
 As the second part of the earlier post Give Love to Your SSDs – Reduce innodb_io_capacity_max! we wanted to put together some concepts on how InnoDB flushing works in recent Percona Server for MySQL versions (8.0.x prior to 8.0.19, or 5.7.x). It is important to understand this aspect of InnoDB in order to tune it correctly. This post is a bit long and complex as it goes very deep into some InnoDB internals.
As the second part of the earlier post Give Love to Your SSDs – Reduce innodb_io_capacity_max! we wanted to put together some concepts on how InnoDB flushing works in recent Percona Server for MySQL versions (8.0.x prior to 8.0.19, or 5.7.x). It is important to understand this aspect of InnoDB in order to tune it correctly. This post is a bit long and complex as it goes very deep into some InnoDB internals.
InnoDB internally handles flush operations in the background to remove dirty pages from the buffer pool. A dirty page is a page that is modified in memory but not yet flushed to disk. This is done to lower the write load and the latency of the transactions. Let’s explore the various sources of flushing inside InnoDB.
We already discussed the idle flushing in the previous post mentioned above. When there are no write operations, which means the LSN isn’t moving, InnoDB flushes dirty pages at the innodb_io_capacity rate.
This source of flushing is a slightly modified version of the old InnoDB flushing algorithm used years ago. If you have been around MySQL for a while, you probably don’t like this algorithm. The algorithm is controlled by these variables:
|
1 2 3 |
innodb_io_capacity (default value of 200) innodb_max_dirty_pages_pct (default value of 75) innodb_max_dirty_pages_pct_lwm (default value of 0 in 5.7 and 10 above 8.0.3) |
If the ratio of dirty pages over the total number of pages in the buffer pool is higher than the low water mark (lwm), InnoDB flushes pages at a rate proportional to the actual percentage of dirty pages over the value of Innodb_max_dirty_pages_pct multiplied by innodb_io_capacity. If the actual dirty page percentage is higher than Innodb_max_dirty_pages_pct, the flushing rate is capped at innodb_io_capacity.
The main issue with this algorithm is that it is not looking at the right thing. As a result, transaction processing may often freeze for a flush storm because the max checkpoint age is reached. Here’s an example from a post written by Vadmin Tkachenko back in 2011: InnoDB Flushing: a lot of memory and slow disk.
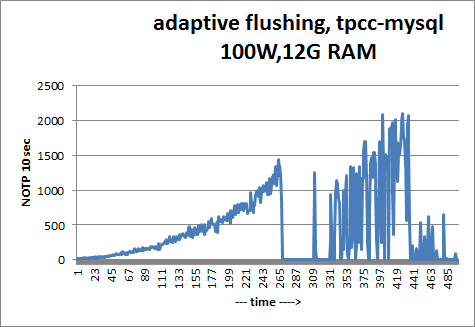
We can see a sharp drop in NOTP (New Order Transaction per second) at time = 265, and that’s because InnoDB reached the maximum checkpoint age and had to furiously flush pages. This is often called a flush storm. These storms freeze the write operations and are extremely bad for the database operation. For more details about flush storms, please see InnoDB Flushing: Theory and solutions.
To speed up reads and page creation, InnoDB tries to always have a certain number of free pages in each buffer pool instance. Without some free pages, InnoDB could need to flush a page to disk before it can load a new one.
This behavior is controlled by another poorly understood variable: innodb_lru_scan_depth. This is a pretty bad name for what the variable controls. Although the name makes sense if you look at the code, for a normal DBA the name should be innodb_free_pages_per_pool_target. At regular intervals, the oldest pages in the LRU list of each buffer pool instance is scanned (hence the name), and pages are freed up to the variable value. If one of these pages is dirty, it will be flushed before it is freed.
The adaptive flushing algorithm was a major improvement to InnoDB and it allowed MySQL to handle much heavier write load in a decent manner. Instead of looking at the number of dirty pages like the old algorithm, the adaptive flushing looks at what matters: the checkpoint age. The first adaptive algorithm that we are aware of came from Yasufumi Kinoshita in 2008 while he was working at Percona. The InnoDB plugin 1.0.4 integrated similar concepts, and eventually Percona removed its flushing algorithm because the upstream one was doing a good job.
The following description is valid for Percona Server for MySQL 8.0.18-. While we were busy writing this post, Oracle released 8.0.19 which introduces significant changes to the adaptive flushing code. It looks like a good opportunity for a follow-up post in the near future…
But let’s first take a small step back to put together some concepts. InnoDB stores rows in pages of normally 16KB. These pages are either on disk, in the data files, or in memory in the InnoDB buffer pool. InnoDB only modifies pages in the buffer pool.
