
In the previous blog posts in this series, we’ve covered some of the essential aspects of an Enterprise-grade solution: security, high availability, and backups. Another important aspect is the scalability of the solution: as our application grows how do we accommodate an increase in traffic while maintaining the quality of the service (response time)? The answer to this question depends on the nature of the workload at play but it is often shaped around:
(a) improving its efficiency and
(b) increasing the resources available.
When it comes to improving the efficiency of a database workload, one of the first places we start looking at is the list of slow queries; if the most popular ones can be optimized to run faster then we can easily gain some overall performance back. Arguably, we may look next at the number and frequency of client connections: is the workload composed of a high number of very frequent but short-lived connections? Or are clients connections of a more moderate number, and tend to stick around for longer?
If we consider the first scenario further–a high number of short-lived connections–and that each connection spawns a new OS process, the server may hit a practical limit as to the number of transactions—or connections—it can manage per second, considering the hardware available and the workload being processed. Remember that PostgreSQL is process-based, as opposed to thread-based, which is itself an expensive operation in terms of resources, both CPU and memory.
A possible remedy for this would be the use of a connection pooler, acting as a mediator between the application and the database. The connection pooler keeps a number of connections permanently opened with the database and receives and manages all incoming requests from clients itself, allowing them to temporarily use one of the connections it already has established with PostgreSQL. This removes the burden of creating a new process each time a client establishes a connection with PostgreSQL and allows it to employ the resources that it would otherwise use for this into serving more requests (or completing them faster).
A general rule of thumb that we often hear is that you may need a connection pooler once you reach around 350 concurrent connections. However, the actual threshold is highly dependent on your database traffic and server configuration: as we find out recently, you may need one much sooner.
You may implement connection pooling using your native application connection pooler (if there is one available) or through an external connection pooler such as PgBouncer and pgPool-II. For the solution we have built, which we demonstrate in our webinar of October 10, we have used PgBouncer as our connection pooler.
PgBouncer is a lightweight (thread-based) connection pooler that has been widely used in PostgreSQL based environments. It “understands” the PostgreSQL connection protocol and has been a stable project for over a decade.
PgBouncer allows you to configure the pool of connections to operate in three distinct modes: session, statement, and transaction. Unless you have a good reason to reserve a connection in the pool to a single user for the duration of its session or are operating with single-statements exclusively, transaction mode is the one you should investigate.
A feature that is central to our enterprise-grade solution is that you can add multiple connection strings using unique alias names (referred to as database names). This allows greater flexibility when mediating connections with multiple database servers. We can then have an alias named “master_db” that will route connections to a master/primary server and another alias named “slave_db” that will route connections to a slave/standby server.
Once efficiency is taken care of, we can then start working on increasing the resources, or computing power, available to process database requests. Scaling vertically means, in short, upgrading the server: more and faster cores, memory, storage. It’s a simple approach, but one that reaches a practical limitation rather quickly. It is not in line with other requirements of an enterprise-grade solution, such as high availability. The alternative is scaling horizontally. As briefly introduced above, a common way for implementing horizontal scalability is to redirect reads to standby servers (replicas) with the help of a proxy, which can also act as a load balancer, such as HAProxy. We’ll be discussing these ideas further here, and showcase their integration in our webinar.
HAProxy is a popular open source TCP/HTTP load balancer that can distribute the workload across multiple servers. It can be leveraged in a PostgreSQL replication cluster that has been built using streaming replication. When you build replication using streaming replication method standby replicas are open for reads. With the help of HAProxy you can efficiently utilize the computing power of all database servers, distributing read requests among the available replicas using algorithms such as Least Connection and Round Robin.
