
![]() High availability (HA) and database replication is a major topic of discussion for database technologists. There are a number of informed choices to be made to optimize PostgreSQL replication so that you achieve HA. In this post we introduce an overview of the topic, and cover some options available to achieve high availability in PostgreSQL. We’ll then focus in on just one way to implement HA for postgres, using Patroni.
High availability (HA) and database replication is a major topic of discussion for database technologists. There are a number of informed choices to be made to optimize PostgreSQL replication so that you achieve HA. In this post we introduce an overview of the topic, and cover some options available to achieve high availability in PostgreSQL. We’ll then focus in on just one way to implement HA for postgres, using Patroni.
In our previous blog posts, we have discussed the features available to build a secured PostgreSQL environment and the tools available to help you set up a reliable backup strategy. The series of articles is designed to provide a flavor of how you might go about building an enterprise-grade PostgreSQL environment using open source tools. If you’d like to see this implemented, then please do check our our webinar presentation of October 10 – we think you might find it both useful and intriguing!
The first step towards achieving high availability is making sure you don’t rely on a single database server: your data should be replicated to at least one standby replica/slave. Database replication can be done using the two options available with PostgreSQL community software:
When we setup streaming replication, a standby replica connects to the master (primary) and streams WAL records from it. Streaming replication is considered to be one of the safest and fastest methods for replication in PostgreSQL. A standby server becomes an exact replica of the primary with potentially minimal lag between primary and standby even on very busy transactional servers. PostgreSQL allows you to build synchronous and asynchronous replication while in streaming replication. Synchronous replication ensures that a client is given a success message only when the change is not only committed to the master but also successfully replicated on the standby server as well. As standby servers can accept read requests from clients, we can make more efficient use of our PostgreSQL setup by sparing the master from serving read requests and redirecting these to the replicas instead. You can read more about Streaming Replication in this blog post.
Logical replication in PostgreSQL allows users to perform a selective replication of a subset of the tables found in the master. While streaming replication is implemented in PostgreSQL at block level—where every database in the master gets replicated to the replica, which remains read-only—logical replication suits such unique scenarios where you need to perform replication of a selection of tables in a database and (optionally) allow direct writes to your slave. A slave configured with logical replication can also be configured to replicate from multiple masters. One situation where this is helpful is when you need to replicate data from several PostgreSQL databases to a single PostgreSQL server for reporting and data warehousing tasks.
While it’s technically possible to employ standby servers configured with logical replication in an HA environment, this doesn’t fare well as a best practice. For such usage, a standby server should be able to take the place of another server “transparently” – the more they resemble the master the better. Logical replication opens the door for different data to be replicated to different servers, and this may break things
Here is a list of built-in features available in PostgreSQL that are designed to help achieve high availability:
There are many more open source solutions that can help us achieve high availability with PostgreSQL, especially during critical moments, when a master (primary server) becomes unavailable. The following is a list of a few such open source solutions built for PostgreSQL:
However, the HA solutions available for PostgreSQL are not just limited to the list above. We would be interested to hear what you have implemented as an HA solution in the comments section below.
In our upcoming webinar we are going to show you a PostgreSQL replication cluster built using Patroni and how it provides a seamless failover that is transparent to the application.