Pages in the buffer pool may be modified by queries, and then they become dirty. At commit, the page modifications are written to the redo log, the InnoDB log files. After the write, the LSN (last sequence number) is increased. The dirty pages are not flushed back to disk immediately and are kept dirty for some time. The delayed page flushing is a common performance hack. The way InnoDB flushes its dirty pages is the focus of this post.
Let’s now consider the structure of the InnoDB Redo Log.
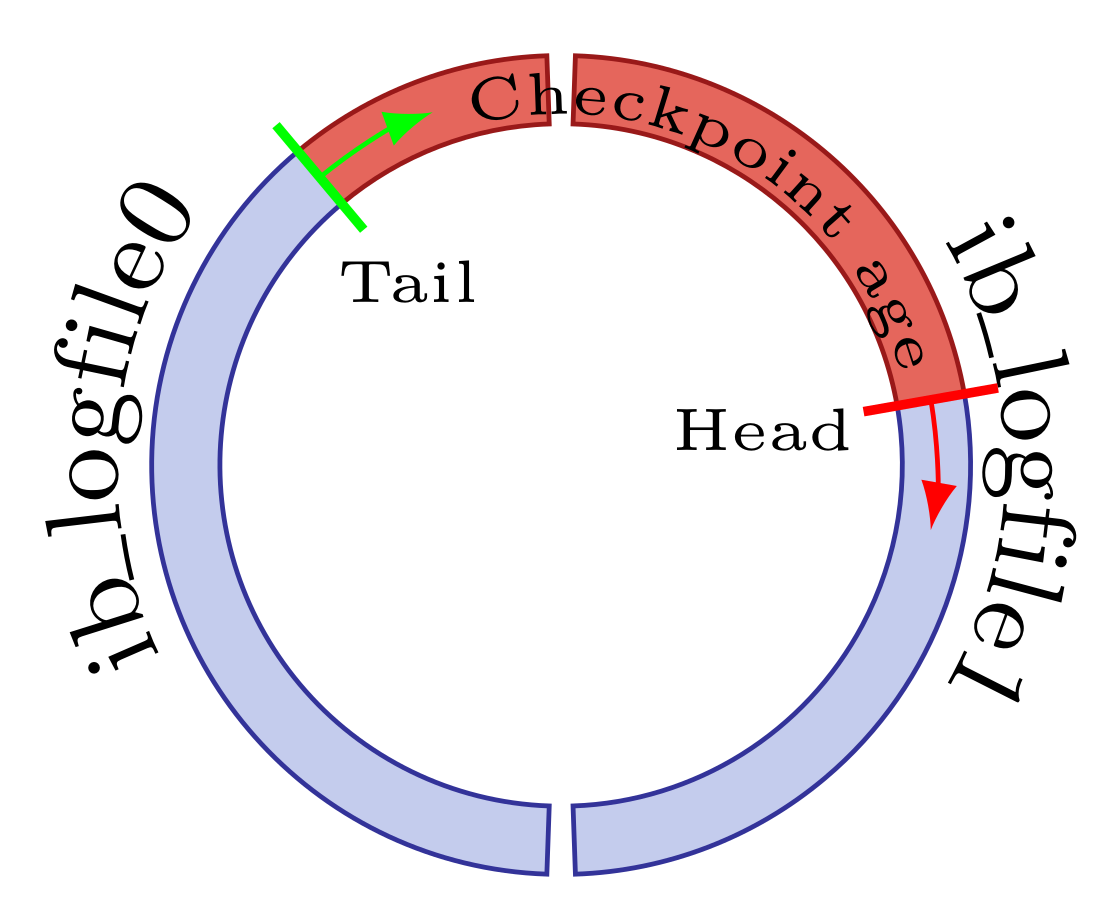
The InnoDB log files form a ring buffer containing unflushed modifications. The above figure shows a crude representation of the ring buffer. The Head points to where InnoDB is currently writing transactional data. The Tail points to the oldest unflushed data modification. The distance between the Head and Tail is the checkpoint age. The checkpoint age is expressed in bytes. The size and the number of log files determine the max checkpoint age, and the max checkpoint age is approximately 80% of the combined size of the log files.
Write transactions are moving the Head forward while page flushing is moving the Tail. If the Head moves too fast and there is less than 12.5% available before the Tail, transactions can no longer commit until some space is freed in the log files. InnoDB reacts by flushing at a high rate, an event called a Flush storm. Needless to say, flush storms should be avoided.
