
As PostgreSQL based applications scale, the need to implement connection pooling can become apparent sooner than you might expect. Since PostgreSQL to date has no built-in connection pool handler, in this post I’ll explore some of the options for implementing it and take a look at some of the implications for application performance.
PostgreSQL implements connection handling by “forking” it’s main OS process into a child process for each new connection. An interesting practical consequence of this is that we get a full view of resource utilization per connection in PostgreSQL at the OS level (the output below is from top):
|
1 2 3 4 5 |
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 24379 postgres 20 0 346m 148m 122m R 61.7 7.4 0:46.36 postgres: sysbench sysbench ::1(40120) 24381 postgres 20 0 346m 143m 119m R 62.7 7.1 0:46.14 postgres: sysbench sysbench ::1(40124) 24380 postgres 20 0 338m 137m 121m R 57.7 6.8 0:46.04 postgres: sysbench sysbench ::1(40122) 24382 postgres 20 0 338m 129m 115m R 57.4 6.5 0:46.09 postgres: sysbench sysbench ::1(40126) |
This extra visualization comes at some additional cost though: it is more expensive—in terms of time and memory mostly—to fork an OS process than it would be, for example, to spawn a new thread for an existing process. This might be irrelevant if the rate at which connections are opened and closed is low but becomes increasingly important to consider over time as this reality changes. That is possibly one of the reasons why the need for a connection pooling mechanism often manifests itself early in the scaling life of a PostgreSQL-based application.
When an application server sends a connection request to a PostgreSQL database it will be received by the Postmaster process. Postmaster, observing the limit set by max_connections, will then fork itself, creating a new backend process to handle this new connection. This backend process will live until the connection is closed by the client or terminated by PostgreSQL itself.
If the application was conceived with the database in mind it will make effective use of connections, reusing existing ones whenever possible while avoiding idle connections from laying around for too long. Unfortunately, that is not always the case. Plus there are legitimate situations where the application popularity/usage increases. These naturally increases the rate at which new connection requests are created. There is a practical limit for the number of connections a server can manage at a given time. Beyond these limits, we start seeing contention in different areas. This, in turn, affects the server’s capacity to process requests, which can lead to bigger problems.
Putting a cap on the number of connections that may exist at any given time helps somewhat. However, considering the time it takes to properly establish a new connection, if the rate at which new connection requests arrive continues to rise we may soon reach a scaling problem.
What if we could instead recycle existing connections to serve new client requests to gain on time (by avoiding the creation and remotion of yet another backend process each time), ultimately increasing transaction throughput, while also making better use of the resources available? The strategy that revolves around the use of a cache (or pool) of connections that are kept open on the database server and re-used by different client requests is known as connection pooling.
Given there is no built-in handler for PostgreSQL, there are typically two ways of implementing such a mechanism:
An application connection pooler might provide better integration with the application, for example, when it comes to the use of prepared statements and the re-utilization of the cached result set. However, sometimes they may fall short on understanding PostgreSQL protocol and this might result in things like failing to properly clear pre-cached memory. An external service, on the other hand, won’t provide such tight integration with a particular application but usually allows for greater customization and better maintenance of the pool. This often provides the ability to increase and decrease the number of connections it maintains cached dynamically and according to the demand observed, while also respecting pre-set threshold marks. Probably the most popular connection pooler used with PostgreSQL is PgBouncer.

In order to illustrate the impact a connection pooler might have on the performance of a PostgreSQL server, I took advantage of the recent tests we did with sysbench-tpcc on PostgreSQL and repeated them partially by making use of PgBouncer as a connection pooler.
When we first ran the tests our goal was to optimize PostgreSQL for sysbench-tpcc workload running with 56 concurrent clients (threads), with the server having the same amount of CPUs available. The goal this time was to vary the number of concurrent clients (56, 150, 300 and 600) to see how the server would cope with the scaling of connections.
Instead of running each round for 10 hours, however, I ran them for 30 minutes only. This might mask, or at least change, the effects of checkpointing and caching observed in our initial tests.
I compiled the latest version of PgBouncer (1.8.1) following the instruction on GitHub and installed it in our test box, alongside PostgreSQL.
