
Linux kernel provides a wide range of configuration options that can affect performance. It’s all about getting the right configuration for your application and workload. Just like any other database, PostgreSQL relies on the Linux kernel to be optimally configured. Poorly configured parameters can result in poor performance. Therefore, it is important that you benchmark database performance after each tuning session to avoid performance degradation. In one of my previous posts, Tune Linux Kernel Parameters For PostgreSQL Optimization, I described some of the most useful Linux kernel parameters and how those may help you improve database performance. Now I am going to share my benchmark results with you after configuring Linux Huge Page with different PostgreSQL workload. I have performed a comprehensive set of benchmarks for many different PostgreSQL load sizes and different number concurrent clients.
I have used default kernel settings without any optimization/tuning except for disabling Transparent HugePages. Transparent HugePages are by default enabled, and allocate a page size that may not be recommended for database usage. For databases generally, fixed sized HugePages are needed, which Transparent HugePages do not provide. Hence, disabling this feature and defaulting to classic HugePages is always recommended.
I have used consistent PostgreSQL settings for all the benchmarks in order to record different PostgreSQL workloads with different settings of Linux HugePages. Here is the PostgreSQL setting used for all benchmarks:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
shared_buffers = '64GB' work_mem = '1GB' random_page_cost = '1' maintenance_work_mem = '2GB' synchronous_commit = 'on' seq_page_cost = '1' max_wal_size = '100GB' checkpoint_timeout = '10min' synchronous_commit = 'on' checkpoint_completion_target = '0.9' autovacuum_vacuum_scale_factor = '0.4' effective_cache_size = '200GB' min_wal_size = '1GB' wal_compression = 'ON' |
In the benchmark, the benchmark scheme plays an important role. All the benchmarks are run three times with thirty minutes duration for each run. I took the median value from these three benchmarks. The benchmarks were carried out using the PostgreSQL benchmarking tool pgbench. pgbench works on scale factor, with one scale factor being approximately 16MB of workload.
Linux, by default, uses 4K memory pages along with HugePages. BSD has Super Pages, whereas Windows has Large Pages. PostgreSQL has support for HugePages (Linux) only. In cases where there is a high memory usage, smaller page sizes decrease performance. By setting up HugePages, you increase the dedicated memory for the application and therefore reduce the operational overhead that is incurred during allocation/swapping; i.e. you gain performance by using HugePages.
Here is the Hugepage setting when using Hugepage size of 1GB. You can always get this information from /proc.
|
1 2 3 4 5 6 7 |
AnonHugePages: 0 kB ShmemHugePages: 0 kB HugePages_Total: 100 HugePages_Free: 97 HugePages_Rsvd: 63 HugePages_Surp: 0 Hugepagesize: 1048576 kB |
For more detail about HugePages please read my previous blog post.
Generally, HugePages comes in sizes 2MB and 1GB, so it makes sense to use 1GB size instead of the much smaller 2MB size.
https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/6/html/performance_tuning_guide/s-memory-transhuge
https://kerneltalks.com/services/what-is-huge-pages-in-linux/
This benchmark shows the overall impact of different sizes of HugePages. The first set of benchmarks was created with the default Linux 4K page size without enabling HugePages. Note that Transparent Hugepages were also disabled, and remained disabled throughout these benchmarks.
Then the second set of benchmarks was performed with 2MB HugePages. Finally, the third set of benchmarks is performed with HugePages set to 1GB in size.
All these benchmarks were executed with PostgreSQL version 11. The sets include a combination of different database sizes and clients. The graph below shows comparative performance results for these benchmarks with TPS (transactions per seconds) on the y-axis, and database size and the number of clients per database size on the x-axis.