The adaptive flushing algorithm is controlled by the following variables:
|
1 2 3 4 5 6 7 |
innodb_adaptive_flushing (default ON) innodb_adaptive_flushing_lwm (default 10) innodb_flush_sync (default ON) innodb_flushing_avg_loops (default 30) innodb_io_capacity (default value of 200) innodb_io_capacity_max (default value of at least 2000) innodb_cleaner_lsn_age_factor (Percona server only, default high_checkpoint) |
The goal of the algorithm is to adapt the flushing rate (speed of the Tail) to the evolution of the checkpoint age (speed of the Head). It starts when the checkpoint age is above the adaptive flushing low water mark, by the default 10% of the max checkpoint age. Percona Server for MySQL offers two algorithms: Legacy and High Checkpoint.
The Legacy algorithm is given below. Notice the power of 3/2 on the age factor and the 7.5 denominator.
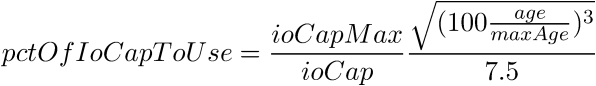
It also offers the High Checkpoint algorithm shown below:
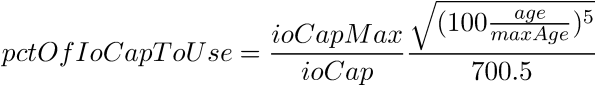
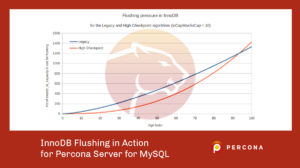
This time the age power factor is 5/2 and the denominator is 700.5. It is important to note that in both equations, innodb_io_capacity (ioCap) appears as the denominator in a ratio with innodb_io_capacity_max (ioCapMax). If we plot both equations together, we have:
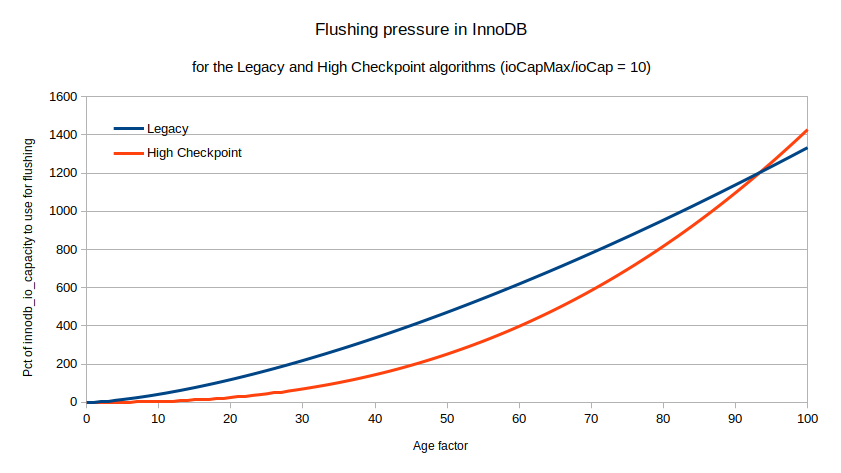
The graph has been generated for a ratio ioCapMax/ioCap of 10 like with the default values. The Percona High Checkpoint starts slowly but then it increases rapidly. This allows for more dirty pages (see the post we previously discussed) and it is normally good for performance. The returned percentage value can be much higher than 100.
So far, only the checkpoint age was used. While this is good, the goal of the algorithm is to flush pages in a way that the tail of the redo log ring buffer moves at about the same speed at the head. Approximately every innodb_flushing_avg_loops second, the rate of pages flushed and the progression of the head of the redo log is measured and the new value is averaged with the previous one. The goal here is to give some inertia to the algorithm, to damp the changes. A higher value of innodb_flushing_avg_loops makes the algorithm slower to react, while a smaller value makes it more reactive. Let’s call these quantities avgPagesFlushed and avgLsnRate.
Based on the avgLsnRate value, InnoDB scans the oldest dirty pages in the buffer pool and calculates the number of pages that are at less than avgLsnRate of the tail. Since this is calculated every second, the number of pages returned is what needs to be flushed to maintain the correct rate. Let’s call this number pagesForLsnRate.
