
While implementing ClickHouse for query executions statistics storage in Percona Monitoring and Management (PMM), we were faced with a question of choosing the data type for metrics we store. It came down to this question: what is the difference in performance and space usage between Uint32, Uint64, Float32, and Float64 column types?
To test this, I created a test table with an abbreviated and simplified version of the main table in our ClickHouse Schema.
The “number of queries” is stored four times in four different columns to be able to benchmark queries referencing different columns. We can do this with ClickHouse because it is a column store and it works only with columns referenced by the query. This method would not be appropriate for testing on MySQL, for example.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
CREATE TABLE test ( digest String, db_server String, db_schema String, db_username String, client_host String, period_start DateTime, nq_UInt32 UInt32, nq_UInt64 UInt64, nq_Float32 Float32, nq_Float64 Float64 ) ENGINE = MergeTree PARTITION BY toYYYYMM(period_start) ORDER BY (digest, db_server, db_username, db_schema, client_host, period_start) SETTINGS index_granularity = 8192 |
When testing ClickHouse performance you need to consider compression. Highly compressible data (for example just a bunch of zeroes) will compress very well and may be processed a lot faster than incompressible data. To take this into account we will do a test with three different data sets:
Since it’s unlikely that an application will use the full 32 bit range, we haven’t used it for this test.
Another factor which can impact ClickHouse performance is the number of “parts” the table has. After loading the data we ran OPTIMIZE TABLE FINAL to ensure only one part is there on the disk. Note: ClickHouse will gradually delete old files after the optimize command has completed. To avoid these operations interfering with benchmarks, I waited for about 15 minutes to ensure all unused data was removed from the disk.
The amount of memory on the system was enough to cache whole columns in all tests, so this is an in-memory test.
Here is how the table with only one part looks on disk:
|
1 2 3 4 5 6 7 |
root@d01e692c291f:/var/lib/clickhouse/data/pmm/test_lc# ls -la total 28 drwxr-xr-x 4 clickhouse clickhouse 12288 Feb 10 20:39 . drwxr-xr-x 8 clickhouse clickhouse 4096 Feb 10 22:38 .. drwxr-xr-x 2 clickhouse clickhouse 4096 Feb 10 20:30 201902_1_372_4 drwxr-xr-x 2 clickhouse clickhouse 4096 Feb 10 19:38 detached -rw-r--r-- 1 clickhouse clickhouse 1 Feb 10 19:38 format_version.txt |
When you have only one part it makes it very easy to see the space different columns take:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
root@d01e692c291f:/var/lib/clickhouse/data/pmm/test_lc/201902_1_372_4# ls -la total 7950468 drwxr-xr-x 2 clickhouse clickhouse 4096 Feb 10 20:30 . drwxr-xr-x 4 clickhouse clickhouse 12288 Feb 10 20:39 .. -rw-r--r-- 1 clickhouse clickhouse 971 Feb 10 20:30 checksums.txt -rw-r--r-- 1 clickhouse clickhouse 663703499 Feb 10 20:30 client_host.bin -rw-r--r-- 1 clickhouse clickhouse 754848 Feb 10 20:30 client_host.mrk -rw-r--r-- 1 clickhouse clickhouse 238 Feb 10 20:30 columns.txt -rw-r--r-- 1 clickhouse clickhouse 9 Feb 10 20:30 count.txt -rw-r--r-- 1 clickhouse clickhouse 228415690 Feb 10 20:30 db_schema.bin -rw-r--r-- 1 clickhouse clickhouse 754848 Feb 10 20:30 db_schema.mrk -rw-r--r-- 1 clickhouse clickhouse 6985801 Feb 10 20:30 db_server.bin -rw-r--r-- 1 clickhouse clickhouse 