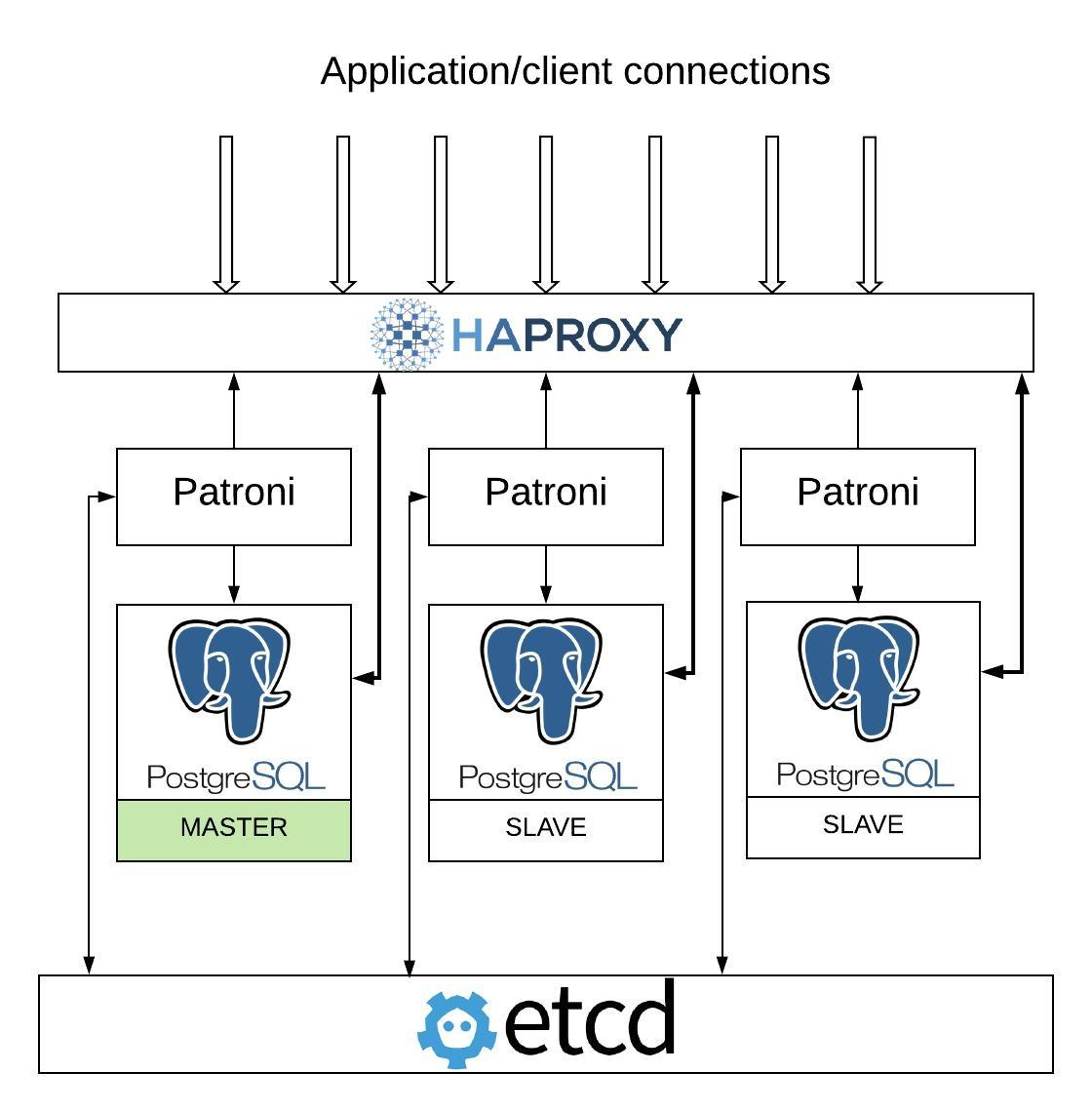
Patroni is a PostgreSQL cluster management template/framework which stores and talks to a distributed consensus key-value store and decides on the state of the cluster. It started as a fork of Governor project. A Patroni PostgreSQL cluster is composed of many individual PostgreSQL instances running on bare metal, containers or virtual machines. In our setup we’ve used etcd for consensus management, which handles leader elections and decides the leader among a cluster of servers that are partitioned by network. This distributed consensus management can also be achieved by using other technologies, such as ZooKeeper and Consul. In the event of a failover, Patroni promotes the slave that has been assigned as a leader by etcd-like consensus key-value stores. Note that when we setup asynchronous replication, you have an option to specify maximum_lag_on_failover to restrict it from promoting a slave that is lagging by more than this value.
Here’s an architecture diagram of Patroni :
You are sure to enjoy our webinar of October 10, where we demonstrate live how to build an enterprise-grade PostgreSQL environment with open source tools. If you make it to the live presentation, you will also have the chance to ask questions of the team.
In the next blog post of this series we’ll be covering the scalability of our solution and how to accommodate an increase in traffic while maintaining the quality of the service. We’re moving ever closer to an enterprise-grade environment with open source tools!