We now have all the parts we need. The actual number of pages that will be flushed is given by:
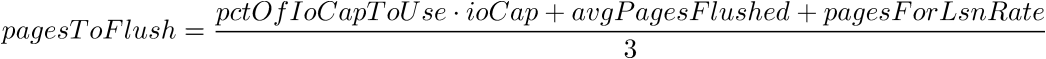
This quantity is then capped to ioCapMax. As you can see, pctOfIoCapToUse is multiplied by ioCap. If you look back at the equations giving pctOfIoCapToUse, they have ioCap at the denominator. The ioCap cancels out and the adaptive flushing algorithm is thus independent of innodb_io_capacity, as only innodb_io_capacity_max matters. There could also be more pages flushed if innodb_flush_neighbors is set.
Yes, if innodb_flush_sync is ON, InnoDB is authorized to go beyond if the max checkpoint age is reached or almost reached. If set to OFF, you’ll never go beyond innodb_io_capacity_max. If the latency of your read queries is critical, disabling innodb_flush_sync will prevent an IO storm, but at the expense of stalling the writes.
Error messages like
|
1 |
[Note] InnoDB: page_cleaner: 1000ms intended loop took 4013ms. The settings might not be optimal. (flushed=1438 and evicted=0, during the time.) |
are rather frequent. They basically mean the hardware wasn’t able to flush innodb_io_capacity_max pages per second. In the above example, InnoDB tried to flush 1,438 pages but the spinning disk is able to perform only 360 per second. Thus, the flushing operation which was supposed to take 1 second ended up taking 4 seconds. If you really think the storage is able to deliver the number of write iops stated by innodb_io_capacity_max, then it may be one of these possibilities:
Now that we understand how InnoDB flushes dirty pages to disk, the next obvious step is to tune it. InnoDB tuning will be covered in a follow-up post, so stay tuned.





This post is extremely relevant to me right now, Im struggling to prevent sharp checkpoints in a percona 5.6 server. I went through one round of attempting to simply increase log file sizes but I think I was simply moving the timing of the problem and creating a scenario where more dirty pages were allowed to pile up before the sharp checkpoint occurred.
This blog post discusses what I think I am seeing: https://www.percona.com/blog/2012/02/17/the-relationship-between-innodb-log-checkpointing-and-dirty-buffer-pool-pages/ “The checkpoint process is really a logical operation. It occasionally (as chunks of dirty pages get flushed) has a look through the dirty pages in the buffer pool to find the one with the oldest LSN, and that’s the Checkpoint. Everything older must be fully flushed.”
Is there any information about what triggers the ‘checkpoint process to find the [page] with the oldest lsn’ and how to impact that so its not so old and has less to flush? Im guessing the LRU parameter will be a good thing to tune for this.
‘@mtb2020, I just looked at the InnoDB code (5.7.28) and the checkpoint value is updated as part of the log_io_complete operation, so that’s every time the log files are written to. In your case, if I understand correctly, the flushing is too slow or occurs too late. Is the flushing speed, the number of pages written by InnoDB every second, matches io_cap_max? How many pending writes do you have?
Im seeing sharp checkpoints where all dirty pages are flushed and checkpoint age goes to 0. This was happening on a roughly daily basis when our logfile size was 1GB and now it happens roughly every 3 days after moving the logfile size to 10GB. It is not preceded by a metric hitting max_checkpoint_age, far from it.
Im unclear if this sharp checkpointing behavior is expected and im seeing a problem because my writes are slow and there too many dirty pages built up, or if people normally operate mysql in a state of fuzzy checkpointing where it never does this sharp checkpoint/full flush.
Im not sure if its because flushing is too slow or too late. Are those questions answered by any pre-existing PMM dashboards? I will check and maybe have to add some to answer further. No other existing dashboard seems to have a preceding indicator of this behavior, its not preceded by some large volume of database foreground or background activity that I can tell.
I was reaching a theory that flushing was too lazy and wasnt reaching into the older LSNs and whatever this ‘occasional logical operation where everything older must be flushed’ it found too much old stuff and flushed everything, but if that process is checking every time it writes to the logfile it doesnt make as much sense to me.
Ive since started to realize that it wasnt really a direct problem with innodb log file size being too small and have started exploring tuning other things (innodb_max_dirty_pct and lwm, innodb_adaptive_flushing_lwm mostly) to make flushing more aggressive and to kick in adaptive flushing with those large logfiles, and am seeing those changes affect the metrics for checkpoint age and dirty pages. Time will tell if the periodic full flush still happens after those changes.
Im guessing the follow up blogpost about tuning guidance will be very helpful to me as well!
This is relevant to us since, we are seeing a boost in performance on MySQL percona-server-5.6.27-76.0 by increasing lru_scan_depth in accordance to io_capacity. However, we still see periods in which buf_flush_lru_manager_thread sleeps for pretty good 2 mins while all other foreground threads are sleeping waiting on him.