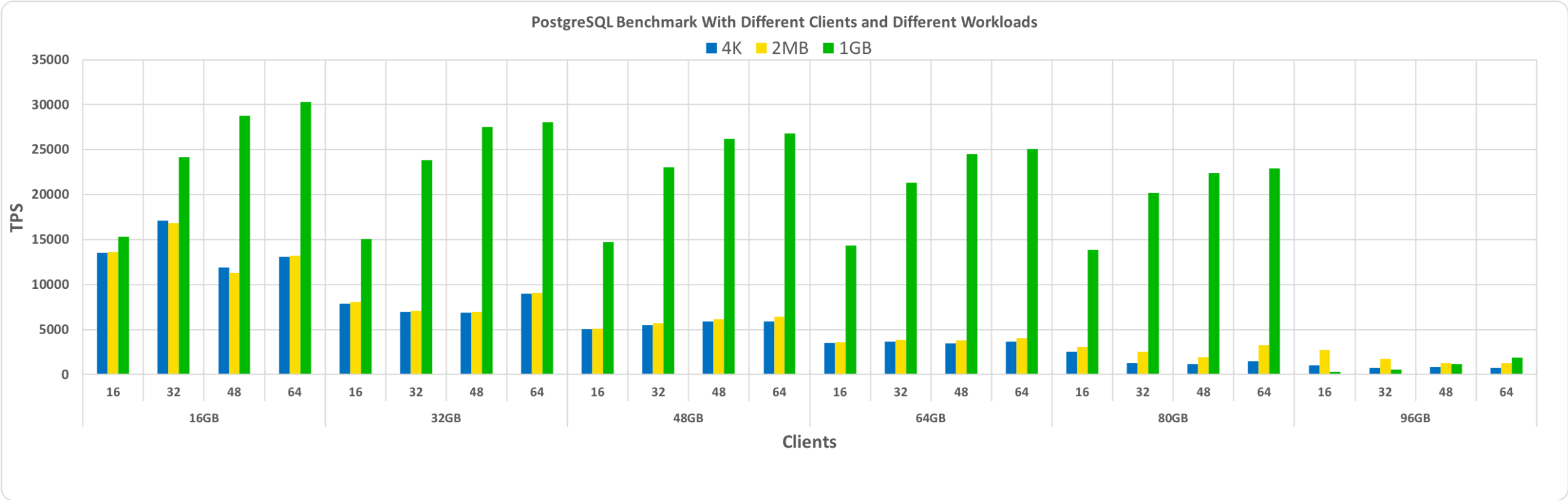
Clearly, from the graph above, you can see that the performance gain with HugePages increases as the number of clients and the database size increases, as long as the size remains within the pre-allocated shared buffer.
This benchmark shows TPS versus clients. In this case, the database size is set to 48GB. On the y-axis, we have TPS and on the x-axis, we have the number of connected clients. The database size is small enough to fit in the shared buffer, which is set to 64GB.
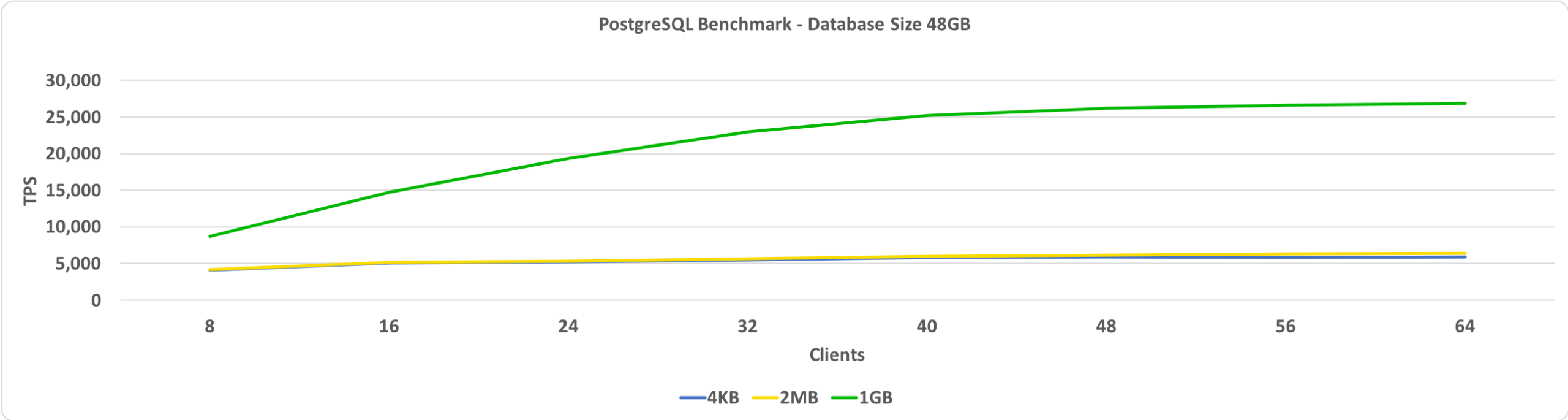
With HugePages set to 1GB, the higher the number of clients, the higher the comparative performance gain.