PgBouncer can be configured with three different types of pooling:
I went with transaction pooling for my tests as the workload of sysbench-tpcc is composed of several short and single-statement transactions. Here’s the configuration file I used in full, which I named pgbouncer.ini:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
[databases] sbtest = host=127.0.0.1 port=5432 dbname=sbtest [pgbouncer] listen_port = 6543 listen_addr = 127.0.0.1 auth_type = md5 auth_file = users.txt logfile = pgbouncer.log pidfile = pgbouncer.pid admin_users = postgres pool_mode = transaction default_pool_size=56 max_client_conn=600 |
Apart from pool_mode, the other variables that matter the most are (definitions below came from PgBouncer’s manual page):
The users.txt file specified by auth_file contains only a single line with the user and password used to connect to PostgreSQL; more elaborate authentication methods are also supported.
I started PgBouncer as a daemon with the following command:
|
1 |
$ pgbouncer -d pgbouncer.ini |
Apart from running the benchmark for only 30 minutes and varying the number of concurrent threads each time, I employed the exact same options for sysbench-tpcc we used in our previous tests. The example below is from the first run with threads=56:
|
1 |
$ ./tpcc.lua --pgsql-user=postgres --pgsql-db=sbtest --time=1800 --threads=56 --report-interval=1 --tables=10 --scale=100 --use_fk=0 --trx_level=RC --pgsql-password=****** --db-driver=pgsql run > /var/lib/postgresql/Nando/56t.txt |
For the tests using the connection pooler I adapted the connection options so as to connect with PgBouncer instead of PostgreSQL directly. Note it remains a local connection:
|
1 |
./tpcc.lua --pgsql-user=postgres --pgsql-db=sbtest --time=1800 --threads=56 --report-interval=1 --tables=10 --scale=100 --use_fk=0 --trx_level=RC --pgsql-password=****** --pgsql-port=6543 --db-driver=pgsql run > /var/lib/postgresql/Nando/P056t.txt |
After each sysbench-tpcc execution I cleared the OS cache with the following command:
|
1 |
$ sudo sh -c 'echo 3 >/proc/sys/vm/drop_caches' |
It is not like this will have made much of a difference. As discussed in our previous post shared_buffers was set with 75% of RAM, enough to fit all of the “hot data” in memory.
Without further ado here are the results I obtained:
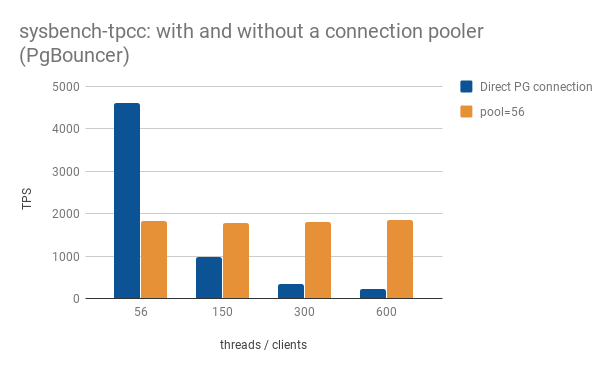
When running sysbench-tpcc with only 56 concurrent clients the use of direct connections to PostgreSQL provided a throughput (TPS stands for transactions per second) 2.5 times higher than that obtained when using PgBouncer. The use of a connection pooler, in this case, was extremely detrimental to performance. At such a small scale there were no gains obtained from a pool of connections, only overhead.
When running the benchmark with 150 concurrent clients, however, we start seeing the benefits of employing a connection pooler. In fact, such benefits most probably materialize much earlier. With hindsight going from 56 concurrent transactions to 150 was too big of an initial jump.
It was somewhat surprising to me to realize at first that such throughput could be sustained with PgBouncer even when doubling and then quadrupling the number of concurrent clients. What happens, in this case, is that instead of flooding PostgreSQL with that many requests at once, they all stop at PgBouncer’s door. PgBouncer only allows the next request to proceed to PostgreSQL once one of the connections in its pool is freed. Remember, I configured it in transaction pooling mode. The process is transparent to PostgreSQL. It has no idea how many requests are waiting at PgBouncer’s door to be processed (and thus it is spared the trouble and doesn’t freak out!). It’s effectively like outsourcing connection management, beyond the ones used by the pool itself, to a contractor. PgBouncer does this hard work so PostgreSQL doesn’t need to.