754848 Feb 10 20:30 db_server.mrk -rw-r--r-- 1 clickhouse clickhouse 19020651 Feb 10 20:30 db_username.bin -rw-r--r-- 1 clickhouse clickhouse 754848 Feb 10 20:30 db_username.mrk -rw-r--r-- 1 clickhouse clickhouse 28227119 Feb 10 20:30 digest.bin -rw-r--r-- 1 clickhouse clickhouse 754848 Feb 10 20:30 digest.mrk -rw-r--r-- 1 clickhouse clickhouse 8 Feb 10 20:30 minmax_period_start.idx -rw-r--r-- 1 clickhouse clickhouse 1552547644 Feb 10 20:30 nq_Float32.bin -rw-r--r-- 1 clickhouse clickhouse 754848 Feb 10 20:30 nq_Float32.mrk -rw-r--r-- 1 clickhouse clickhouse 1893758221 Feb 10 20:30 nq_Float64.bin -rw-r--r-- 1 clickhouse clickhouse 754848 Feb 10 20:30 nq_Float64.mrk -rw-r--r-- 1 clickhouse clickhouse 1552524811 Feb 10 20:30 nq_UInt32.bin -rw-r--r-- 1 clickhouse clickhouse 754848 Feb 10 20:30 nq_UInt32.mrk -rw-r--r-- 1 clickhouse clickhouse 1784991726 Feb 10 20:30 nq_UInt64.bin -rw-r--r-- 1 clickhouse clickhouse 754848 Feb 10 20:30 nq_UInt64.mrk -rw-r--r-- 1 clickhouse clickhouse 4 Feb 10 20:30 partition.dat -rw-r--r-- 1 clickhouse clickhouse 400961033 Feb 10 20:30 period_start.bin -rw-r--r-- 1 clickhouse clickhouse 754848 Feb 10 20:30 period_start.mrk -rw-r--r-- 1 clickhouse clickhouse 2486243 Feb 10 20:30 primary.idx |
We can see there are two files for every column (plus some extras), and so, for example, the Float32 based “number of queries” metric store takes around 1.5GB.
You can also use the SQL queries to get this data from the ClickHouse system tables instead:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 |
SELECT * FROM system.columns WHERE (database = 'pmm') AND (table = 'test') AND (name = 'nq_UInt32') Row 1: ────── database: pmm table: test name: nq_UInt32 type: UInt32 default_kind: default_expression: data_compressed_bytes: 7250570 data_uncompressed_bytes: 1545913232 marks_bytes: 754848 comment: is_in_partition_key: 0 is_in_sorting_key: 0 is_in_primary_key: 0 is_in_sampling_key: 0 compression_codec: 1 rows in set. Elapsed: 0.002 sec. SELECT * FROM system.parts WHERE (database = 'pmm') AND (table = 'test') Row 1: ────── partition: 201902 name: 201902_1_372_4 active: 1 marks: 47178 rows: 386478308 bytes_on_disk: 1401028031 data_compressed_bytes: 1390993287 data_uncompressed_bytes: 29642900064 marks_bytes: 7548480 modification_time: 2019-02-10 23:26:20 remove_time: 0000-00-00 00:00:00 refcount: 1 min_date: 0000-00-00 max_date: 0000-00-00 min_time: 2019-02-08 14:50:32 max_time: 2019-02-08 15:58:30 partition_id: 201902 min_block_number: 1 max_block_number: 372 level: 4 data_version: 1 primary_key_bytes_in_memory: 4373363 primary_key_bytes_in_memory_allocated: 6291456 database: pmm table: test engine: MergeTree path: /var/lib/clickhouse/data/pmm/test/201902_1_372_4/ 1 rows in set. Elapsed: 0.003 sec. |
Now let’s look at the queries
We tested with two queries. One of them – we’ll call it Q1 – is a very trivial query, simply taking the sum across all column values. This query needs only to access one column to return results so it is likely to be the most impacted by a change of data type:
|
1 2 |
SELECT sum(nq_UInt32) FROM test |
The second query – which we’ll call Q2 – is a typical ranking query which computes the number of queries per period and then shows periods with the highest amount of queries in them:
|
1 2 3 4 5 6 7 |
SELECT sum(nq_UInt32) AS cnt, period_start FROM test GROUP BY period_start ORDER BY cnt DESC LIMIT 10 |
This query needs to access two columns and do more complicated processing so we expect it to be less impacted by the change of data type.
