when the research was done? When block layer splits 4KB into multiple 512B BIOs, it means the underlying storage device is formatted as 512B sector size. If those 512B sectors do not span over continuous LBAs, of course they will be split into multiple IO requests. Based on our study on the block layer source code, we do not see any circumstance under which the block layer could split a single 16KB write over contiguous LBAs into multiple BIOs. To further verify, we have extensively run MySQL on our drive and never observe 16KB-split-into-multiple-BIOs under bigalloc+direct-io.
Thanks,
Tong
Hi Tong,
unfortunately I could not find FB paper now, but probably Mark Callaghan still have it somewhere ? (I think on that time he was still working at FB) — from the other side, pretty sure no one is formatting flash storage with 512 bytes sector size, generally it’s all 4K today..
P.S. seems like comments are already died on this site and “Reply” link is gone, so no idea on which thread this comment will arrive..
Rgds,
-Dimitri
Hi Dimitri,
Thanks for your quick response. I will meanwhile search for the FB paper and will post it here if we find it. If a drive is formatted with 4KB sector size, the block layer will never issue IO requests smaller than 4KB to the drive. Yeah, the “reply” disappears after couple rounds, because otherwise the text box will eventually looks like a column-store 🙂
Thanks,
Tong
Percona’s database has a DoubleWrite Buffer to protect against data loss and corruption, in which a set of data pages are pulled from a buffer pool and held in the DW buffer until they are correctly written to the final database tablespace. The CSD 2000 has an Atomic Write feature which renders the Double Write Buffer redundant and it can be turned off, speeding database writes. Intel’s P4610 has no atomic write feature.
ScaleFlux CSD 2000 drive internally carries out hardware-based per-4KB gzip compression/decompression on the IO path, which essentially serves for two purposes: (1) Reduce storage cost at zero CPU overhead. In-field deployments show that MySQL users can typically enjoy 2~5x storage cost reduction (or equivalently expand their dataset 2~5x without paying more money on storage). (2) Improve storage IO performance. By reducing the data volume being written/read to/from NAND flash memory chips, the in-drive transparent compression can improve the NAND flash memory resource utilization efficiency, leading to less garbage collection overhead and higher IO performance. Two birds with one stone.