This strategy seems to work great for sysbench-tpcc. With other workloads, the balance point might lie elsewhere.
For the tests above I set default_pool_size on PgBouncer equal to the number of CPU cores available on this server (56). To explore the tuning of this parameter, I repeated these tests using bigger connection pools (150, 300, 600) as well as a smaller one (14). The following chart summarizes the results obtained:
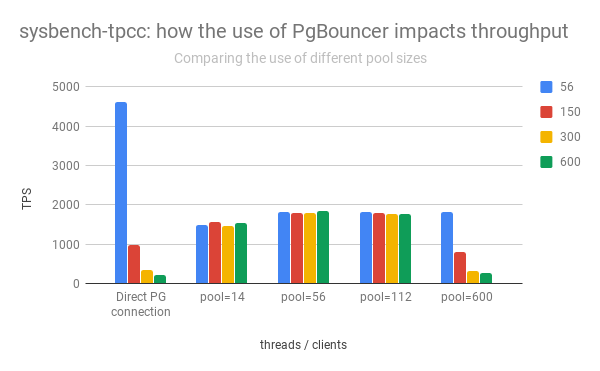
Using a much smaller connection pool (14), sized to ¼ of the number of available CPUs, still yielded a result almost as good. That says a lot about how much leveraging connection handling alone to PgBouncer already helps. Maybe some of PgBouncer’s “gatekeeper” qualities could be incorporated by PostgreSQL itself?
Doubling the number of connections in the pool didn’t make any practical difference. But as soon as we extrapolate that number to 600 (which is the number of maximum concurrent threads I’ve tested) throughput becomes comparable to when not using a connection pooler once the number of concurrent threads is greater than the number of available CPUs. That’s true even when running as many concurrent threads as there are connections available in the pool (600). There’s a practical limit to it, which clearly is on the PostgreSQL side. That’s expected, otherwise, the need for a connection pool wouldn’t be as important.
As a starting point, setting the connection pool size equal to the number of CPUs available in the server looks like a good idea. There may be a hard limit for the pool around 150 connections or so, after which further benefits aren’t realized. However, that’s only speculation. Further tests using both different hardware and workloads would be needed to investigate this properly.
Here’s the table that summarizes the results obtained, for a different view:
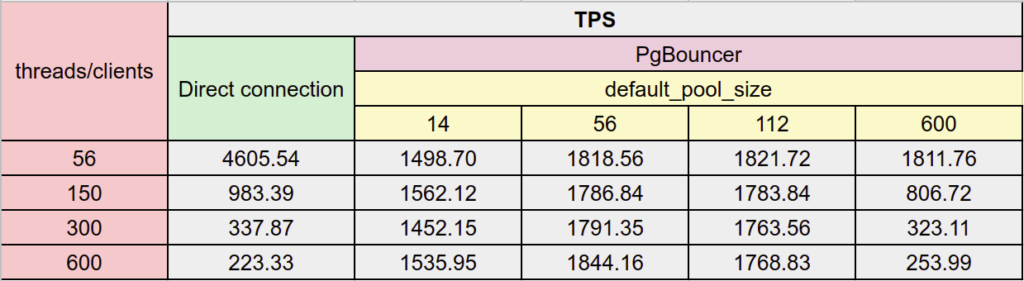
The need to couple PostgreSQL with a connection pooler depends on a number of factors including:
Unfortunately, I don’t have a formula for this. But now that you understand how a connection pooler such as PgBouncer works and where it tends to benefit PostgreSQL’s performance (even if only having sysbench-tpcc’s workload as the sole example here) it’s a matter of investigating the points above and experimenting. Experimenting is the key! Though possibly using reads only on a stand-by replica at first, to stay on the safe side…
In a future post, we will cover how the architecture of a database solution changes with the use of connection poolers: where to place them, how to cope with single point of failure issues and how they can be used alongside load balancers.
See why running open source PostgreSQL in-house demands more time, expertise, and resources than most teams expect — and what it means for IT and the business.
Resources
RELATED POSTS





Sorry, but I didn’t understand the cause of this bad performance with pgbouncer.
So, are you saying that for 56 direct PG threads/clients you got near 5k transaction per second (without using the conn pool) and for 600 PG threads/clients on pgbouncer (using a conn pool) you had less than 1k transaction per second?