The following diagram represents a simplified part of the architecture that composes the enterprise-grade solution we’ve designed, where we employ PgBouncer and HAProxy to scale our PostgreSQL cluster:
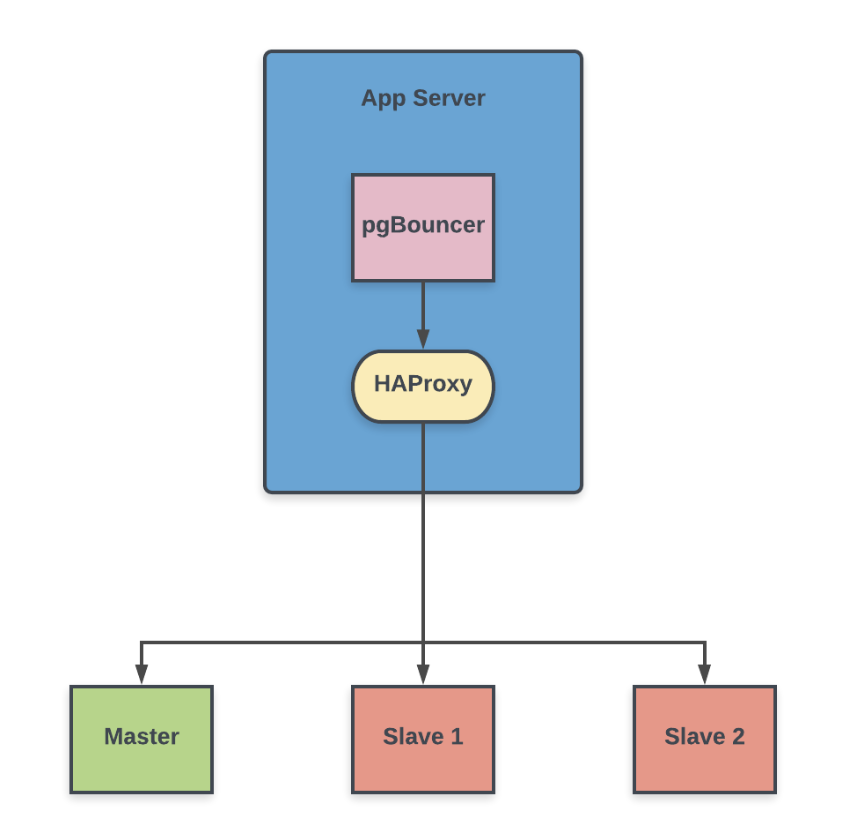
Our PgBouncer contains two database (alias) names, one for redirecting writes to the master and another for balancing reads across standby replicas, as discussed above. Here is how the database section looks in the pgbouncer.ini, PgBouncer’s main configuration file:
|
1 2 3 |
[databases] master = host=haproxy port=5002 dbname=postgres slave = host=haproxy port=5003 dbname=postgres |
Notice that both database entries redirect their connections to the HAProxy server, but each to a different port. The HAProxy, in turn, is configured to route the connections in functions of the incoming port they reach. Considering the above pgBouncer config file as a reference, writes (master connections) are redirected to port 5002 and reads (slave connections) to port 5003. Here is how the HAProxy config file looks:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# Connections to port 5002 listen Master bind *:5002 option tcp-check tcp-check send GET / HTTP/1.0rn tcp-check send HOSTrn tcp-check send rn tcp-check expect string "role": "master" default-server inter 3s fall 3 rise 2 on-marked-down shutdown-sessions server pg0 pg0:5432 maxconn 100 check port 8008 server pg1 pg1:5432 maxconn 100 check port 8008 server pg2 pg2:5432 maxconn 100 check port 8008 # Connections to port 5003 listen Slaves bind *:5003 option tcp-check tcp-check send GET / HTTP/1.0rn tcp-check send HOSTrn tcp-check send rn tcp-check expect string "role": "replica" default-server inter 3s fall 3 rise 2 on-marked-down shutdown-sessions server pg0 pg0:5432 maxconn 100 check port 8008 server pg1 pg1:5432 maxconn 100 check port 8008 server pg2 pg2:5432 maxconn 100 check port 8008 |
As seen above:
In a previous post, we discussed using Patroni in our high availability setup. HAProxy relies on Patroni to determine the role of the PostgreSQL server. Patroni is being used here for cluster management and automatic failover. By using Patroni’s REST API (on port 8008 in this scenario) we can obtain the role of a given PostgreSQL server. The example below shows this in practice, the IP addresses denoting the PostgreSQL servers in this setup:
|
1 2 3 4 5 6 |
$ curl -s 'http://192.168.50.10:8008' | python -c "import sys, json; print json.load(sys.stdin)['role']" replica $ curl -s 'http://192.168.50.20:8008' | python -c "import sys, json; print json.load(sys.stdin)['role']" master $ curl -s 'http://192.168.50.30:8008' | python -c "import sys, json; print json.load(sys.stdin)['role']" replica |
HAProxy can thus rely on Patroni’s REST API to redirect connections from the master alias in PgBouncer to a server with role master. Similarly, HAProxy uses server role information to redirect connections from a slave alias to one of the servers with role replica, using the appropriate load balancer algorithm.
This way, we ensure that the application uses the advantage of a connection pooler to leverage connections to the database, and also of the load balancer which distributes the read load to multiple database servers as configured.
There are many other open source connection poolers and load balancers available to build a similar setup. You can choose the one that best suits your environment—just make sure to test your custom solution appropriately before bringing it to production.