The next graph is the same as the one above except for a database size of 96GB. This exceeds the shared buffer size, which is set to 64GB.
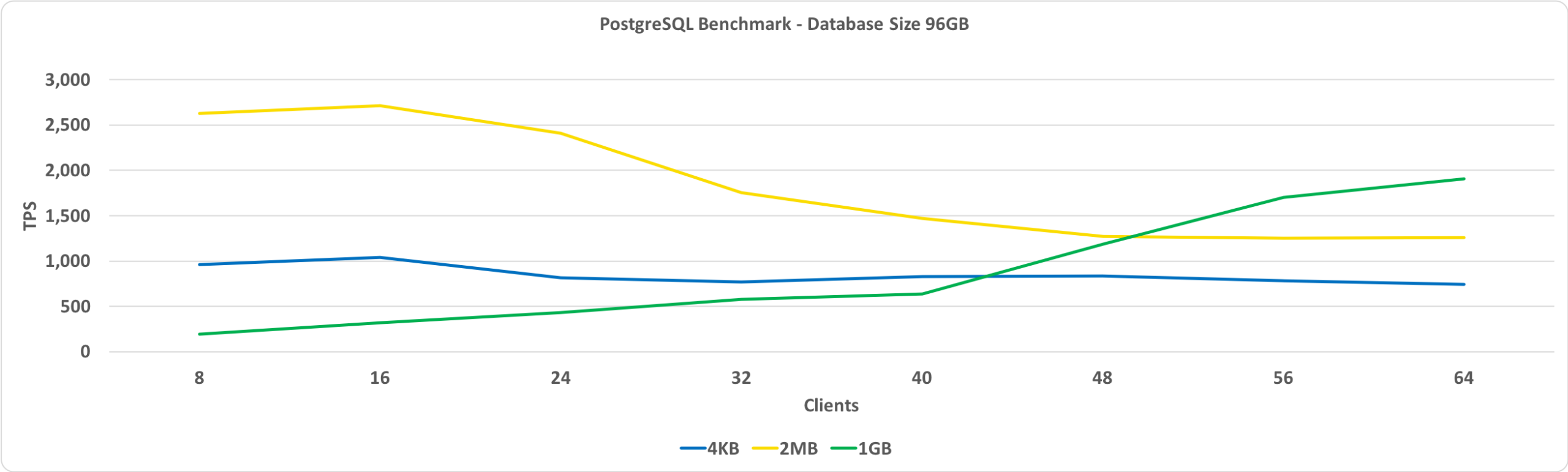
The key observation here is that the performance with 1GB HugePages improves as the number of clients increases and it eventually gives better performance than 2MB HugePages or the standard 4KB page size.
This benchmark shows the TPS versus database size. In this case, the number of connected clients it set to 32. On the y-axis, we have TPS and on the x-axis, we have database sizes.