Before we get to results I think it is worth drawing attention to the raw performance we’re getting. I did these tests on DigitalOcean Droplet with just six virtual CPU cores, yet still I see numbers like these:
|
1 2 3 4 5 6 7 |
SELECT sum(nq_UInt32) FROM test ┌─sum(nq_UInt32) ──┐ │ 386638984 │ └──────────────────┘ 1 rows in set. Elapsed: 0.205 sec. Processed 386.48 million rows, 1.55 GB (1.88 billion rows/s., 7.52 GB/s.) |
Processing more than 300M rows/sec per core and more than 1GB/sec per core is very cool!
Results between different compression levels show similar differences between column types, so let’s focus on those with the least compression:
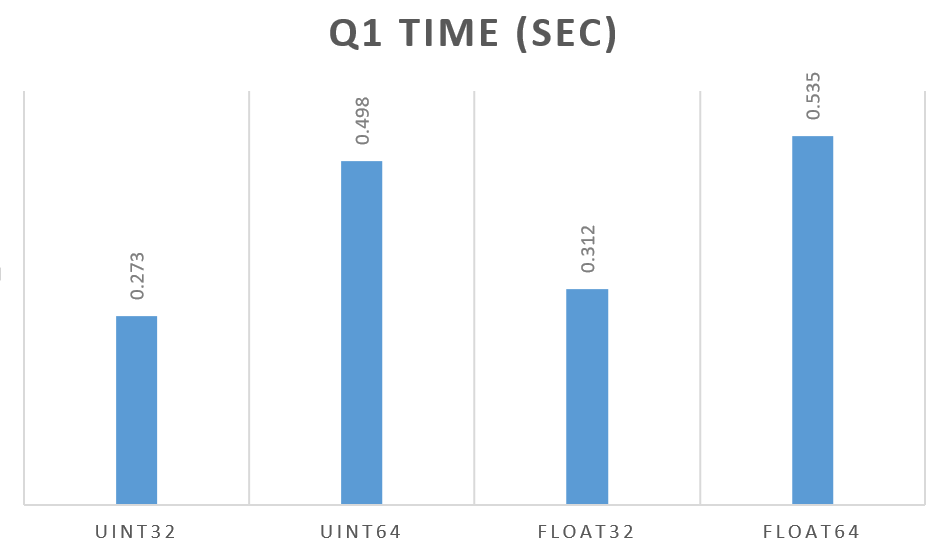
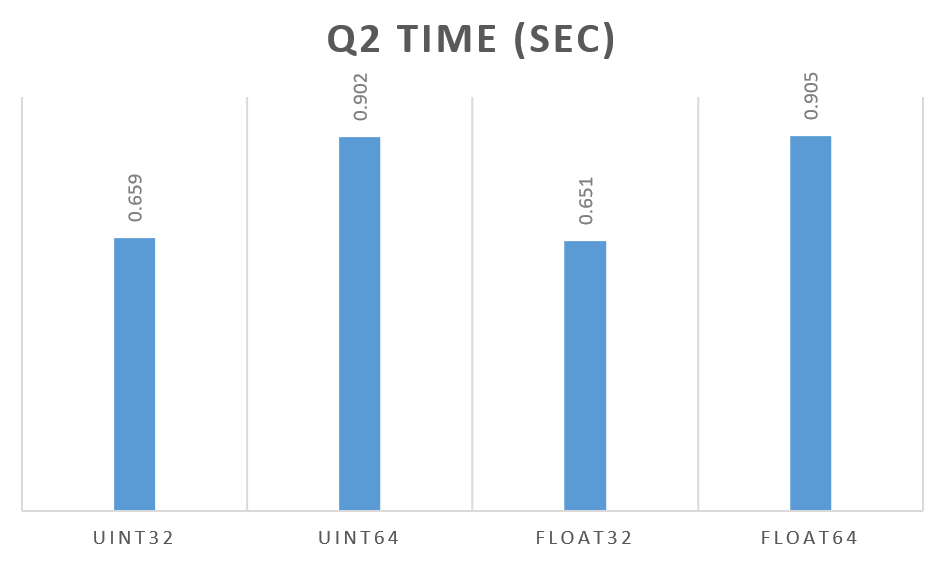
As you can see, the width of the data type (32 bit vs 64 bit) matters a lot more than the type (float vs integer). In some cases float may even perform faster than integer. This was the most unexpected result for me.