> tcp-check expect string “role”: “master”
This is considered to be a bad practice, you shouldn’t do that!
In some situations it might happen that role is master (because postgres is not running in recovery), but the leader key is owned by some other node.
Patroni provides a few REST API endpoints for master-replica health checks, which will return http status codes 200 or 503. Haproxy must rely only on http status codes.
“/master” — will return http status code 200 only if the node is holding the leader key in DCS. In all other cases it will return 503.
“/replica” — will return code 200 if node is running as replica and it is allows load balancing (noloadbalance tags is not set)
Besides that it is better to use OPTIONS request method instead of GET:
option httpchk OPTIONS /master
http-check expect status 200
In order to automate everything, one can use confd (https://github.com/kelseyhightower/confd), and Patroni provides you an example of haproxy template: https://github.com/zalando/patroni/blob/master/extras/confd/templates/haproxy.tmpl#L19-L32
Confd will take care about generating the new haproxy config and reloading/restarting haproxy if the list of Patroni nodes registered in DCS is changing.
Thank you very much for this detailed expert comment. We hope all our readers will benefit from this information.
The HAProxy configuration template which uses http-check rather than tcp-check is much better and simpler.
confd can can make the configuration much more dynamic also.
Hi Alexander,
Correct, this method is simpler too. Both the methods get the information from Patroni and should give same information. Do you see a situation where the leader key is with another node than the actual master ?
Why would you put HAProxy behind PgBouncer? The point of PgBouncer is to maintain a pool of PG connections that can be reused. Now that you put HAProxy in there, PgBouncer can’t even connect directly with Postgresql. What’s the point?
Thank You for reading through the blog. pgBouncer still maintains persistent connections and behave no different. Many applications with native connection poolers use HA Proxy similar way. Using pgBouncer before HAProxy still does the job of a connection pooler as it does when it directly connects to DB
Nice post. However I still don’t understand how pgbouncer will redirect write queries to the master and read-only to the slaves.
It won’t. The article is written in a way that makes you think it would, i.e. an SQL statement hits pgbouncer, pgbouncer recognizes that it is either a read or write and basing on that directs the statement to either “master” or “slave” databases configured in [databases] section, but pgbouncer does not have such functionality AFAIK.
Application need to have clear understanding of its own requirement. whether it needs a Primary connection or any standby connection is sufficient. This is similar to Oracle’s role-based service. A primary connection always it is available in HAProxy’s Port 5002 and Standby connection (Read-only) will be available on HAProxy’s port 5003 which will remain unaffected by database switchovers/failovers. So the explicit connection routing happens at HAProxy layer.
PGbouncer just adds a connection pooling on the top of it.
What if the pgbouncer get’s crashed ?!
Such Crashes can happen to any services inside the Application. Not just pgBouncer, be it HAProxy or some other service being used by App may fail. This is why we need to have Application level failover as well. You will usually see Active and Passive App servers in neat setups and Apps that are scaled enough to handle failover in case any of the behaviour changes.
Who distinguishes the Query thus for read and that for write?
Connection routing is preferred rather than individual statement routing. Application module decides whether it really need a primary connection (read-write) or any hot standby connection (read-only) is sufficient. For example, reporting modules with complex queries can request for read-only connection and proxy can route that connection to any of the hot standby.
Hi,
thanks for article,
i may be wrong, but for me it seems that there is no possibility to utilize MASTER node for SELECTS in case app choose role (connection string) with slave alias.
Ideally master node should receive ANY TYPE of query and stand by nodes just SELECTS.
But in case i have 2 nodes cluster then such solution won’t load balance anything because:
if i choose alias MASTER i will be redirected to MASTER node only
if i choose alias SLAVE i will be redirected to single STANDBY node only
but cluster of 2 nodes is able theoretically handle SELECTS from both nodes
can you comment ? or i misundesrtood something ?
pgpool2 can do statement routing.
Blindly redirecting all SELECTs to standby may not be a good idea. we may have SELECTs which is part of transactions and different isolation level requirements relative to other concurrent transactions. I would prefer SELECTs from specific modules like Reporting to be redirected to standby.
thanks for quick answer i see you point regarding reporting service.
if anyone would be interested how to have behavior as i described:
while browsing some articles i found one article which shows how to routing as i described using HAProxy: https://severalnines.com/database-blog/postgresql-load-balancing-using-haproxy-keepalived (section “HAProxy Configuration”)
health check for slave alias uses regex so any node (master or standby) status is ok this way selects would be redirected to all 3 nodes.