
In my recent post Evaluating MongoDB Under Python TPCC 1000W Workload with MongoDB benchmarks, I showed an average throughput for a prolonged period of time (900sec or 1800sec), and the average throughput tended to smooth and hide problems.
But if we zoom in to 1-sec resolution for WiredTiger dashboard (Available in the Percona Monitoring and Management MongoDB dashboards), we can see the following:
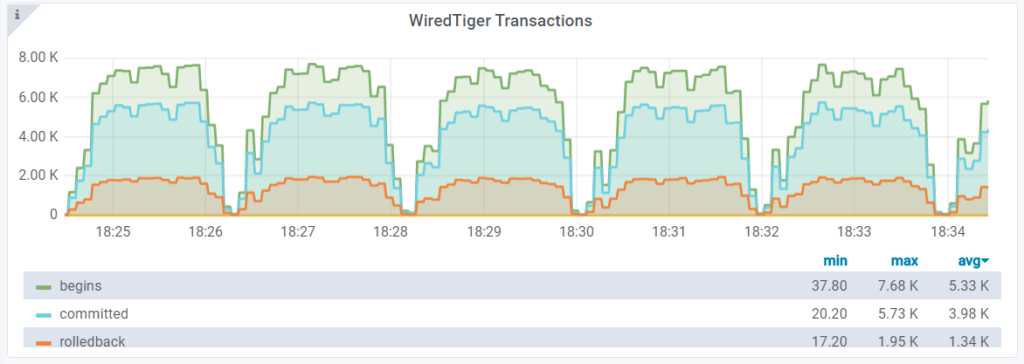
What we see here is that every 60 seconds, the throughput drops from ~7.5K op/s to ~40 op/s, which is about 1800 times, basically halting transaction processing.
What is the reason for this? It is WiredTiger checkpointing, which is configured to happen every 60 sec by default. We can confirm this with the Checkpoint Time dashboard.
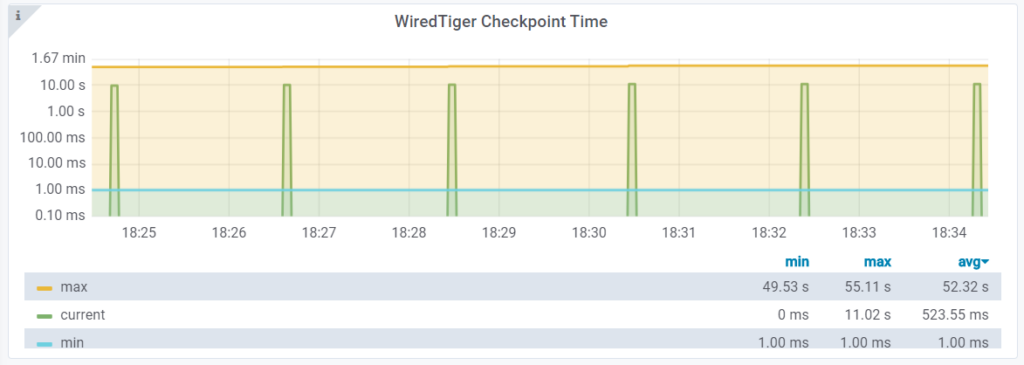
This is not the first time I have written about it. Actually, I brought up MongoDB checkpoint issues just about 5 years ago in my post Checkpoint strikes back. With more detailed results here: MongoDB sysbench-mongo benchmark
To be fair, we brought these issues for MySQL too. Initially, Peter described it 14 years ago in his post, Innodb Fuzzy checkpointing woes. Eventually, it was fixed in Percona Server for MySQL: MySQL 5.5.8 and Percona Server: being adaptive and brought to MySQL in later releases.
And recently Ivan Groenewold wrote about some tuning steps that may help to improve the situation in Tuning MongoDB for Bulk Loads.
So I also tried the workload above with the following settings:
db.adminCommand( { “setParameter”: 1, “wiredTigerEngineRuntimeConfig”: “eviction=(threads_min=20,threads_max=20),checkpoint=(wait=60),eviction_dirty_trigger=5,eviction_dirty_target=1,eviction_trigger=95,eviction_target=80″})
The result is:
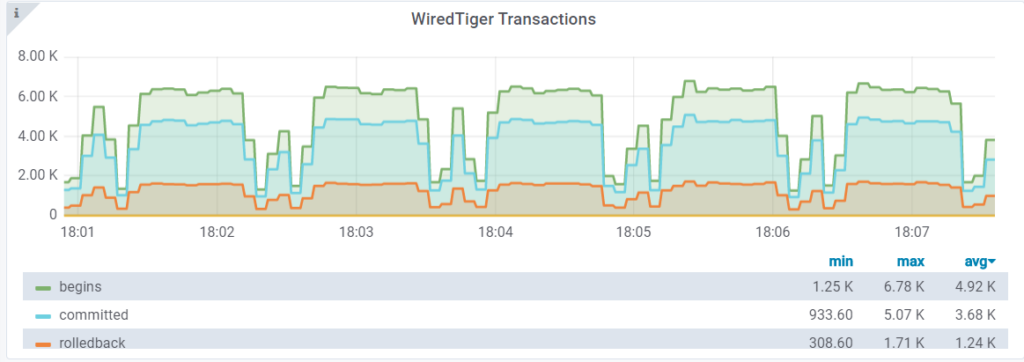
We can now see we are able to avoid complete stalls, by limiting the max throughput, and during checkpointing we go from 6.7K op/s to 1.25K op/s, but we still can’t fully eliminate the drops during checkpoint time. And I name this optimization “tuning by delaying clients queries”, and this is basically what is done here; we slow down clients’ queries, allowing the server to deal with dirty pages in the meantime.
The question which comes to mind: Should we try to fix this for Percona Server for MongoDB, as we did for InnoDB in MySQL before?





Hi Vadim. Which version is this latest post testing?
Daniel,
I did not mention version, as the issue persist for pretty much last 5 years, so all versions are affected.
In this particular case I used 4.2.7 version
Thanks for sharing, nice work! Have you tested with 30 seconds and 20 threads?