Another metric ClickHouse reports is the processing speed in GB/sec. We see a different picture here:
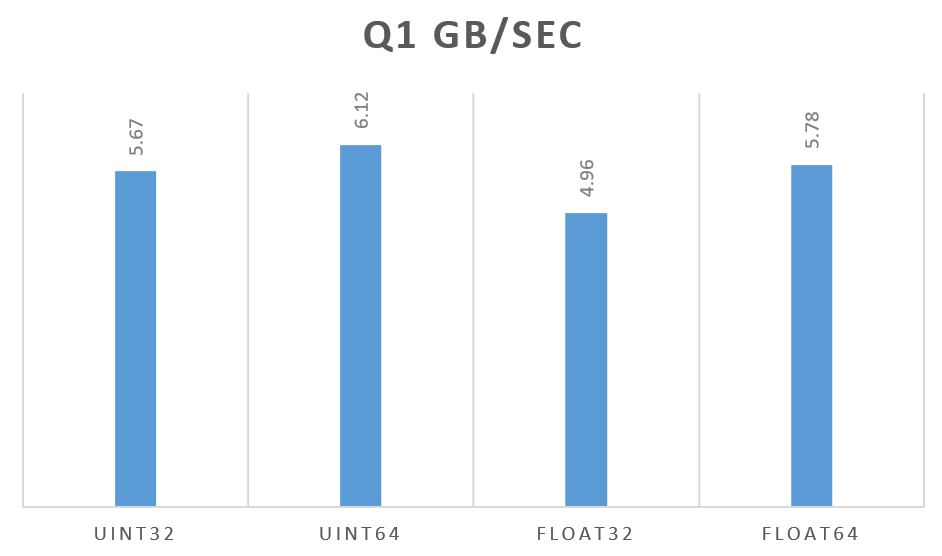
64 bit data types have a higher processing speed than their 32 bit counter parts, but queries run slower as there is more raw data to process.
Let’s now take a closer look at compression. For this test we use default LZ4 compression. ClickHouse has powerful support for Per Column Compression Codecs but testing them is outside of scope for this post.
So let’s look at size on disk for UInt32 Column:
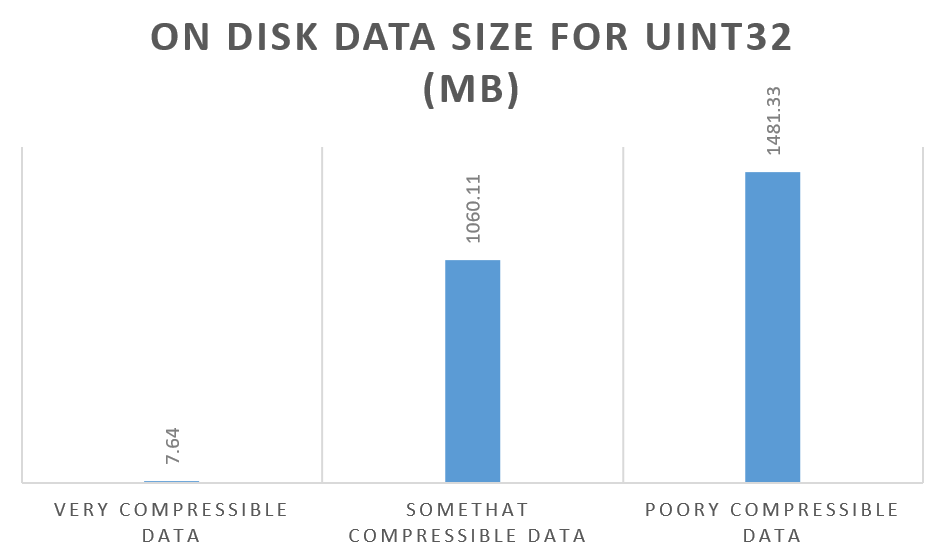
What you can see from these results is that when data is very compressible ClickHouse can compress it to almost nothing. The compression ratio for our very compressible data set is about 200x (or 99.5% size reduction if you prefer this metric).