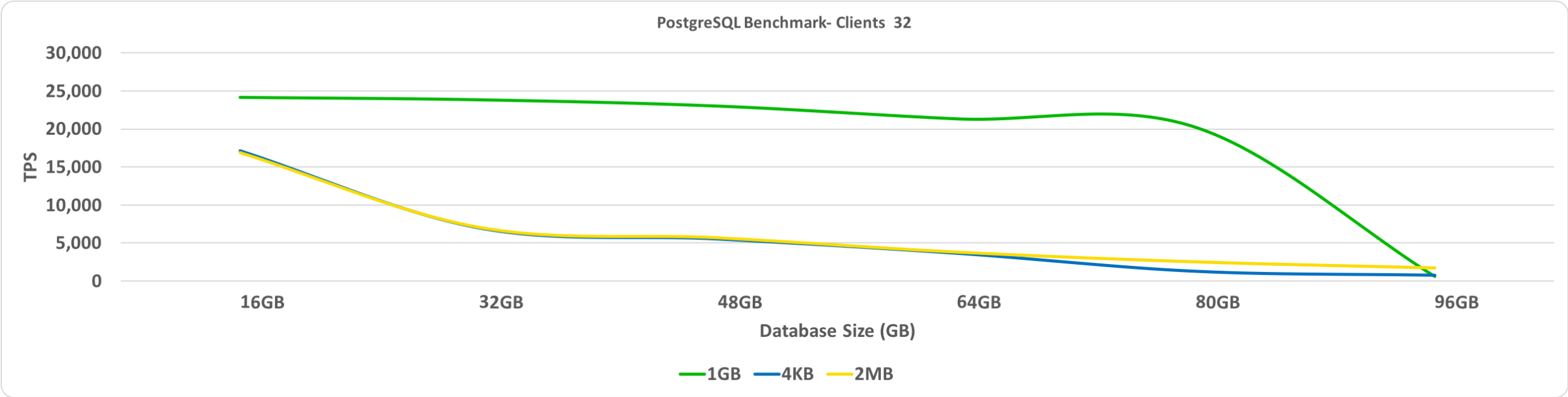
As expected, when the database spills over the pre-allocated HugePages, the performance degrades significantly.
One of my key recommendations is that we must keep Transparent HugePages off. You will see the biggest performance gains when the database fits into the shared buffer with HugePages enabled. Deciding on the size of huge page to use requires a bit of trial and error, but this can potentially lead to a significant TPS gain where the database size is large but remains small enough to fit in the shared buffer.





How to reproduce these testcases? Pgbench params etc.
PS: autovacuum_vacuum_scale_factor = ‘0.4’ is not suitable for heavy OLTP load.
‘+1 for pgbench params.
Along with this could you share for each test especially for cases under transition from 80GB to 96GB of db size:
– DB buffer hits and misses (differential value of
blks_hitandblks_readcolumns frompg_stat_database)– differential OS statistics from
pg_stat_kcache(https://github.com/powa-team/pg_stat_kcache)– TLB statistics from
perf stat.Yes, I am doing the benchmark with all the statistics, I will share the results with all statistics in my next blog.
Hi,
A lot of interesting results here…
1) PgBench access distribution is very interesting. With database size growing by 20% from 80G to 96G we see performance drop of Several times which is very counter-intuitive
2) There is no difference between 2MB and 4K but huge difference between 1G and 2M even though I would expect at least some TLB miss reduction in the first transitioning. I would understand it in case transparent huge pages are Enabled… but not disabled
3) For 96GB why would throughput grow with number of clients for 1G but fall for 2M and 4KB.
Thank you for putting this together. Since you’e using a NUMA system it may be interesting to see how the memory is allocated among nodes. Given AMD Zen and Intel considering MCP for server chips this area of optimization is becoming increasingly important.
Yeah. Benchmarks with NUMA it is all another story. I would imagine this would be interesting case of single instance vs multiple instances. In theory if you’re using Sharding anyway (Citus or something else) having multiple PostgreSQL instances where each is locked to the given chip both in CPU cores and memory allocation can perform faster… but how much faster
Thanks for putting this together. I would assume that performance gains here depend on the churn in the buffer pool. If there isn’t locality of reference in the workload I think large pages will do much worse than 4k since more data has to be moved in and out of the buffer.
Hi,
The database page size, which is also logical page size used for cache and the physical memory page size should not be related. Nothing prevents you from allocating using 1G pages and when doing 8K IO sizes into the allocated area
You have shared such an amazing guide. I’m a big fan of using unique and popular typography fonts on my site. I have designed many popular mockups by using great fonts. Your sharing is really appreciated.
Thanks for the wonderful information and i learn so much from your post. i am student of MCS and now i am learning the HTML. All Linux SQL i have noted my note book.
Thanks for the information….