Somewhat compressible data compression rate is 1.4x. That’s not bad but considering we are only storing 1-1000 range in this column – which requires 10 bits out of 32 – I would hope for better compression. I guess LZ4 is not compressing such data very well.
Now let’s look at compression for a 64 bit integer column:
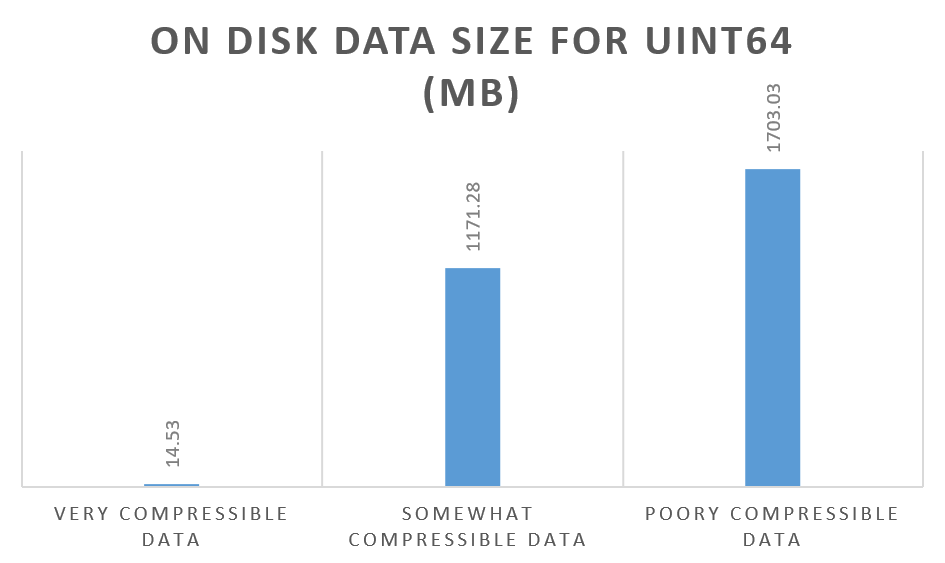
We can see that while the size almost doubled for very compressible data, increases for our somewhat compressible data and poorly compressible data are not that large. Somewhat compressible data now compresses 2.5x.
Now let’s take a look at Performance depending on data compressibility:
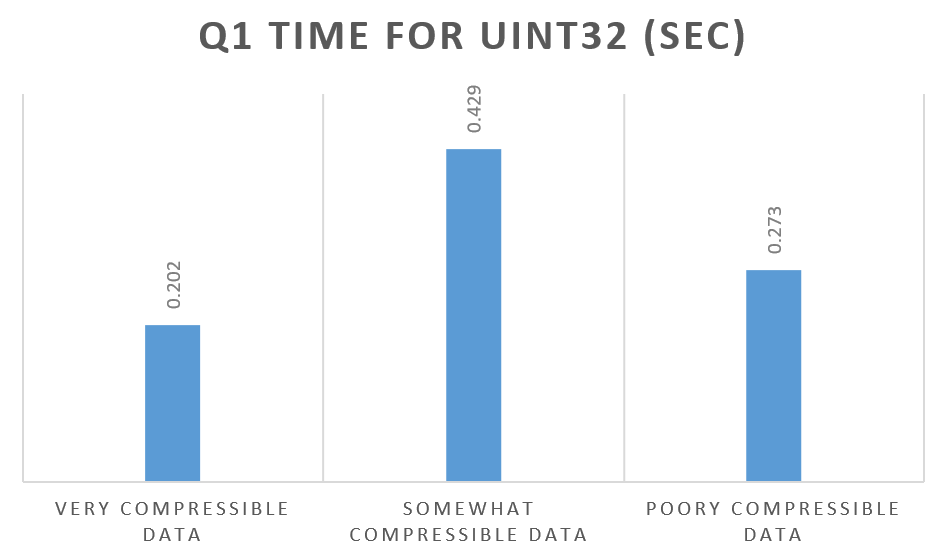
Poorly compressible data which takes a larger space on disk is processed faster than somewhat compressible data? This did not make sense. I repeated the run a few times to make sure that the results were correct. When I looked at the compression ratio, though, it suddenly made sense to me.
Poorly compressible data for the UInt32 data type was not compressible by LZ4 so it seems the original data was stored, significantly speeding up “decompression” process. With somewhat compressible data, compression worked and so real decompression needed to take place too. This makes things slower.
This is why we can only observe these results with UInt32 and Float32 data types. UInt64 and Float64 show the more expected results:
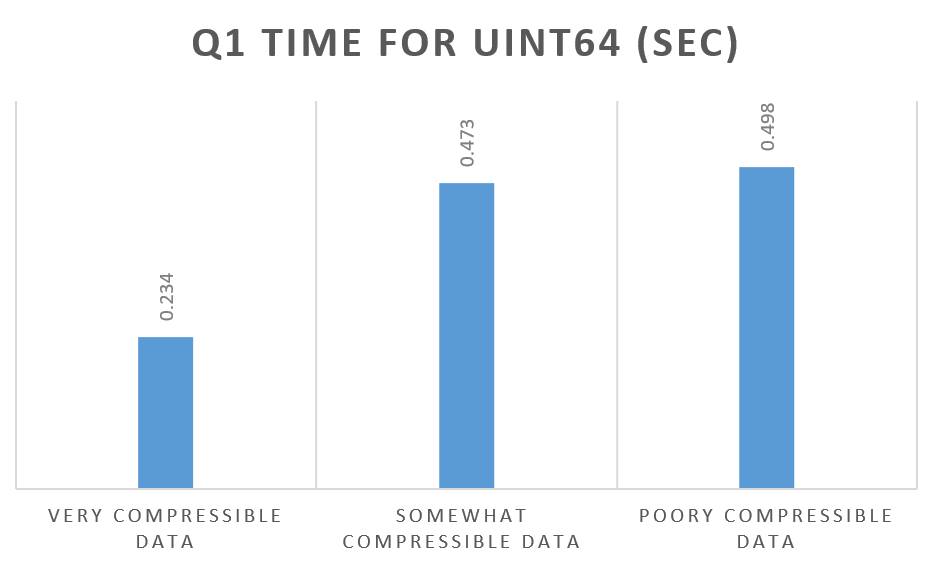
Here are my conclusions:





> Poorly compressible data for the UInt32 data type was not compressible by LZ4 so it seems the original data was stored, significantly speeding up “decompression” process.
Shouldn’t this be the case for UInt64 as well? The how come Q1 for UInt64 don’t exhibit the same “poorly compressible data faster than somewhat compressible data” we see for UInt32?
Hi Andy,
With UINT64 we have other story. As value range is only 1.000.000 we will have only 3 bytes needed to represent it and 5 leading bytes are zeroes, which gives a lot of room for compression even for relatively simple algorithm as LZ4
There is a new feature — codecs CODEC(Delta(1), ZSTD))
create table codec_test(t UInt64, a Int32) engine = MergeTree() order by (t);
insert into codec_test select number, number/10000 from numbers(10000000);
insert into codec_test select number, number/10000+1 from numbers(10000000);
select sleep(1);
optimize table codec_test final;
select data_compressed_bytes from system.columns where table = ‘codec_test’ and name = ‘a’;
┌─data_compressed_bytes─┐
│ 375722 │
└───────────────────────┘
create table codec_test1(t UInt64, a Int32 CODEC(Delta(1), ZSTD)) engine = MergeTree() order by (t);
insert into codec_test1 select number, number/10000 from numbers(10000000);
insert into codec_test1 select number, number/10000+1 from numbers(10000000);
select sleep(1);
optimize table codec_test1 final;
select data_compressed_bytes from system.columns where table = ‘codec_test1’ and name = ‘a’;
┌─data_compressed_bytes─┐
│ 98989 │
└───────────────────────┘